
Claude Code ist einer der angenehmsten KI-Agenten-Workflows, die es bisher gab. Nicht nur, dass er das gezielte Editieren von Code und die Entwicklung improvisierter Tools weniger lästig macht, die Erfahrung, ihn zu benutzen, wird sogar als ein Vergnügen an sich beschrieben. Er hat genug Autonomie, um interessante Aufgaben zu erledigen, ohne dass die Entwickler plötzlich...

Bei der Entwicklung von Wissensbasisanwendungen auf der Grundlage von Retrieval Augmented Generation (RAG) ist die Vorverarbeitung und das Slicing (Chunking) von Dokumenten ein entscheidender Schritt, um die endgültigen Suchergebnisse zu bestimmen. Die Open-Source-RAG-Engine RAGFlow bietet verschiedene Slicing-Strategien, aber der offiziellen Dokumentation fehlen klare Erklärungen zu den Details der Methode und zu speziellen Fällen, was bei Entwicklern zu großer Verwirrung führt...

Beim Aufbau von Retrieval Augmented Generation (RAG)-Systemen stoßen die Entwickler häufig auf folgende verwirrende Szenarien: Kopfzeilen von seitenübergreifenden Tabellen werden auf der vorherigen Seite belassen, wodurch die Daten an Relevanz verlieren. Modelle geben bei mehrdeutigen Scans sicher völlig falsche Inhalte an. Das Summensymbol “Σ” in einer mathematischen Formel wird fälschlicherweise als der Buchstabe “E” erkannt. Wasserzeichen in Dokumenten...

Beginnen wir mit einer einfachen Aufgabe: dem Planen einer Besprechung. Wenn ein Nutzer sagt: “Hey, können wir morgen eine schnelle Synchronisierung vornehmen?” Eine KI, die sich ausschließlich auf Prompt Engineering verlässt, könnte antworten: “Ja, morgen ist gut. Um wie viel Uhr möchten Sie die Synchronisierung bitte durchführen? Diese Antwort ist zwar korrekt, aber sie ist mechanisch und...

Abstrakt Das Aufkommen von groß angelegten Sprachmodellen (LLMs) hat ein neues Paradigma von Suchmaschinen eröffnet, die generative Modelle verwenden, um Informationen zu sammeln und zusammenzufassen, um Benutzeranfragen zu beantworten. Wir fassen diese aufkommende Technologie unter dem Begriff Generative Engines (GEs) zusammen, die genaue und personalisierte Antworten generieren und traditionelle Suchmaschinen wie Google und ...

In den Anfangstagen des Manus-Projekts stand das Team vor einer kritischen Entscheidung: Sollten sie ein End-to-End-Agentenmodell auf der Grundlage von Open-Source-Modellen trainieren oder sollten sie die leistungsstarken “Kontextlern”-Fähigkeiten modernster Modelle nutzen, um Agenten zu erstellen? Wenn man zehn Jahre zurückgeht, hatten Entwickler im Bereich der Verarbeitung natürlicher Sprache nicht einmal eine Wahl. In der Ära von BERT konnte jedes Modell...

Bei der Entwicklung von KI-Systemen wie RAGs oder KI-Agenten ist die Qualität der Abfrage der Schlüssel zur Bestimmung der Obergrenze des Systems. Die Entwickler stützen sich in der Regel auf zwei wichtige Suchtechniken: die Schlagwortsuche und die semantische Suche. Schlüsselwortsuche (z.B. BM25): schnell und gut im exakten Abgleich. Sobald sich jedoch der Wortlaut der Frage eines Benutzers ändert, sinkt die Auffindungsrate. ...

Die Erfahrung, mit einem Freund zu kommunizieren, der immer den Inhalt des Gesprächs vergisst und jedes Mal wieder von vorne anfangen muss, ist zweifellos ineffizient und anstrengend. Doch genau das ist die Norm für die meisten aktuellen KI-Systeme. Sie sind zwar leistungsfähig, aber es fehlt ihnen in der Regel eine wichtige Komponente: das Gedächtnis. Um KI-Intelligenzen (Agenten) zu entwickeln, die wirklich lernen, sich weiterentwickeln und zusammenarbeiten können, ist das Gedächtnis nicht...

Von API-Aufrufen für große Sprachmodelle (Large Language Models, LLMs) bis hin zu autonomen, zielgerichteten agentengesteuerten Workflows vollzieht sich ein grundlegender Paradigmenwechsel bei KI-Anwendungen. Die Open-Source-Gemeinschaft hat bei dieser Welle eine Schlüsselrolle gespielt und eine Fülle von KI-Tools hervorgebracht, die sich auf spezifische Forschungsaufgaben konzentrieren. Diese Werkzeuge ...

Erfahren Sie alles über Reinforcement Learning (RL) und wie Sie Ihr eigenes DeepSeek-R1-Inferenzmodell mit Unsloth und GRPO trainieren können. Ein kompletter Leitfaden vom Anfänger bis zum Meister. 🦥 Was Sie lernen werden Was ist RL? RLVR? PPO? GRPO? RLHF? RFT?...

Mit der raschen Entwicklung und breiten Anwendung von Technologien zur Sprachmodellierung in großem Maßstab rücken deren potenzielle Sicherheitsrisiken zunehmend in den Mittelpunkt des Interesses der Industrie. Um diesen Herausforderungen zu begegnen, haben viele der weltweit führenden Technologieunternehmen, Standardisierungsorganisationen und Forschungsinstitute eigene Sicherheitsrahmenwerke entwickelt und veröffentlicht. In diesem Papier werden neun repräsentative Sicherheitsrahmen für große Modelle analysiert, um einen umfassenden Überblick über die damit verbundenen Bereiche zu geben...
Im Bereich der Large Language Modelling (LLM)-Forschung ist die Leap-of-Thought-Fähigkeit des Modells, d.h. die Kreativität, nicht weniger wichtig als die Fähigkeit zum logischen Denken, die durch die Chain-of-Thought repräsentiert wird. Es gibt jedoch immer noch einen relativen Mangel an eingehenden Diskussionen und validen Bewertungsmethoden für die LLM-Kreativität, die in ...
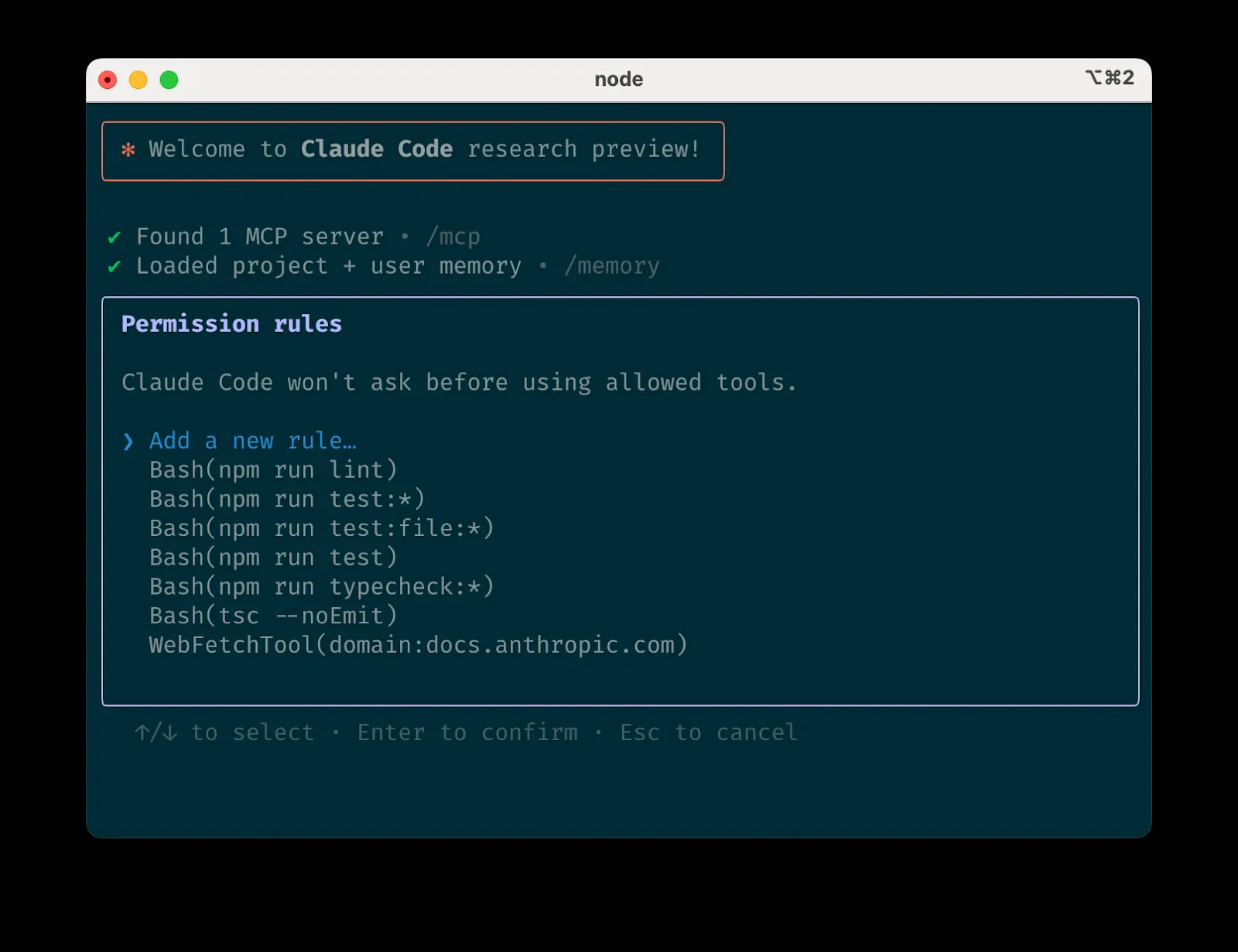
Claude Code meistern: Praktische Tipps für Agentic Coding aus erster Hand Claude Code ist ein Kommandozeilenwerkzeug für Agentic Coding. Mit "Agentic Coding" meinen wir, der KI ein gewisses Maß an Autonomie zu geben, die Fähigkeit, Aufgaben zu verstehen, Schritte zu planen und Aktionen durchzuführen (wie...

Die GPT-4.1-Modellfamilie bietet im Vergleich zu GPT-4o erhebliche Verbesserungen bei der Codierung, der Befolgung von Anweisungen und der Verarbeitung langer Kontexte. Insbesondere ist die Leistung bei der Codegenerierung und bei Reparaturaufgaben besser, das Verständnis und die Ausführung komplexer Anweisungen sind genauer, und längere Eingabetexte können effizient verarbeitet werden. Dieser technische Leitfaden bringt OpenAI zusammen ...
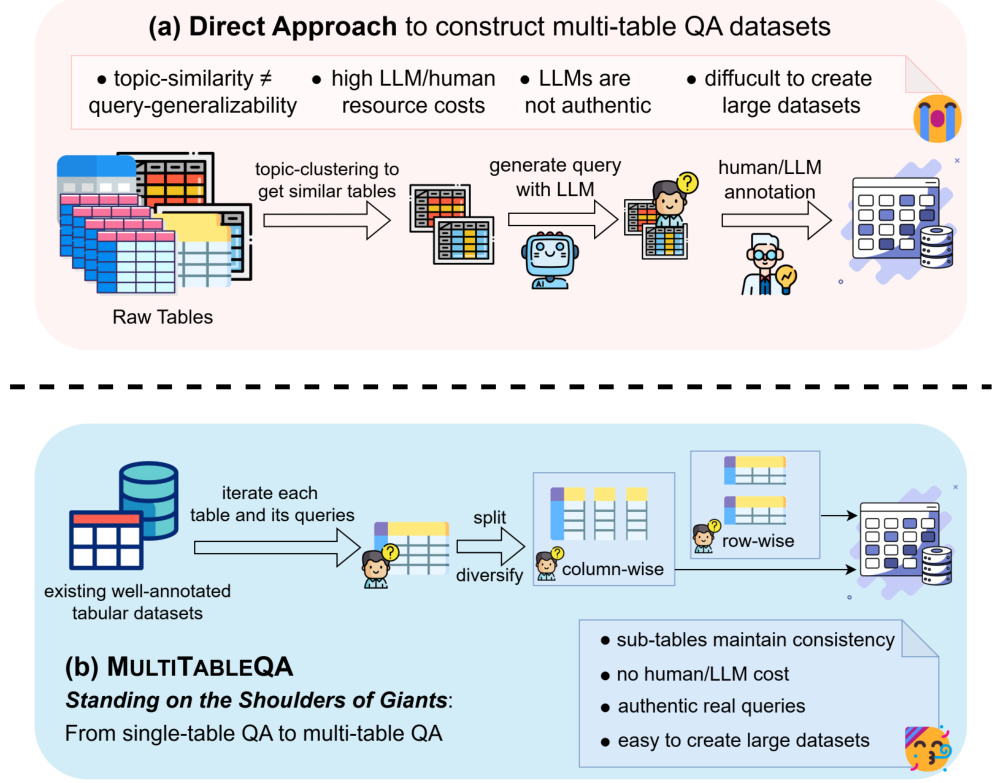
1 EINLEITUNG In der heutigen Informationsexplosion wird eine große Menge an Wissen in Form von Tabellen in Webseiten, Wikipedia und relationalen Datenbanken gespeichert. Herkömmliche Frage-Antwort-Systeme haben jedoch oft Schwierigkeiten, komplexe Abfragen über mehrere Tabellen hinweg zu bearbeiten, was zu einer großen Herausforderung im Bereich der künstlichen Intelligenz geworden ist. Um diese Herausforderung zu bewältigen, haben Forscher das GTR (Graph-Table ...
Da sich die Fähigkeiten von Large Language Models (LLMs) rasch weiterentwickeln, stoßen traditionelle Benchmark-Tests wie MMLU bei der Unterscheidung von Spitzenmodellen an ihre Grenzen. Es ist nicht mehr möglich, sich ausschließlich auf Wissensquizze oder standardisierte Tests zu verlassen, um die nuancierten Fähigkeiten umfassend zu messen, die für Modelle in realen Interaktionen entscheidend sind, wie z. B. emotionale Intelligenz, Kreativität, Urteilsvermögen und Kommunikationsfähigkeiten. In diesem Sinne ...

Die Entwicklung von Large Language Models (LLMs) schreitet rasch voran, und ihre Denkfähigkeit ist zu einem Schlüsselindikator für ihren Intelligenzgrad geworden. Insbesondere Modelle mit langen Denkfähigkeiten wie o1, DeepSeek-R1, QwQ-32B und Kimi K1.5 von OpenAI, die den menschlichen Denkprozess durch das Lösen zusammengesetzter Aufgaben simulieren,...
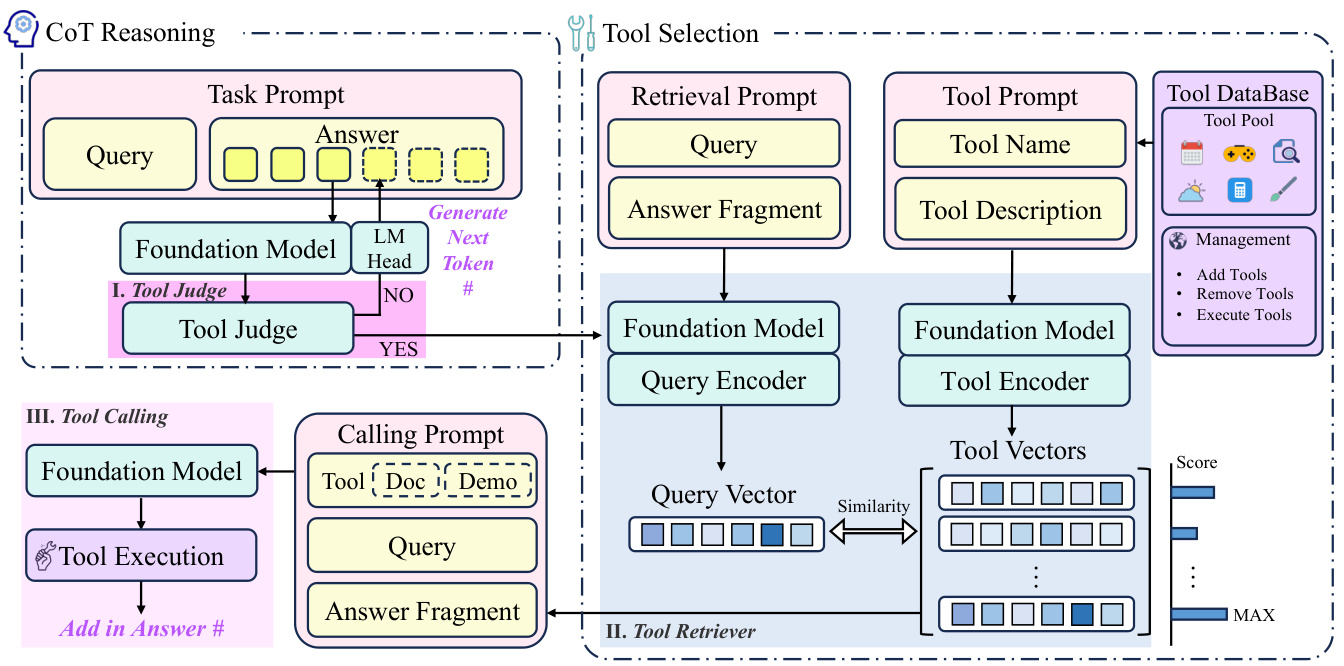
EINLEITUNG In den letzten Jahren haben große Sprachmodelle (Large Language Models, LLMs) beeindruckende Fortschritte im Bereich der Künstlichen Intelligenz (KI) gemacht, und ihre leistungsstarken Sprachverstehens- und -generierungsfähigkeiten haben zu einem breiten Spektrum von Anwendungen in verschiedenen Bereichen geführt. LLMs stehen jedoch immer noch vor vielen Herausforderungen, wenn es um komplexe Aufgaben geht, die den Aufruf externer Tools erfordern. Wenn ein Benutzer beispielsweise fragt: “Wie wird das Wetter morgen an meinem Zielort sein...
Im Python-Ökosystem gab es schon immer einen Mangel an Werkzeugen für die Paket- und Umgebungsverwaltung, von den klassischen pip und virtualenv über pip-tools und conda bis hin zu den modernen Poetry und PDM. Jedes Tool hat sein eigenes Fachgebiet, aber sie machen die Toolchain eines Entwicklers oft fragmentiert und komplex. Jetzt, ...
zurück zum Anfang

