
Veröffentlichungsregeln werden verwendet, um die Generierung von Artikelthemen (Titeln) zu automatisieren und um während der Generierungsphase der Artikel kontextbezogene Hinweise zu geben. Um die Veröffentlichungsregeln festzulegen und die Themen entsprechend den tatsächlichen Optimierungszielen der Website zu generieren, sollten sie nicht blind verwendet werden, und es wird empfohlen, sie in der Anfangsphase in kleinem Maßstab zu testen, um zu beobachten, ob die generierten Themen den Erwartungen entsprechen. Der Hauptarbeitsablauf des Plug-ins: Konfiguration der Veröffentlichungsregeln - Auswahl der Veröffentlichungsregeln, um die Hauptthemen zu generieren...

1.1 Konfigurieren Sie zunächst die API, die zur Generierung von Artikeln verwendet wird. Die in der benutzerdefinierten API-Konfiguration hinzugefügte, vorgefertigte API-Konfiguration wird verwendet, um Textinhalte wie Themen, Artikel, Artikelstruktur usw. zu generieren. 1.1 Unterstützung der Verwendung von benutzerdefinierten APIs, die mit dem OPENAI-Format kompatibel sind Vergessen Sie nicht, den Abschnitt /v1/chat/completions auszufüllen...

1. von der Erstellung einfacher Regeln zum Start Die Erstellung von Regeln für die Erstellung des Themas (Artikeltitel) vor der Erstellung von Materialien, ist der Ausgangspunkt des gesamten Artikelerstellungsprozesses. Hier verwende ich den einfachsten Regeltyp “zufällige Kategorie”, um eine Regel zu erstellen. Erläuterung der folgenden Konfiguration: zufällige Verwendung von 10 Kategorien von Namen und Beschreibungen, die zur Erstellung des Themas (Artikeltitel) verwendet werden ...

1.Betriebsrichtlinien 1.1 Mehrsprachige Auswahl Gilt nur für die mehrsprachige Auswahl von Kanälen in der Abbildung 1.2 Tipps zum Keyword Mining auf Chinesisch Es wird empfohlen, nur Google und Baidu auszuwählen Für Keywords, die eine Mischung aus Chinesisch und Englisch beinhalten, wird empfohlen, Englisch in Kleinbuchstaben zu verwenden und mehrere Wörter durch Leerzeichen zu trennen Tipps zur Keyword-Expansion: Verwenden Sie ein großes Modell, um das Basiswort zu erhalten - Verwenden Sie das Keyword-Tool ...

0. erforderlich: muss vollständig und detailliert Konfiguration der Website-Klassifizierung Klassifizierung Name, Alias (Englisch), Beschreibung, muss detailliert sein. AI Content Manager verlässt sich stark auf die Klassifizierung Name und detaillierte Beschreibung der Klassifizierung, um die Richtung der generierten Inhalte zu steuern und automatisch die entsprechende Klassifizierung auswählen. Nachdem Sie die Kategorien eingerichtet haben, klicken Sie bitte einmal auf die Schaltfläche Refresh Category Cache auf der Dashboard-Seite innerhalb des Plugins...

Dies ist AI Content Generation Manager, exklusives Thema, kann nicht direkt diese Vorlage verwenden. Nach der Aktivierung befinden sich alle zugehörigen Einstellungen in den “Theme Settings”. 1. sekundären Domain-Namen-Zugang aktivieren Was ist der Fall für die Aktivierung sekundären Domain-Namen-Zugang? Sie haben bereits eine Website, möchten das Gewicht der Hauptseite erhöhen, Besucher anziehen oder eine individuelle Suchmaschinenoptimierung durchführen. Öffnen Sie ...
Nun, zu diesem Zeitpunkt haben wir über 1000 Zeilen in unserer Markdown-Datei. Das hier ist hauptsächlich zum Spaß.
Wenn Sie auf eine Einführung in humanlayer gewartet haben, dann ist dies die richtige. Wenn Sie Element 6 - Starten/Pausieren/Fortsetzen über eine einfache API und Element 7 - Kontaktaufnahme mit Menschen über Tool-Aufrufe praktizieren, dann sind Sie bereit, dieses Element zu integrieren. Erlauben Sie dem Benutzer das Starten/Pausieren/Fortsetzen von...
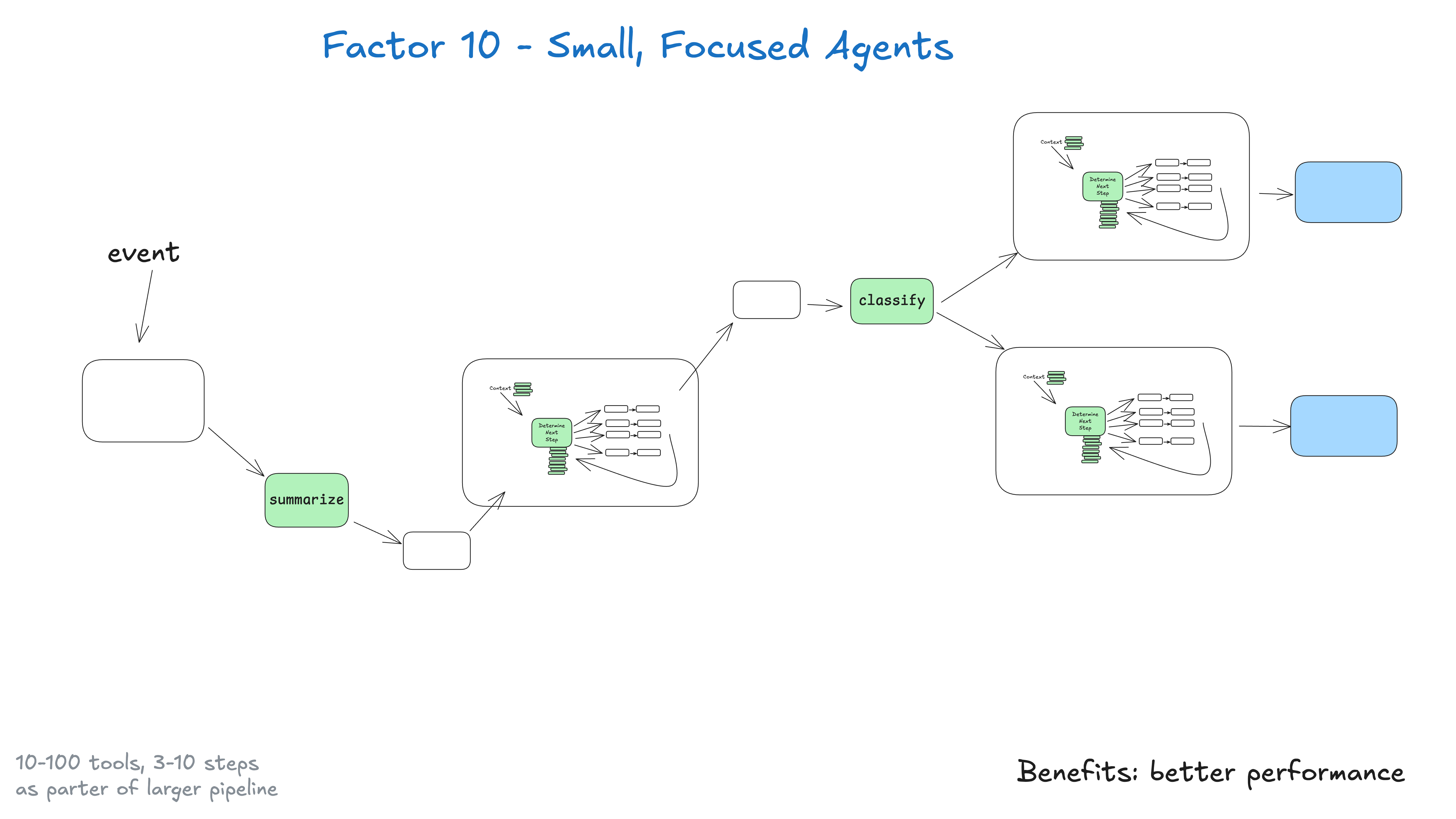
Anstatt monolithische Intelligenzen zu bauen, die versuchen, alles zu tun, ist es besser, kleine, konzentrierte Intelligenzen zu bauen, die eine Sache gut machen können. Intelligenzen sind nur ein Baustein in einem größeren, weitgehend deterministischen System. Die wichtigste Erkenntnis liegt hier in den Grenzen großer Sprachmodelle: Je größer und komplexer die Aufgabe ist, desto mehr Schritte sind erforderlich, was längere Kontextfenster bedeutet...
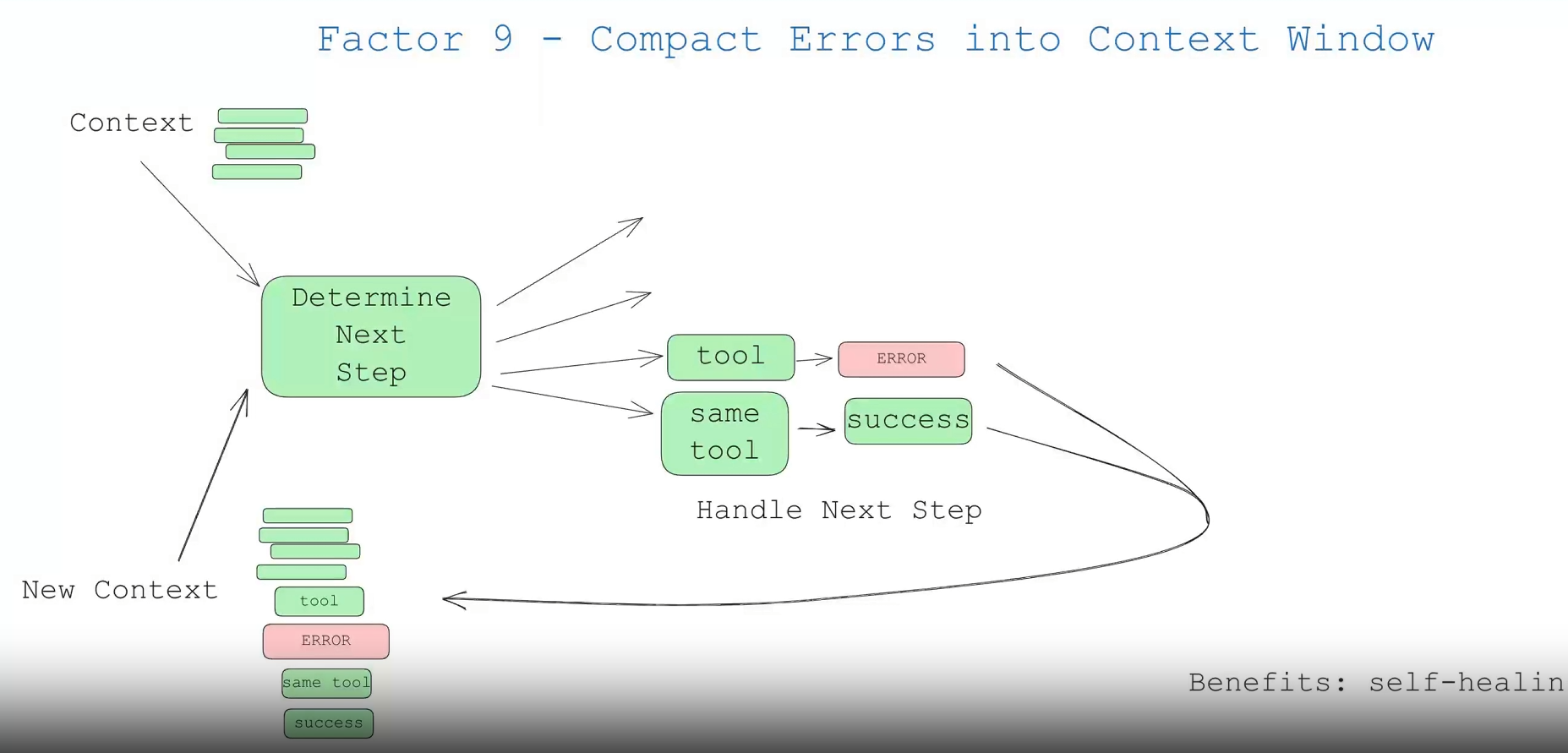
Dies ist ein unbedeutender Punkt, aber erwähnenswert. Einer der Vorteile eines Agenten ist die “Selbstheilung” - für eine kurze Aufgabe kann ein großes Sprachmodell (LLM) ein fehlgeschlagenes Tool aufrufen. Es besteht eine gute Chance, dass ein gutes LLM in der Lage ist, eine Fehlermeldung oder einen Stack-Trace zu lesen und herauszufinden, was danach zu tun ist...
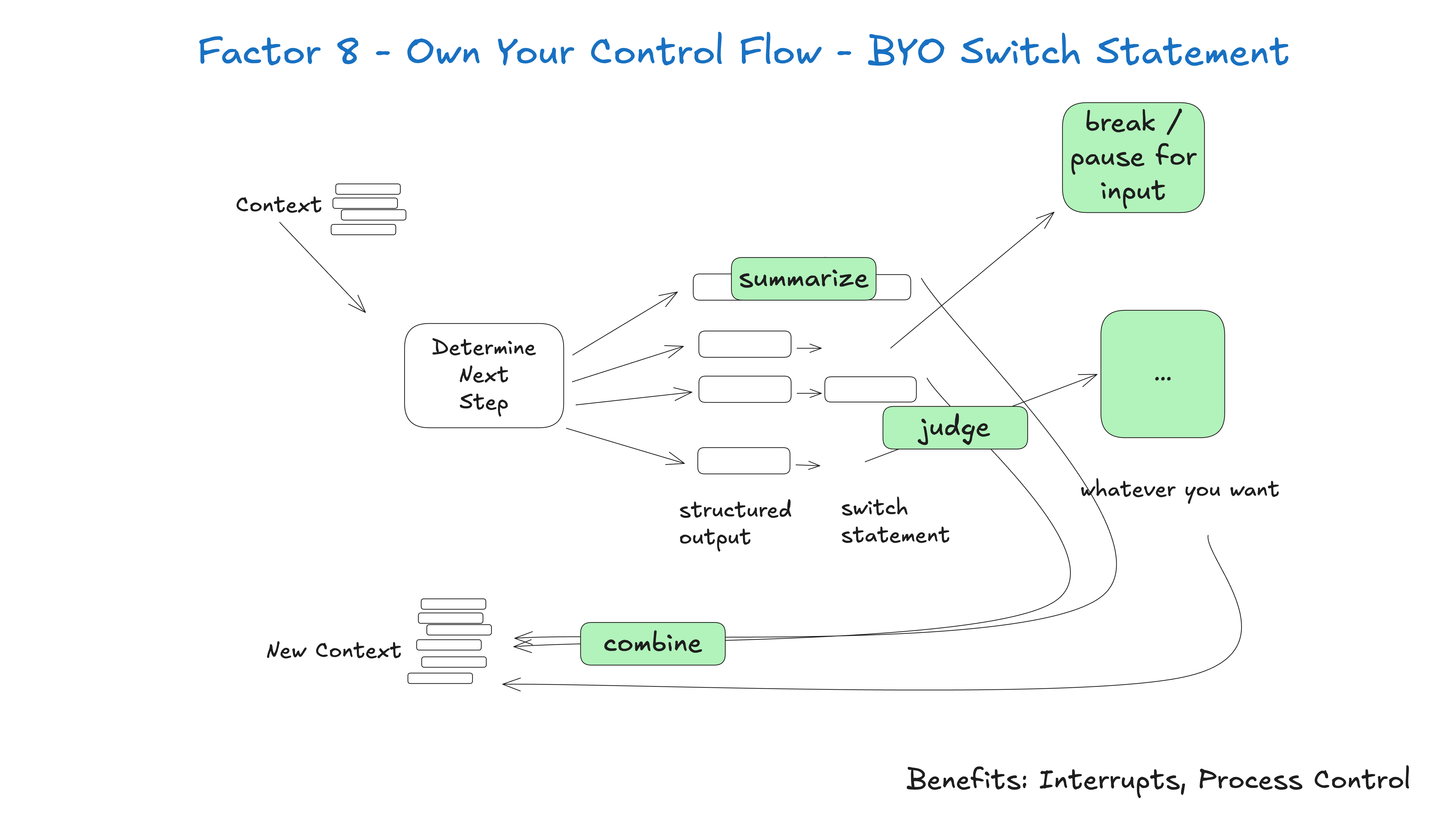
Wenn Sie die Kontrolle über Ihren eigenen Kontrollfluss haben, können Sie viele interessante Funktionen implementieren. Erstellen Sie benutzerdefinierte Kontrollstrukturen, die zu Ihrem speziellen Anwendungsfall passen. Bestimmte Arten von Toolaufrufen könnten ein Grund sein, aus einer Schleife herauszuspringen, auf die Antwort eines Menschen zu warten oder auf eine andere lang laufende Aufgabe zu warten (z. B. eine Schulungspipeline). Möglicherweise möchten Sie auch benutzerdefinierte Implementierungen der folgenden Funktionen integrieren: ...

Standardmäßig beruht die API des Large Language Model (LLM) auf einer grundlegend wichtigen Token-Entscheidung: Geben wir reinen Textinhalt oder strukturierte Daten zurück? Sie legen viel Gewicht auf die erste Token-Wahl, die im Fall des Wetters in Tokio...
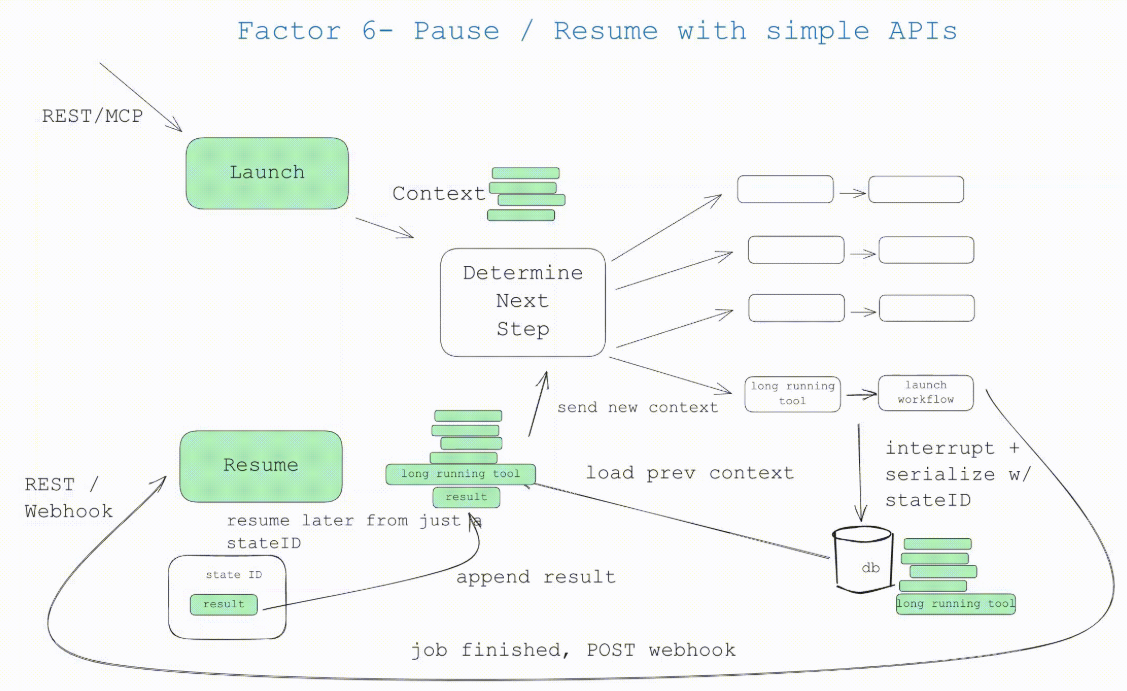
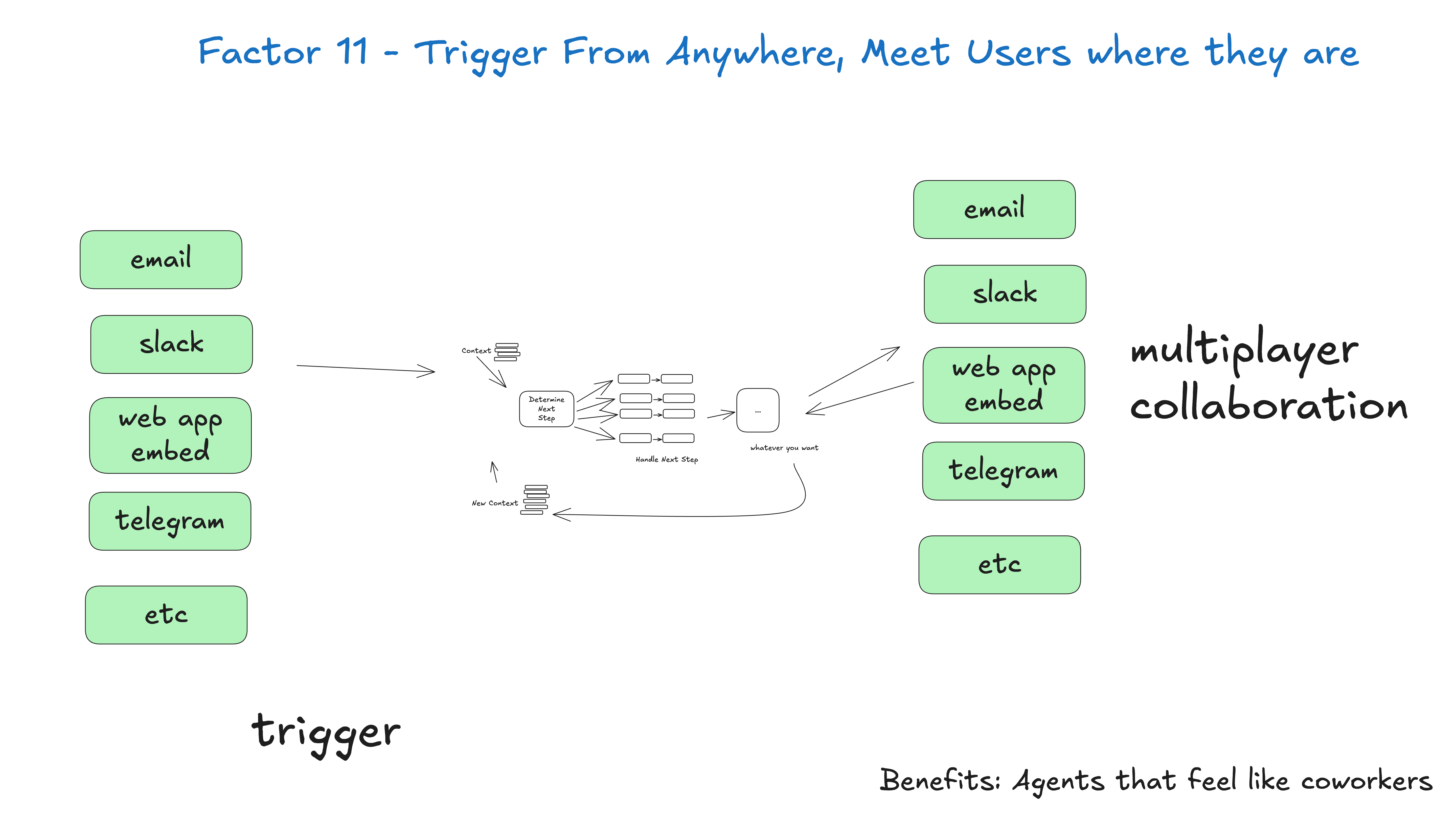
Intelligenzen sind Programme, und wir erwarten, dass man sie auf irgendeine Weise starten, abfragen, fortsetzen und beenden kann. Nutzer, Anwendungen, Pipelines und andere Intelligenzen sollten in der Lage sein, eine Intelligenz über eine einfache API zu starten. Intelligenzen und ihr deterministischer Orchestrierungscode sollten in der Lage sein, die Intelligenz anzuhalten, wenn eine lang andauernde Operation durchgeführt werden muss. Intelligenzen wie Webh...
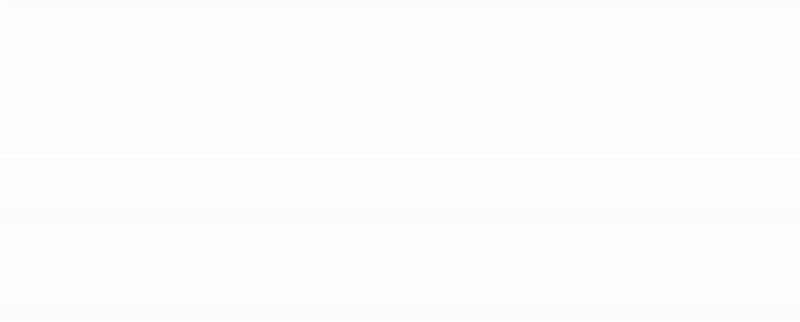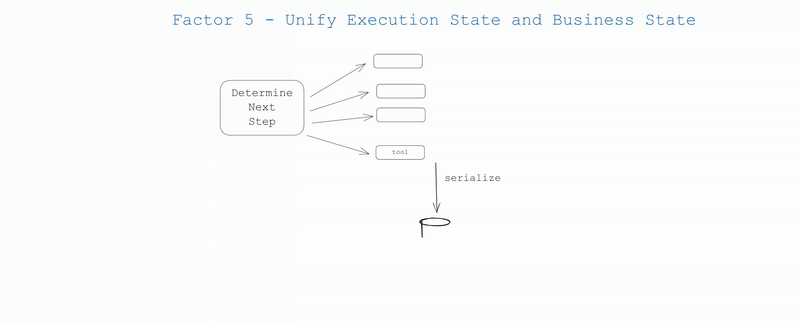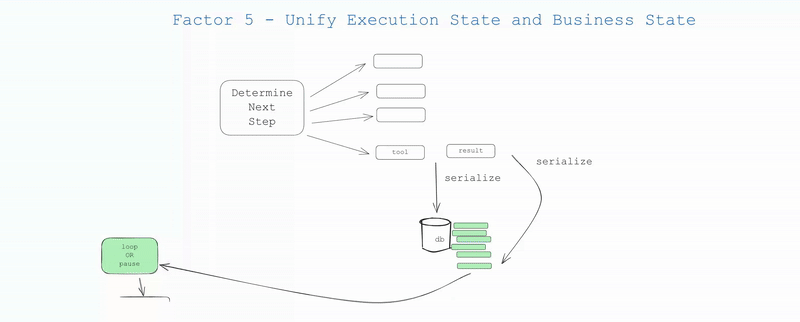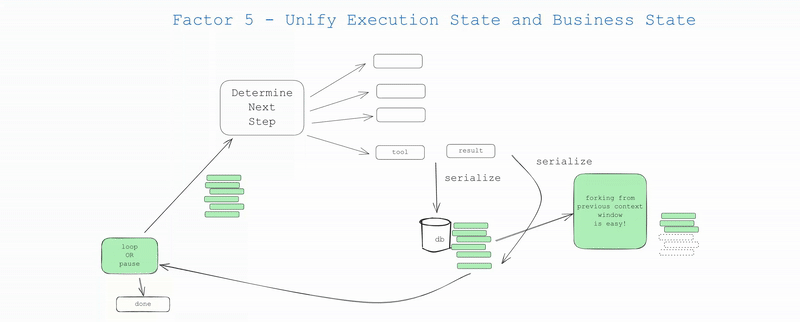
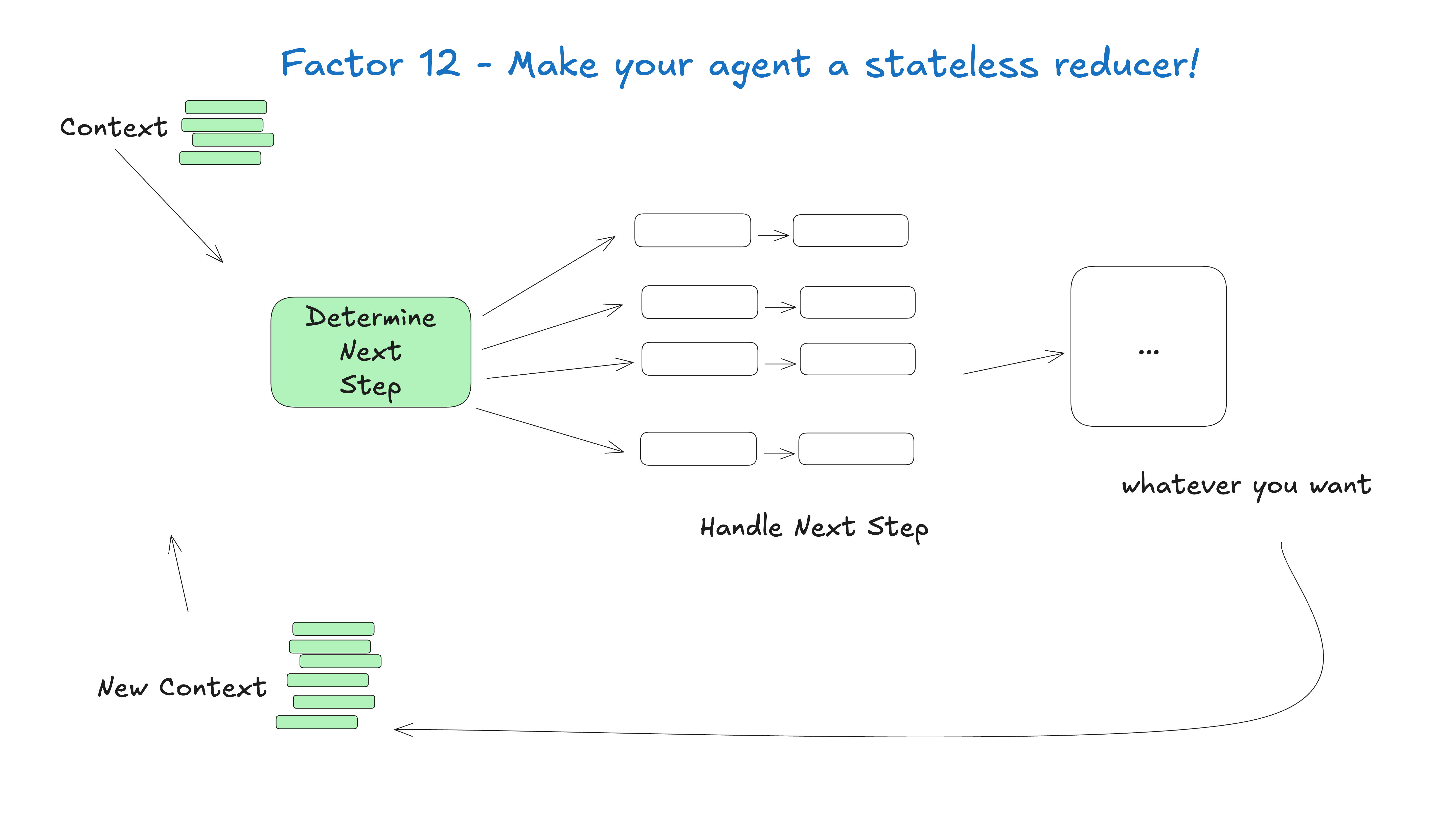
Auch außerhalb des KI-Bereichs versuchen viele Infrastruktursysteme, den “Ausführungsstatus” vom “Geschäftsstatus” zu trennen. Für KI-Anwendungen kann dies komplexe Abstraktionen beinhalten, um Informationen wie den aktuellen Schritt, den nächsten Schritt, den Wartestatus, Wiederholungsversuche usw. zu verfolgen. Diese Trennung führt zu Komplexität, und obwohl es sich lohnen kann, kann es für Ihren Anwendungsfall trivial sein...
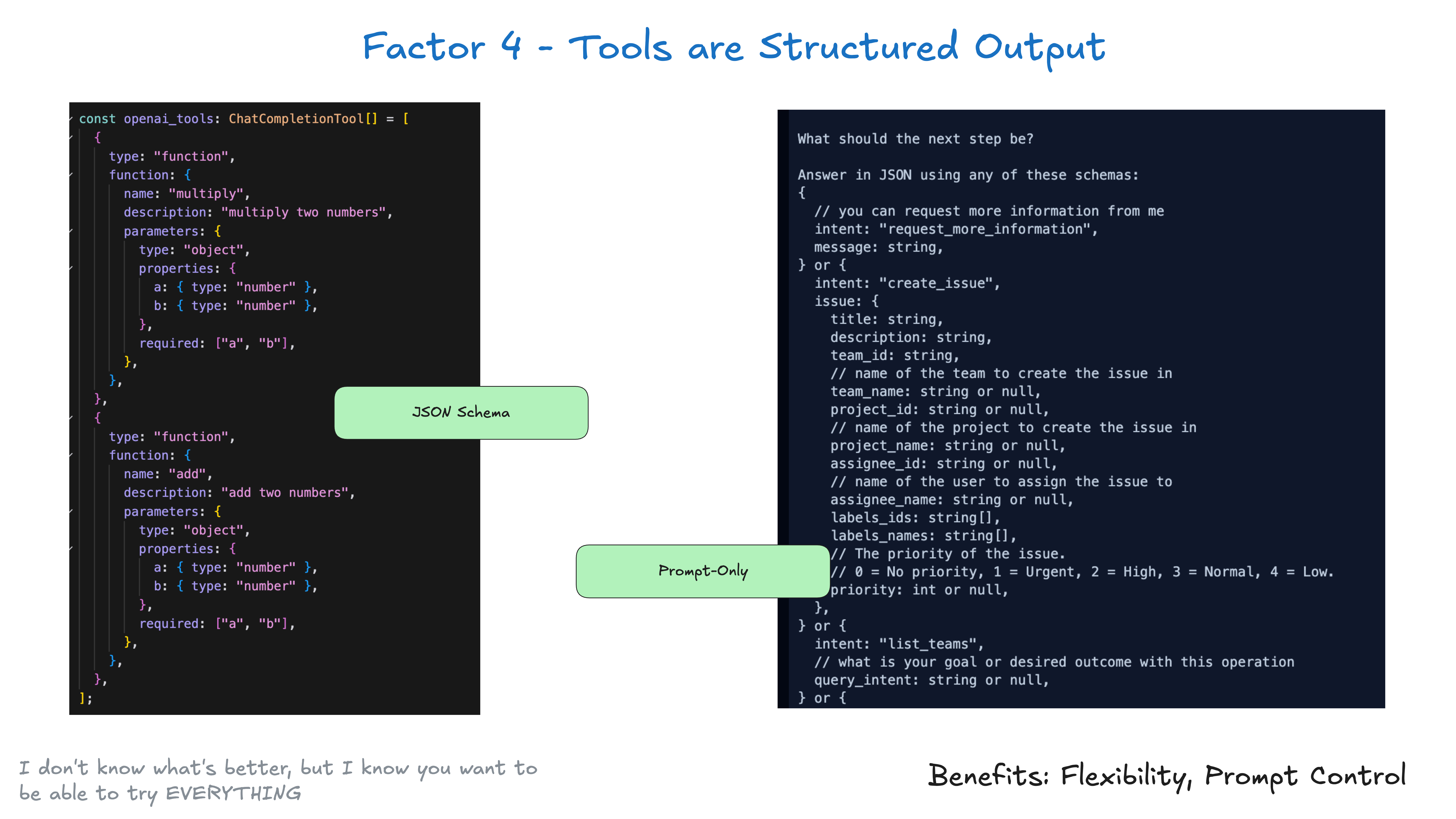
Das Werkzeug muss nicht komplex sein. Im Kern handelt es sich einfach um strukturierte Ausgaben Ihres Large Language Model (LLM), die zum Auslösen von deterministischem Code verwendet werden. Angenommen, Sie haben zwei Werkzeuge CreateIssue und SearchIssues. Ein Large Language Model (LLM) zu bitten, "eines von mehreren Werkzeugen zu verwenden", bedeutet in Wirklichkeit, es zu bitten, eine Ausgabe zu machen...
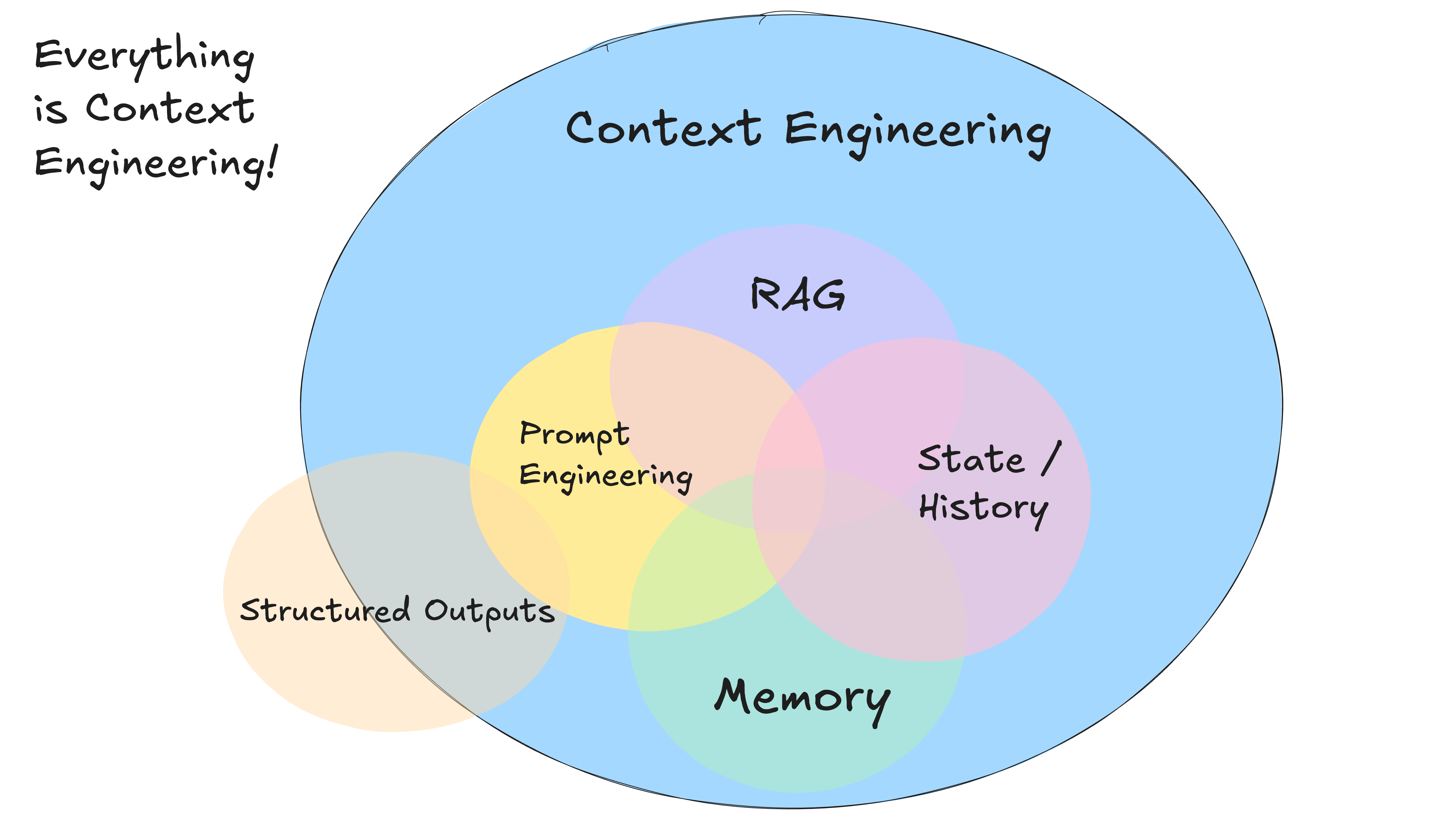
Sie müssen kein standardisiertes, nachrichtenbasiertes Format verwenden, um dem großen Sprachmodell Kontext zu liefern. Zu jedem Zeitpunkt lautet Ihre Eingabe an das große Sprachmodell in der KI-Intelligenz: “Hier ist alles, was bisher passiert ist, und hier ist, was als Nächstes zu tun ist” - das ist kontextbezogene Technik. Große Sprachmodelle sind zustandslose Funktionen, die Eingaben in Ausgaben umwandeln...

Lagern Sie die Entwicklung Ihrer Eingabeaufforderung nicht an ein Framework aus. Übrigens ist dies kein neuer Ratschlag: Einige Frameworks bieten einen "Blackbox"-Ansatz wie diesen: agent = Agent( role="..." , goal="..." , personality="..." , tools=...
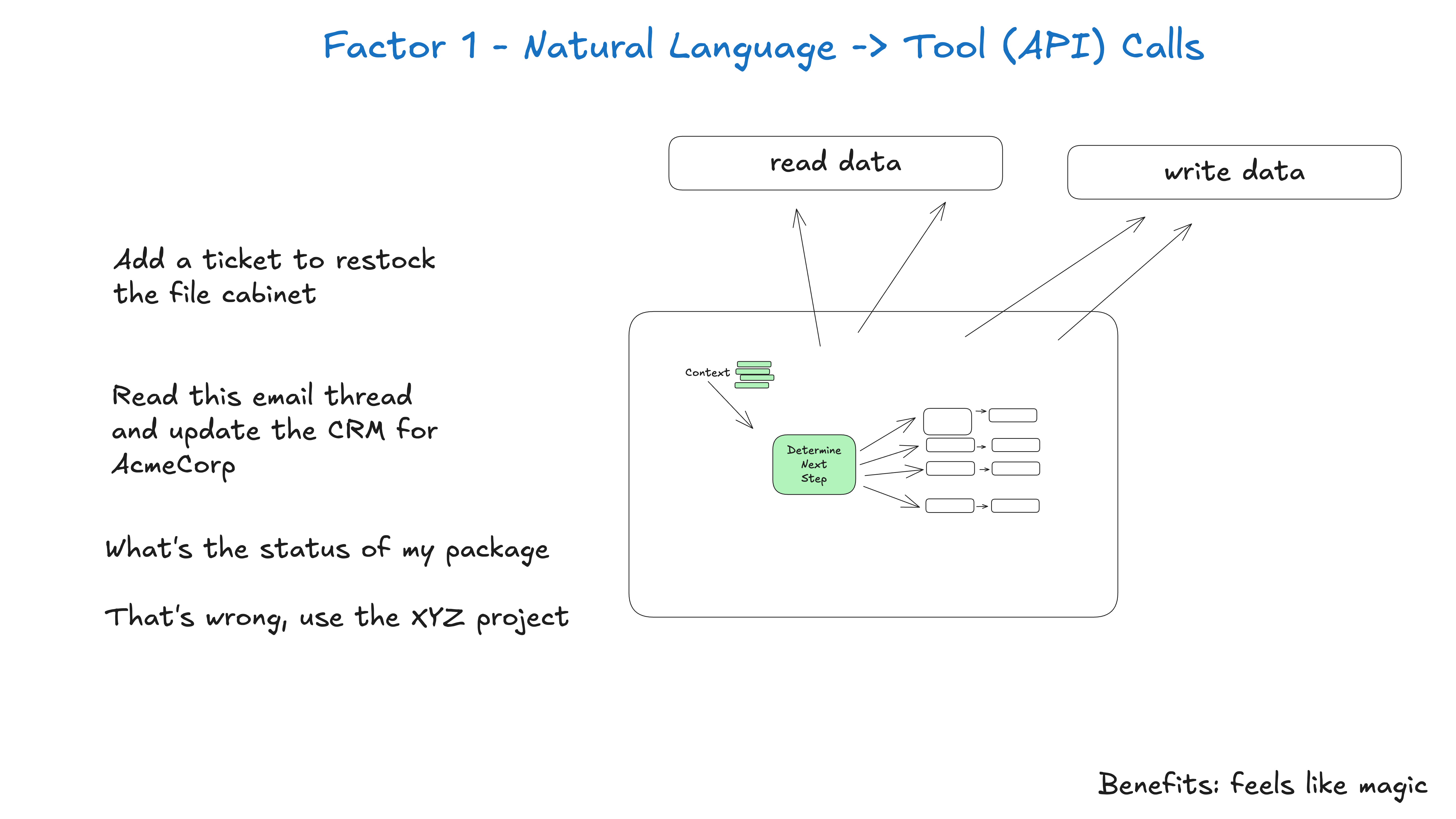
Eines der gängigsten Muster beim Aufbau von Intelligenzen ist die Umwandlung natürlicher Sprache in strukturierte Werkzeugaufrufe. Dies ist ein leistungsfähiges Muster, mit dem man Intelligenzen erstellen kann, die über Aufgaben nachdenken und sie ausführen können. Dieses Muster, wenn es atomar angewandt wird, besteht darin, eine Phrase zu nehmen (z. B. Können Sie eine Zahlung von 750 $ für Terri...
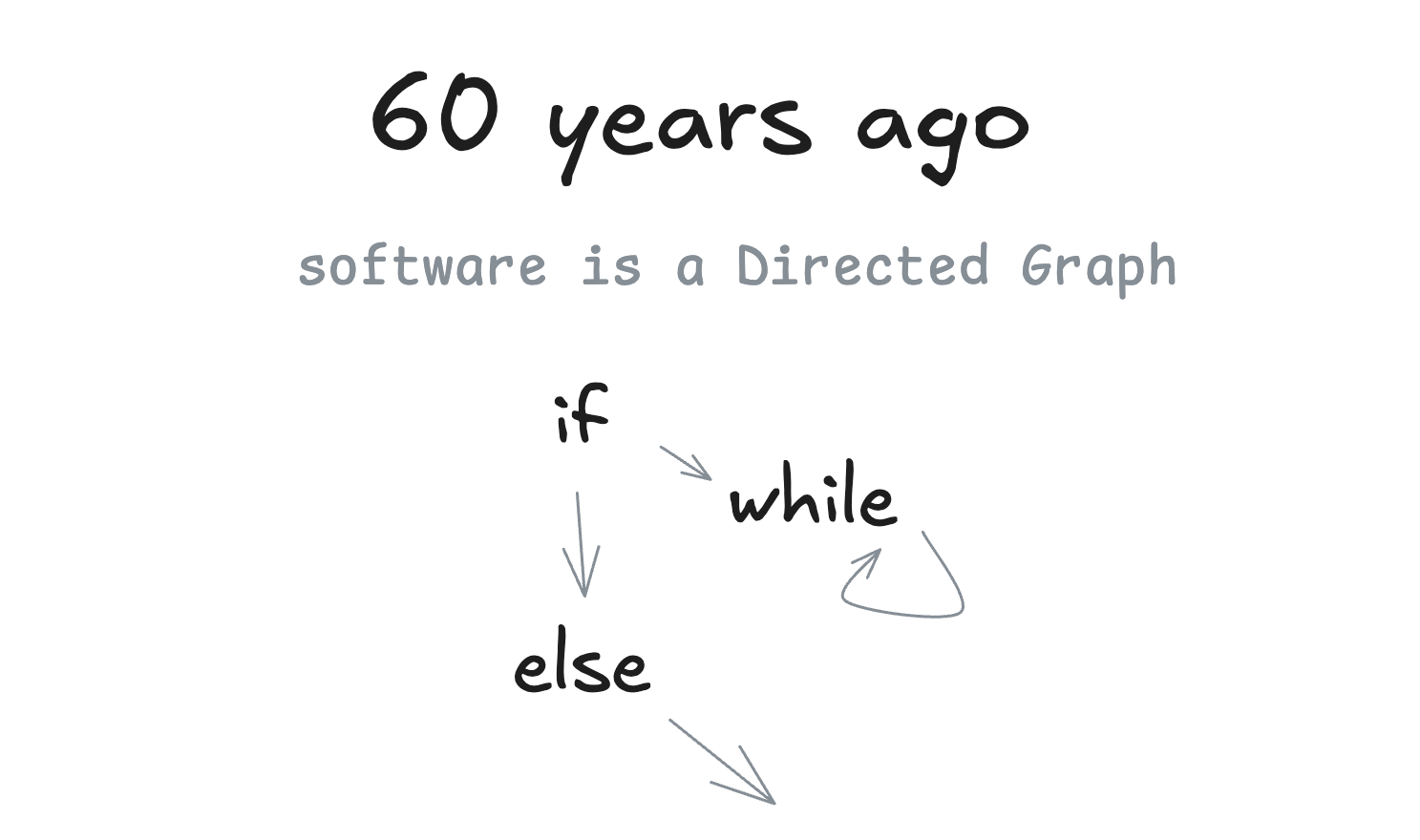
Ausführliche Version: Wie wir hierher gekommen sind Sie müssen nicht auf mich hören Egal, ob Sie neu auf dem Gebiet der Intelligenzen sind oder ein mürrischer Veteran wie ich, ich werde versuchen, Sie davon zu überzeugen, die meisten Ihrer bereits bestehenden Ansichten über KI-Intelligenzen über Bord zu werfen, einen Schritt zurückzutreten und sie von Grund auf zu überdenken. (Falls Sie OpenAI vor ein paar Wochen verpasst haben ...
zurück zum Anfang

