



Kitten-TTS-Server ist ein Open-Source-Projekt, das eine leichtgewichtige KittenTTS Das Modell bietet einen Server mit erweiterter Funktionalität. Benutzer können mit diesem Projekt selbst einen Text-to-Speech-Dienst (TTS) aufbauen. Die Hauptstärken dieses Projekts liegen darin, dass es auf dem ursprünglichen Modell aufbaut, indem es eine intuitive Web-Benutzeroberfläche, Langtextverarbeitung für Hörbücher und GPU-Beschleunigung für erhebliche Leistungssteigerungen hinzufügt. Das dem Server zugrunde liegende Modell ist sehr klein - weniger als 25 MB -, erzeugt aber realistische und natürlich klingende menschliche Stimmen. Das Projekt hat den Prozess der Installation und des Betriebs des Modells vereinfacht, indem es einen voll funktionsfähigen Server bereitstellt, der auch für Benutzer ohne Fachkenntnisse leicht zu bedienen ist. Der Server verfügt über 8 integrierte voreingestellte Stimmen (4 männliche, 4 weibliche) und unterstützt die Bereitstellung über Docker, wodurch die Komplexität der Konfiguration und Wartung erheblich reduziert wird.
Funktionsliste
- leichtes ModellDer Kern verwendet das KittenTTS ONNX-Modell, das weniger als 25 MB groß ist und nur wenige Ressourcen benötigt.
- GPU-Beschleunigung: durch optimierte
onnxruntime-gpuPipeline- und I/O-Bindungstechnologie mit voller Unterstützung für NVIDIA (CUDA)-Beschleunigung für eine deutlich schnellere Spracherzeugung. - Erstellung von Langtexten und HörbüchernDie Fähigkeit, lange Texte automatisch zu verarbeiten, indem Sätze intelligent gebrochen, in Abschnitte zerlegt und dann nahtlos zusammengefügt werden, ist ideal für die Erstellung vollständiger Hörbücher.
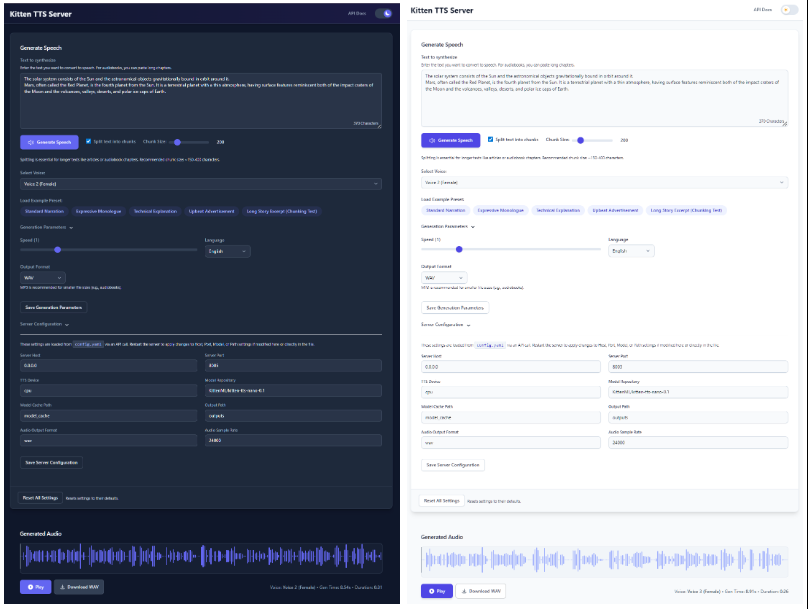
- Modernisierte WebschnittstelleDie Web-UI bietet eine intuitive Weboberfläche, die es dem Benutzer ermöglicht, Text einzugeben, Sprache auszuwählen, die Sprechgeschwindigkeit einzustellen und die Wellenformen der erzeugten Audiosignale in Echtzeit zu sehen, alles direkt im Browser.
- Eingebaute MehrfachstimmenKittenTTS: Integriert die 8 Stimmen (4 männliche und 4 weibliche) des KittenTTS-Modells, die direkt über die Schnittstelle ausgewählt werden können.
- Duale API-Schnittstelle: Bietet eine voll funktionsfähige
/ttsSchnittstelle und eine OpenAI TTS API-Struktur, die mit der/v1/audio/speechSchnittstellen für eine einfache Integration in bestehende Arbeitsabläufe. - Einfache KonfigurationAlle Einstellungen werden über eine einzige
config.yamlDie Dokumentation wird verwaltet. - ZustandsspeicherDie Webschnittstelle merkt sich die zuletzt verwendeten Text-, Sprach- und zugehörigen Einstellungen, um die Bedienung zu vereinfachen.
- Docker-UnterstützungDocker Compose: Stellt vorkonfigurierte Docker Compose-Dateien für CPU- und GPU-Umgebungen zur Verfügung und ermöglicht die Bereitstellung von Containern mit einem Klick.
Hilfe verwenden
Das Kitten-TTS-Server-Projekt bietet einen klaren Installations- und Nutzungsprozess, um sicherzustellen, dass die Benutzer es ohne Probleme auf ihrer eigenen Hardware zum Laufen bringen können.
Vorbereitung der Systemumgebung
Vor der Installation müssen Sie die folgende Umgebung vorbereiten:
- BetriebssystemWindows 10/11 (64-bit) oder Linux (Debian/Ubuntu empfohlen).
- Python3.10 oder höher.
- GitKlonen: Dient zum Klonen von Projektcode von GitHub.
- eSpeak NGDies ist eine erforderliche Abhängigkeit für die Phonetisierung von Texten.
- WindowsDownload und Installation von der eSpeak NG Release-Seite
espeak-ng-X.XX-x64.msi. Das Kommandozeilenterminal muss nach der Installation neu gestartet werden. - Linux: Führen Sie den Befehl im Terminal aus
sudo apt install espeak-ng。
- WindowsDownload und Installation von der eSpeak NG Release-Seite
- (GPU-Beschleunigung optional):
- Eine CUDA-fähige NVIDIA-Grafikkarte.
- (nur Linux): erfordert die Installation von
libsndfile1和ffmpeg. Dies kann mit dem Befehlsudo apt install libsndfile1 ffmpegzu installieren.
Installationsschritte
Der gesamte Installationsprozess ist so konzipiert, dass er mit nur einem Mausklick durchgeführt werden kann, wobei die Installationspfade je nach Ihrer Hardware unterschiedlich sind.
Schritt 1: Klonen des Code-Repositorys
Öffnen Sie Ihr Terminal (PowerShell unter Windows, Bash unter Linux) und führen Sie den folgenden Befehl aus:
git clone https://github.com/devnen/Kitten-TTS-Server.git
cd Kitten-TTS-Server
Schritt 2: Erstellen und Aktivieren einer virtuellen Python-Umgebung
Um Konflikte mit abhängigen Bibliotheken aus anderen Projekten zu vermeiden, ist es sehr empfehlenswert, eine separate virtuelle Umgebung zu erstellen.
- Windows (PowerShell):
python -m venv venv .\venv\Scripts\activate - Linux (Bash):
python3 -m venv venv source venv/bin/activate
Nach erfolgreicher Aktivierung wird der Befehlszeilenaufforderung Folgendes vorangestellt (venv) Worte.
Schritt 3: Python-Abhängigkeiten installieren
Je nachdem, ob Ihr Computer mit einer NVIDIA-Grafikkarte ausgestattet ist oder nicht, wählen Sie eine der folgenden Methoden für die Installation.
- Option 1: Nur-CPU-Installation (am einfachsten)
Dies gilt für alle Computer.pip install --upgrade pip pip install -r requirements.txt - Option 2: Installation mit NVIDIA-GPU (mehr Leistung)
Bei diesem Ansatz werden alle erforderlichen CUDA-Bibliotheken installiert, damit das Programm auf der Grafikkarte ausgeführt werden kann.pip install --upgrade pip # 安装支持GPU的ONNX Runtime pip install onnxruntime-gpu # 安装支持CUDA的PyTorch,它会一并安装onnxruntime-gpu所需的驱动文件 pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu121 # 安装其余的依赖 pip install -r requirements-nvidia.txtSobald die Installation abgeschlossen ist, können Sie den folgenden Befehl ausführen, um zu überprüfen, ob PyTorch Ihre Grafikkarte korrekt erkennt:
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}')"Wenn die Ausgabe
CUDA available: TrueIm Folgenden finden Sie ein Beispiel für eine erfolgreiche Konfiguration der GPU-Umgebung.
Operationsserver
zur Kenntnis nehmenWenn Sie den Server zum ersten Mal starten, wird er automatisch die KittenTTS-Modelldatei von Hugging Face herunterladen, die etwa 25 MB groß ist. Dieser Vorgang muss nur einmal durchgeführt werden und die folgenden Starts sind sehr schnell.
- Stellen Sie sicher, dass Sie die virtuelle Umgebung aktiviert haben (Befehlszeile mit vorangestelltem
(venv))。 - Starten Sie den Server in einem Terminal:
python server.py - Beim Start des Servers wird automatisch die Webschnittstelle in Ihrem Standardbrowser geöffnet.
- Adresse der Webschnittstelle.
http://localhost:8005 - Adresse der API-Dokumentation.
http://localhost:8005/docs
- Adresse der Webschnittstelle.
Um den Server zu stoppen, drücken Sie einfach in dem Terminalfenster, in dem der Server läuft CTRL+C。
Docker-Installationsmethoden
Wenn Sie mit Docker vertraut sind, können Sie Docker Compose für die Bereitstellung verwenden, was einfacher ist und eine bessere Verwaltung der Anwendung ermöglicht.
- Vorbereitung der Umwelt:
- Installieren Sie Docker und Docker Compose.
- (GPU-Benutzer) Installieren Sie NVIDIA Container Toolkit.
- Code-Repository klonen (Falls noch nicht geschehen).
git clone https://github.com/devnen/Kitten-TTS-Server.git cd Kitten-TTS-Server - Start-Container (Wählen Sie die Befehle entsprechend Ihrer Hardware).
- NVIDIA GPU-Benutzer:
docker compose up -d --build - Nur CPU-Benutzer:
docker compose -f docker-compose-cpu.yml up -d --build
- NVIDIA GPU-Benutzer:
- Zugang und Verwaltung:
- Web-Schnittstelle.
http://localhost:8005 - Journal ansehen.
docker compose logs -f - Behälter stoppen.
docker compose down
- Web-Schnittstelle.
Funktion Betrieb
- Normale Sprache generieren:
- Starten Sie den Server und öffnen Sie die
http://localhost:8005。 - Geben Sie den Text, den Sie umwandeln möchten, in das Textfeld ein.
- Wählen Sie einen Lieblingston aus dem Dropdown-Menü.
- Sie können den Schieberegler ziehen, um die Geschwindigkeit der Sprache anzupassen.
- Klicken Sie auf die Schaltfläche "Generate Speech", und die Audiodatei wird automatisch mit einem Download-Link abgespielt.
- Starten Sie den Server und öffnen Sie die
- Erzeugen von Hörbüchern:
- Kopieren Sie das gesamte Buch oder ein Kapitel im Klartext.
- Fügen Sie ihn in das Textfeld auf der Webseite ein.
- Vergewissern Sie sich, dass die Option "Text in Abschnitte aufteilen" aktiviert ist.
- Um die Pausen natürlicher zu gestalten, empfiehlt es sich, eine Stückgröße zwischen 300 und 500 Zeichen festzulegen.
- Klicken Sie auf die Schaltfläche "Sprache generieren". Der Server schneidet den langen Text automatisch in Scheiben, generiert Sprache und fügt sie schließlich zu einer vollständigen Audiodatei zusammen, die Sie herunterladen können.
Anwendungsszenario
- Produktion von Hörbüchern
Nutzer oder Autoren von Inhalten, die sich gerne Bücher anhören, können mit diesem Tool eBooks, lange Artikel oder Webromane in Hörbücher umwandeln. Seine Funktion zur Verarbeitung langer Texte kann automatisch das Zerschneiden und Zusammenfügen übernehmen, um vollständige Audiodateien zu erzeugen. - Persönliche Sprachassistenten
Entwickler können die APIs in ihre Anwendungen integrieren, um Sprachansagen in ihre Anwendungen zu integrieren, z. B. das Vorlesen von Nachrichten, Wettervorhersagen oder Benachrichtigungen. - Vertonung von Videoinhalten
Medienschaffende können damit bei der Erstellung von Videos ein Voice-over oder einen Kommentar erstellen. Das ist effizienter und kostengünstiger als Live-Aufnahmen, und Sie können den Text jederzeit ändern und das Voiceover neu generieren. - Lernhilfen
Die Lernenden können Wörter oder Sätze eingeben und eine standardisierte Aussprache erzeugen, die sie nachsprechen können. Die Lernmaterialien können auch in Audiodateien umgewandelt werden, um sie während des Pendelns oder beim Sport anzuhören.
QA
- Wie unterscheidet sich dieses Projekt von der direkten Verwendung des KittenTTS-Modells?
Dieses Projekt ist ein "gewarteter" Wrapper um das KittenTTS-Modell, der die Probleme der komplexen Umgebungskonfiguration, der fehlenden Benutzeroberfläche, der Unfähigkeit, lange Texte zu verarbeiten, und der fehlenden GPU-Beschleunigung bei direkter Verwendung des Modells löst. Er löst die Probleme der komplexen Umgebungskonfiguration, der fehlenden Benutzeroberfläche, der Unfähigkeit, lange Texte zu verarbeiten, und der fehlenden Unterstützung für GPU-Beschleunigung, wenn das Modell direkt verwendet wird.Kitten-TTS-Server bietet eine sofort einsatzbereite Webschnittstelle und API-Dienste, so dass es für den durchschnittlichen Benutzer einfach zu verwenden ist. - Was soll ich tun, wenn bei der Installation von eSpeak Fehler auftreten?
Dies ist das häufigste Problem. Bitte stellen Sie sicher, dass Sie eSpeak NG korrekt für Ihr Betriebssystem installiert haben und dass Sie das Kommandozeilenterminal nach der Installation neu gestartet haben. Wenn das Problem weiterhin besteht, überprüfen Sie, ob eSpeak NG in einem Standardpfad auf Ihrem System installiert ist. - Wie bestätige ich, dass die GPU-Beschleunigung wirksam ist?
Vergewissern Sie sich zunächst, dass Sie alle Abhängigkeiten so installiert haben, wie sie für NVIDIA-GPUs vorgesehen sind. Dann können Siepython -c "import torch; print(torch.cuda.is_available())"Befehl, wenn er Folgendes zurückgibtTrueund zeigt damit an, dass die Umgebung korrekt konfiguriert ist. Während der Server läuft, können Sie die Umgebung auch über den Task-Manager oder dienvidia-smium die GPU-Nutzung anzuzeigen. - Was sollte ich tun, wenn der Server mit der Meldung "Der Port ist belegt" startet?
Das bedeutet, dass es auf Ihrem Computer bereits andere Programme gibt, die den Port 8005 belegen. Sie können denconfig.yamlDatei, dieserver.portauf eine andere, nicht belegte Anschlussnummer (z. B.8006), und starten Sie dann den Server neu.



























