



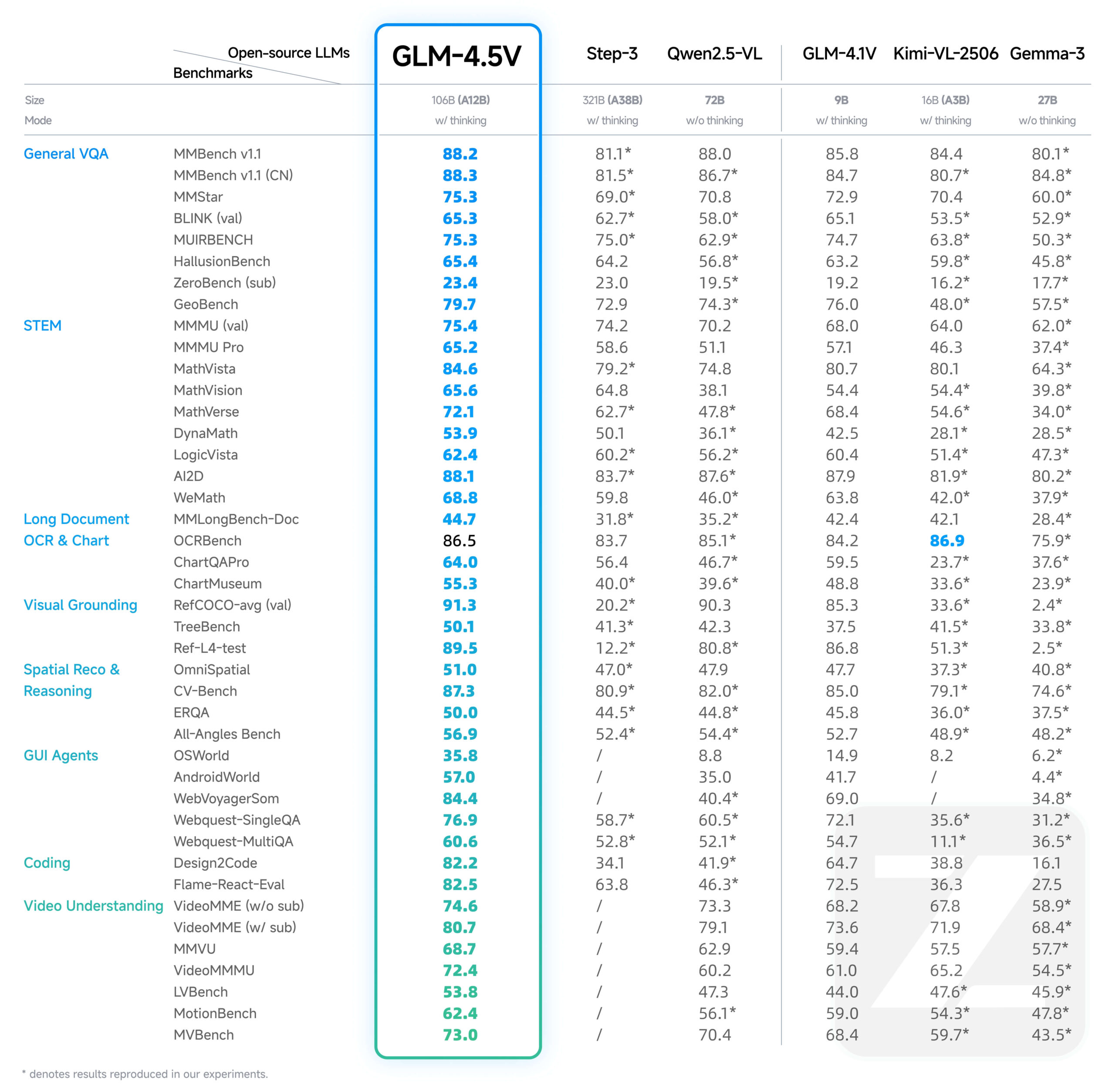
GLM-4.5V ist eine neue Generation des von Zhipu AI (Z.AI) entwickelten Visual Language Megamodel (VLM). Das Modell basiert auf dem Flaggschiff-Textmodell GLM-4.5-Air, das die MOE-Architektur verwendet, mit einer Gesamtzahl von 106 Milliarden Referenzen, von denen 12 Milliarden Aktivierungsparameter sind.GLM-4.5V verarbeitet nicht nur Bilder und Texte, sondern auch Videoinhalte, und seine Kernkompetenzen umfassen komplexes Image Reasoning, das Verstehen langer Videos, das Parsen von Dokumenteninhalten und die Manipulation grafischer Benutzeroberflächen (GUI) Aufgaben. Um Effizienz und Effektivität in verschiedenen Szenarien auszubalancieren, führt das Modell einen "Denkmodus"-Schalter ein, der es dem Benutzer ermöglicht, zwischen Aufgaben zu wechseln, die eine schnelle Reaktion oder tiefgreifende Überlegungen erfordern. Das Modell unterstützt eine maximale Ausgabelänge von 64K Token und ist auf Hugging Face unter der MIT-Lizenz als Open-Source verfügbar, so dass Entwickler es kommerziell und für die Sekundärentwicklung nutzen können.
Funktionsliste
- Webcode-GenerierungAnalyse von Screenshots oder Bildschirmaufzeichnungen von Webseiten, um das Layout und die Interaktionslogik zu verstehen, und direkte Generierung von vollständig nutzbarem HTML- und CSS-Code.
- ErdungGenaue Lokalisierung und Identifizierung bestimmter Objekte in einem Bild oder Video, und zwar in Form von Koordinaten (z. B.
[x1,y1,x2,y2]) für Szenarien wie Sicherheit, Qualitätskontrolle und Inhaltsüberprüfung an den Zielort zurückkehren. - GUI-IntelligenzDie Fähigkeit, Screenshots zu erkennen und zu verarbeiten und Aktionen wie Klicken, Streichen und Ändern von Inhalten als Reaktion auf Befehle auszuführen, unterstützt Intelligenzen bei der Durchführung automatisierter Aufgaben.
- Auslegung langer komplexer DokumenteAnalyse von Dutzenden von Seiten komplexer grafischer Berichte mit Inhaltszusammenfassungen, Übersetzungen, Diagrammextraktion und der Möglichkeit, Einblicke auf der Grundlage des Dokumenteninhalts zu gewinnen.
- Bilderkennung und ReasoningStarkes Szenenverständnis und logische Schlussfolgerungen, die in der Lage sind, die Kontextinformationen hinter einem Bild allein auf der Grundlage seines Inhalts abzuleiten, ohne sich auf eine externe Suche zu verlassen.
- Video-VerständnisParsing von langen Videoinhalten und genaue Identifizierung von Zeit, Personen, Ereignissen und logischen Beziehungen zwischen ihnen im Video.
- Disziplinäre Fragen und Antworten:: Fähigkeit, komplexe Probleme durch die Kombination von Grafik und Text zu lösen, besonders geeignet für das Lösen und Erklären von Aufgaben in K12-Bildungsszenarien.
Hilfe verwenden
GLM-4.5V bietet Entwicklern eine Vielzahl von Möglichkeiten, darauf zuzugreifen und es zu nutzen, darunter die schnelle Integration über die offizielle API und die lokale Bereitstellung über Hugging Face.
1. über die offene Plattform-API von Wisdom Spectrum AI verwenden (empfohlen)
Die Verwendung der offiziellen API ist der bequemste Weg für Entwickler, die Modelle schnell in ihre Anwendungen integrieren möchten. Bei diesem Ansatz entfällt die Notwendigkeit, komplexe Hardwareressourcen zu verwalten.
API-Preise
- Einfuhr: ¥ 0,6 / Million tokens
- Ausfuhren¥1.8 / Million Token
Aufrufschritt
- API-Schlüssel abrufenGehen Sie zur Smart Spectrum AI Open Platform, um sich für ein Konto zu registrieren und einen API-Schlüssel zu erstellen.
- Installieren des SDK:
pip install zhipuai - Schreiben Sie den aufrufenden CodeNachfolgend finden Sie ein Beispiel für einen API-Aufruf mit dem Python SDK, der zeigt, wie man ein Bild und einen Text sendet, um eine Frage zu stellen.
from zhipuai import ZhipuAI # 使用你的API Key进行初始化 client = ZhipuAI(api_key="YOUR_API_KEY") # 请替换成你自己的API Key response = client.chat.completions.create( model="glm-4.5v", # 指定使用GLM-4.5V模型 messages=[ { "role": "user", "content": [ { "type": "text", "text": "这张图片里有什么?请详细描述一下。" }, { "type": "image_url", "image_url": { "url": "https://img.alicdn.com/imgextra/i3/O1CN01b22S451o81U5g251b_!!6000000005177-0-tps-1024-1024.jpg" } } ] } ] ) print(response.choices[0].message.content)
Aktivieren des "Denkmodus"
Für komplexe Aufgaben, die ein tiefergehendes Denken des Modells erfordern (z. B. die Analyse komplexer Diagramme), können Sie die OptionthinkingParameter, um den "Denkmodus" zu aktivieren.
Nachfolgend finden Sie eine Liste der häufigsten Verwendungsmöglichkeiten dercURLOffizielles Beispiel für den Aufruf und die Aktivierung des Denkmodus:
curl --location 'https://api.z.ai/api/paas/v4/chat/completions' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "glm-4.5v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://cloudcovert-1305175928.cos.ap-guangzhou.myqcloud.com/%E5%9B%BE%E7%89%87grounding.PNG"
}
},
{
"type": "text",
"text": "桌子上从右数第二瓶啤酒在哪里?请用[[xmin,ymin,xmax,ymax]]格式提供坐标。"
}
]
}
],
"thinking": {
"type":"enabled"
}
}'
2) Lokaler Einsatz durch Hugging Face Transformers
Für Forscher und Entwickler, die eine sekundäre Entwicklung oder eine Offline-Nutzung benötigen, können die Modelle vom Hugging Face Hub heruntergeladen und in ihrer eigenen Umgebung eingesetzt werden.
- Anforderungen an die Umwelt:: Die lokale Bereitstellung erfordert eine starke Hardwareunterstützung, in der Regel einen leistungsstarken NVIDIA-Grafikprozessor mit großem Videospeicher (z. B. A100/H100).
- Installation von Abhängigkeiten:
pip install transformers torch accelerate Pillow - Laden und Ausführen des Modells:
import torch from PIL import Image from transformers import AutoProcessor, AutoModelForCausalLM # Hugging Face上的模型路径 model_path = "zai-org/GLM-4.5V" processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True) # 加载模型 model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True ).to("cuda").eval() # 准备图片和文本提示 image = Image.open("path_to_your_image.jpg").convert("RGB") prompt_text = "请使用HTML和CSS,根据这张网页截图生成一个高质量的UI界面。" prompt = [{"role": "user", "image": image, "content": prompt_text}] # 处理输入并生成回复 inputs = processor.apply_chat_template(prompt, add_generation_prompt=True, tokenize=True, return_tensors="pt", return_dict=True) inputs = {k: v.to("cuda") for k, v in inputs.items()} gen_kwargs = {"max_new_tokens": 4096, "do_sample": True, "top_p": 0.8, "temperature": 0.6} with torch.no_grad(): outputs = model.generate(**inputs, **gen_kwargs) response_ids = outputs[:, inputs['input_ids'].shape[1]:] response_text = processor.decode(response_ids[0]) print(response_text)
Anwendungsszenario
- Automatisierung der Front-End-Entwicklung
Entwickler können einen Screenshot einer gut gestalteten Webseite zur Verfügung stellen, und GLM-4.5V kann direkt das UI-Layout, das Farbschema und die Komponentenstile im Screenshot analysieren und automatisch die entsprechenden HTML- und CSS-Codes generieren, was die Entwicklungseffizienz vom Designentwurf bis zur statischen Seite erheblich verbessert. - Intelligente Sicherheit und Bewachung
In Sicherheitsüberwachungsszenarien kann das Modell Echtzeit-Videoströme analysieren und den Standort des Ziels auf dem Bildschirm entsprechend den Befehlen genau markieren (z. B. "Bitte lokalisieren Sie alle Personen, die im Bild rot tragen"), was für die Verfolgung von Personen, die Erkennung von abnormalem Verhalten usw. genutzt werden kann. - Intelligente Büroautomation
In Bürosoftware können die Benutzer komplexe Vorgänge mit Hilfe des natürlichsprachlichen Befehlsmodells ausführen. Der Benutzer kann zum Beispiel sagen: "Bitte ändern Sie die Daten in der ersten Zeile der Tabelle auf der vierten Seite von PPT in '89', '21', '900'", und das Modell erkennt den Bildschirminhalt und simuliert Maus- und Tastaturoperationen, um die Änderung durchzuführen. "Das Modell erkennt den Bildschirminhalt und simuliert Maus- und Tastatureingaben, um die Änderung abzuschließen. - Forschung und Analyse von Finanzdokumenten
Ein Forscher oder Analyst kann Dutzende von Seiten mit Forschungs- oder Finanzberichten im PDF-Format hochladen und das Modell bitten, "die Kernpunkte des Berichts zusammenzufassen und die Schlüsseldaten aus Kapitel 3 in eine Markdown-Tabelle zu konvertieren". Das Modell liest sich in die Tiefe und extrahiert die Informationen und erstellt strukturierte Zusammenfassungen und Diagramme. - K12 Bildungsberatung
Die Schülerinnen und Schüler können ein Bild von einem mathematischen oder physikalischen Anwendungsproblem (mit Diagrammen und Text) aufnehmen und dem Modell Fragen stellen. Das Modell gibt nicht nur die richtige Antwort, sondern agiert auch wie ein Lehrer, der Schritt für Schritt die Ideen und Formeln erklärt, die zur Lösung des Problems verwendet werden, und einen detaillierten Lösungsweg aufzeigt.
QA
- Welche Beziehung besteht zwischen GLM-4.5V und GLM-4.1V?
GLM-4.5V ist eine Fortsetzung und ein iteratives Upgrade der GLM-4.1V-Thinking Technologielinie. Es basiert auf dem leistungsfähigeren Klartext-Flaggschiff GLM-4.5-Air und verbessert auf der Grundlage der Fähigkeiten des Vorgängermodells umfassend die Leistung bei allen Arten von visuellen multimodalen Aufgaben. - Wie hoch sind die Kosten für die Verwendung der GLM-4.5V API?
Der Abrechnungssatz für die Nutzung des Modells über die offizielle API von Wisdom Spectrum AI beträgt 0,6 RMB pro Million Token auf der Input-Seite und 1,8 RMB pro Million Token auf der Output-Seite. - Was genau bewirkt der "Denkmodus" (Thinking Mode)?
"Der Denkmodus ist für komplexe Aufgaben gedacht, die ein tiefgreifendes Denken erfordern. Wenn er aktiviert ist, verbringt das Modell mehr Zeit damit, logisch zu denken und Informationen zu integrieren, um qualitativ hochwertigere und genauere Antworten zu produzieren, allerdings mit längeren Antwortzeiten. Es eignet sich für Szenarien wie das Analysieren komplexer Diagramme, das Schreiben von Code oder das Interpretieren langer Dokumente. Für einfache Fragen und Antworten kann ein schneller reagierendes, nicht denkendes Modell verwendet werden.



























