



LangExtract ist eine von Google entwickelte Open-Source-Python-Bibliothek, die sich auf die Extraktion strukturierter Daten aus unstrukturiertem Text konzentriert. Sie nutzt groß angelegte Sprachmodelle (LLMs) wie das Google Gemini Die LangExtract-Reihe, die eine präzise Positionierung des Ausgangstextes und eine interaktive Visualisierung kombiniert, hilft dem Benutzer, komplexe Texte schnell in ein klares Datenformat umzuwandeln. LangExtract eignet sich besonders gut für die Arbeit mit langen Dokumenten, unterstützt die parallele Verarbeitung und mehrere Extraktionsrunden und wird häufig in Bereichen wie dem Gesundheitswesen und der Literaturanalyse eingesetzt. Das Tool ist unter der Apache 2.0-Lizenz veröffentlicht, und der Code wird auf GitHub mit offenen Beiträgen der Gemeinschaft gehostet.
Funktionsliste
- Unterstützung für mehrsprachige Modelle: kompatibel mit Google Gemini und anderen cloudbasierten Modellen und Ollama Lokale Modellierung mit flexibler Anpassung an die Bedürfnisse der Nutzer.
- Extraktion strukturierter Informationen: Extrahieren von Entitäten, Beziehungen und Attributen aus unstrukturiertem Text und Erzeugen von Ausgaben im JSONL-Format.
- Interaktive Visualisierung: Aus den Extraktionsergebnissen werden HTML-Visualisierungsdateien generiert, die es dem Benutzer ermöglichen, die extrahierten Entitäten auf einfache Weise anzuzeigen und zu analysieren.
- Verarbeitung langer Dokumente: Effiziente Verarbeitung sehr langer Texte, wie z. B. ganze Romane oder medizinische Berichte, durch intelligentes Chunking und parallele Verarbeitung.
- Maßgeschneiderte Extraktionsaufgaben: Definieren Sie schnell Extraktionsregeln, die auf bestimmte Bereiche anwendbar sind, mit Hilfe von Stichwörtern und einer kleinen Anzahl von Beispielen.
- Medizinische Textverarbeitung: Unterstützung bei der Extraktion von Medikamentennamen, Dosierungen und anderen Informationen aus klinischen Notizen für den medizinischen Bereich.
- API-Integration: Unterstützt Cloud-basierte Modell-API-Aufrufe und kann auch auf lokale Modellinferenz-Endpunkte von Drittanbietern erweitert werden.
Hilfe verwenden
Einbauverfahren
LangExtract ist in Python entwickelt und unterstützt moderne Python-Paketverwaltungsmethoden. Hier sind die detaillierten Installationsschritte:
- Code-Repository klonen
Öffnen Sie ein Terminal und führen Sie den folgenden Befehl aus, um das LangExtract-Repository zu klonen:git clone https://github.com/google/langextract.git cd langextract - Installation von Abhängigkeiten
Installieren Sie LangExtract mit pip. Der Entwicklungsmodus wird für die Änderung des Codes empfohlen:pip install -e .Installieren Sie zusätzliche Abhängigkeiten, wenn eine Entwicklungs- oder Testumgebung erforderlich ist:
pip install -e ".[dev]" # 包含 linting 工具 pip install -e ".[test]" # 包含 pytest 测试工具 - API-Schlüssel konfigurieren(z. B. mit Cloud-basierten Modellen)
Wenn Sie ein Cloud-Modell wie Google Gemini verwenden, müssen Sie den API-Schlüssel konfigurieren. Schreiben Sie den Schlüssel in die.envDokumentation:cat >> .env << 'EOF' LANGEXTRACT_API_KEY=your-api-key-here EOFUm den Schlüssel zu schützen, fügen Sie
.env到.gitignore:echo '.env' >> .gitignoreFür lokale Modelle (z. B. über Ollama) ist kein API-Schlüssel erforderlich.
- Überprüfen der Installation
Führen Sie den folgenden Befehl aus, um zu prüfen, ob die Installation erfolgreich war:python -c "import langextract; print(langextract.__version__)"
Verwendung
Die Kernfunktion von LangExtract besteht darin, strukturierte Daten aus einem Text zu extrahieren, und zwar durch Eingabeaufforderungen und Beispiele. Im Folgenden wird das Verfahren beschrieben:
1. die Extraktion von Basisinformationen
Angenommen, Sie möchten Zeichen, Emotionen und Beziehungen aus einem Text extrahieren, so lautet das Codebeispiel wie folgt:
import langextract as lx
import textwrap
# 定义提示词
prompt = textwrap.dedent("""
Extract characters, emotions, and relationships in order of appearance. Use exact text for extractions. Do not paraphrase or overlap entities.
""")
# 提供示例
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks?",
extractions=[
{"entity": "Romeo", "type": "character", "emotion": "hopeful"},
]
)
]
# 输入文本
text = "ROMEO. But soft! What light through yonder window breaks? It is Juliet."
# 执行提取
result = lx.extract(text, prompt=prompt, examples=examples, model="gemini-2.5-flash")
# 保存结果
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
Nach der Ausführung werden die Extraktionsergebnisse gespeichert als extraction_results.jsonl Datei, die die extrahierten Entitäten und ihre Attribute enthält.
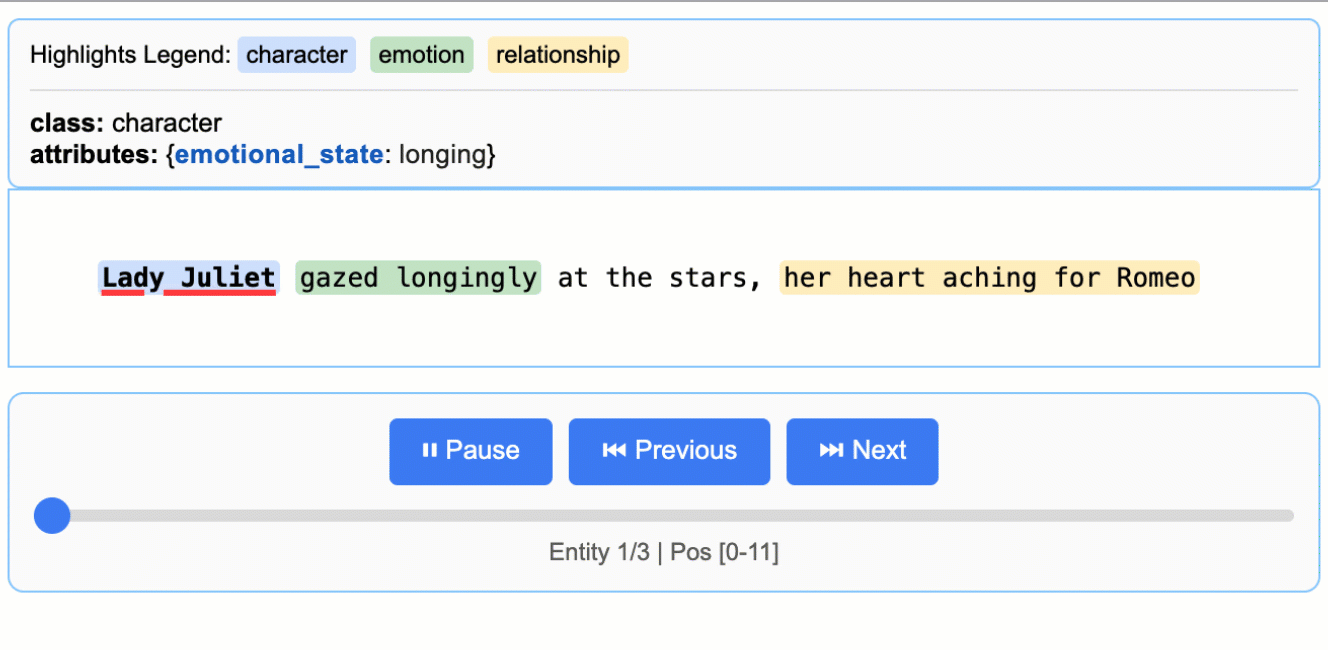
2. interaktive Visualisierungen generieren
LangExtract unterstützt die Erzeugung einer HTML-Visualisierung der Extraktionsergebnisse zur einfachen Anzeige:
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)
generiert visualization.html Die Datei kann in einem Browser geöffnet werden und zeigt die extrahierten Entitäten und ihren Kontext an.
3. der Umgang mit langen Dokumenten
Für lange Dokumente (wie z. B. das gesamte Buch Romeo und Julia) verwendet LangExtract intelligentes Chunking und Parallelverarbeitung:
url = "https://www.gutenberg.org/files/1513/1513.txt"
result = lx.extract_from_url(url, prompt=prompt, examples=examples, max_workers=4)
lx.io.save_annotated_documents([result], output_name="long_doc_results.jsonl")
max_workers steuert die Anzahl der Threads für die Parallelverarbeitung und ist für die Verarbeitung großer Dateien geeignet.
4. medizinische Textextraktion
LangExtract eignet sich hervorragend für den medizinischen Bereich und extrahiert Medikamentennamen, Dosierungen und andere Informationen. Beispiel:
prompt = "Extract medication names, dosages, and administration routes from clinical notes."
text = "Patient prescribed Metformin 500 mg orally twice daily."
result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro")
Die Ergebnisse enthalten extrahierte Arzneimittelinformationen wie z. B.:
{"entity": "Metformin", "dosage": "500 mg", "route": "orally"}
Featured Function Bedienung
- Auswahl des ModellsDie Standardeinstellung ist die Verwendung von
gemini-2.5-flashModelle mit ausgewogener Geschwindigkeit und Qualität. Für komplexe Aufgaben, wechseln Sie zugemini-2.5-pro:result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro") - Mehrkreis-ExtraktionVerbesserung der Genauigkeit durch Mehrfachextraktionen für komplexe Dokumente:
result = lx.extract(text, prompt=prompt, num_passes=2) - RadExtract-DemoLangExtract bietet eine Online-Demonstration von RadExtract, das auf radiologische Berichte spezialisiert ist. Besuchen Sie HuggingFace Spaces (
https://google-radextract.hf.space) können ohne Installation ausprobiert werden.
caveat
- Cloud-Modelle erfordern stabile API-Schlüssel und Netzverbindungen.
- Bei der Bearbeitung sehr langer Dokumente empfiehlt es sich, das Tier 2 Gemini-Kontingent zu nutzen, um eine Ratenbegrenzung zu vermeiden.
- Achten Sie beim Speichern des API-Schlüssels darauf, dass die
.envSicherheit der Dokumente.
Anwendungsszenario
- Medizinische Datenverarbeitung
Krankenhäuser und Forschungseinrichtungen können mit LangExtract Informationen wie Medikamente, Dosierungen, Diagnosen und mehr aus klinischen Notizen oder Radiologieberichten extrahieren. Radiologieberichte können beispielsweise in einem Format strukturiert werden, das Überschriften und Schlüsselelemente für eine einfache Datenanalyse und klinische Entscheidungsfindung enthält. - Literaturanalyse
Forscher können Charaktere, Emotionen und Beziehungen aus langen Werken der Literatur extrahieren. Zum Beispiel können sie die Interaktionen der Figuren in Romeo und Julia analysieren und Visualisierungen erstellen, um das Beziehungsgeflecht der Figuren zu untersuchen. - Extraktion von Business Intelligence
Unternehmen können Schlüsselbegriffe (z. B. Firmennamen, Produkte, Ereignisse) aus Nachrichten, Berichten oder sozialen Medien extrahieren, um Marktanalysen oder Wettbewerbsinformationen zu sammeln. - Rechtliche Dokumentation
Anwaltskanzleien können Klauseln, Daten, Parteien und andere Informationen aus Verträgen oder Rechtsdokumenten extrahieren, um schnell strukturierte Zusammenfassungen zu erstellen.
QA
- Ist LangExtract kostenlos?
LangExtract ist ein Open-Source-Tool und der Code kann kostenlos genutzt werden (Apache 2.0 Lizenz). Für die Nutzung eines Cloud-basierten Modells (z. B. Gemini) fällt jedoch eine API-Aufrufgebühr an. - Werden lokale Modelle unterstützt?
Unterstützt die Ausführung lokaler Open-Source-Modelle über Ollama ohne API-Schlüssel, geeignet für netzunabhängige Umgebungen. - Wie gehe ich mit sehr langen Dokumenten um?
Intelligentes Chunking und parallele Verarbeitung verwenden (Setup)max_workers), und es wird empfohlen, mehrere Extraktionen (Einstellungnum_passes), um die Genauigkeit zu verbessern. - Wie werden die Visualisierungsergebnisse angezeigt?
in Bewegung seinlx.visualizeGenerieren Sie HTML-Dateien, die in einem Browser geöffnet werden können, um die Extraktionsergebnisse interaktiv anzuzeigen. - Sind die medizinischen Anwendungen konform?
LangExtract ist nur ein Demonstrationswerkzeug, kein medizinisches Diagnosegerät. Gesundheitsbezogene Anwendungen unterliegen den Nutzungsbedingungen der Health AI Developer Foundations.





























