


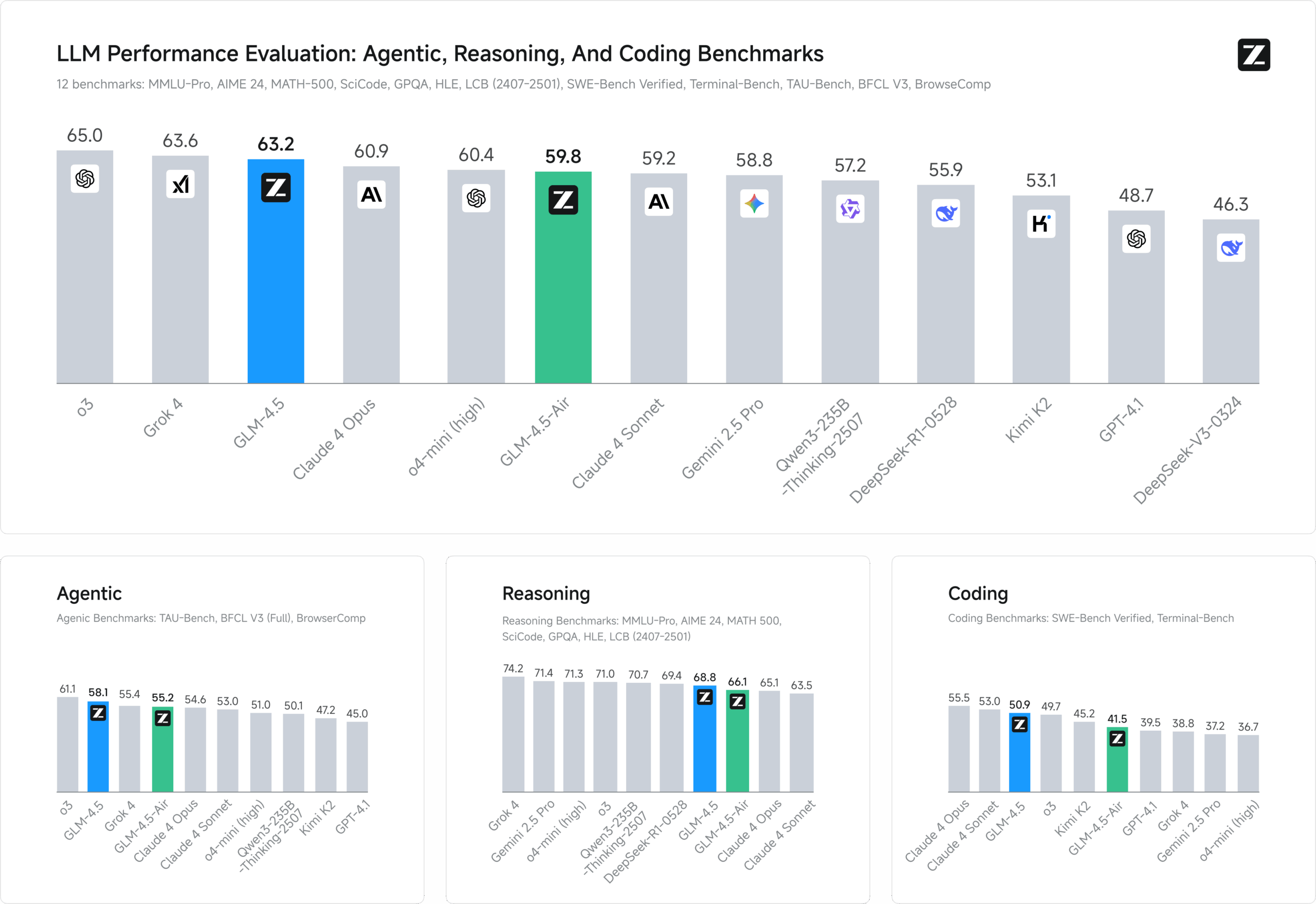
GLM-4.5 ist ein von zai-org entwickeltes, quelloffenes multimodales Großsprachenmodell, das für intelligente Schlussfolgerungen, Codegenerierung und intelligente Körperaufgaben konzipiert ist. Es besteht aus GLM-4.5 (355 Milliarden Parameter, 32 Milliarden aktive Parameter), GLM-4.5-Air (106 Milliarden Parameter, 12 Milliarden aktive Parameter) und anderen Varianten und verwendet die Mixed Expertise (MoE) Architektur, die 128K Kontextlängen und 96K Output-Token unterstützt. Die Modelle sind auf 15 Billionen Token vortrainiert, in den Bereichen Code, Inferenz und Intelligenz feinabgestimmt und erzielen Spitzenleistungen in mehreren Benchmarks, wobei sie sich teilweise Closed-Source-Modellen annähern oder diese sogar übertreffen, insbesondere bei Programmier- und Tool-Calling-Aufgaben.GLM-4.5 wurde unter der MIT-Lizenz veröffentlicht und wird sowohl für die akademische als auch für die kommerzielle Nutzung unterstützt und eignet sich für den lokalen Einsatz oder den Einsatz in der Cloud für Entwickler, Forscher und Unternehmen.
Funktionsliste
- Gemischter Denkmodus: Unterstützt den Denkmodus, um komplexe Überlegungen und Werkzeugaufrufe zu verarbeiten, und den Nicht-Denkmodus, um schnelle Antworten zu geben.
- Multimodale Unterstützung: Verarbeitet Text- und Bildeingaben für multimodale Fragen und die Erstellung von Inhalten.
- Intelligente Programmierung: Generieren Sie hochwertigen Code in Python, JavaScript und anderen Sprachen, mit Unterstützung für Code-Vervollständigung und Fehlerbehebung.
- Intelligente Körperfunktionen: Unterstützung für Funktionsaufrufe, Web-Browsing und automatische Aufgabenverarbeitung für komplexe Arbeitsabläufe.
- Kontext-Caching: Optimieren Sie die Leistung langer Dialoge und reduzieren Sie doppelte Berechnungen.
- Strukturierte Ausgabe: Unterstützt JSON und andere Formate für eine einfache Systemintegration.
- Verarbeitung langer Kontexte: Native Unterstützung für 128K Kontextlänge, geeignet für die Analyse langer Dokumente.
- Streaming-Output: Ermöglicht Echtzeit-Reaktionen, um das interaktive Erlebnis zu verbessern.
Hilfe verwenden
GLM-4.5 bietet Modellgewichte und Werkzeuge über ein GitHub-Repository (https://github.com/zai-org/GLM-4.5), das für Benutzer mit technischem Hintergrund geeignet ist, um es lokal oder in der Cloud einzusetzen. Nachfolgend finden Sie eine detaillierte Installations- und Nutzungsanleitung, die den Benutzern einen schnellen Einstieg ermöglicht.
Einbauverfahren
- Vorbereitung der Umwelt
Vergewissern Sie sich, dass Python 3.8 oder höher und Git installiert sind. Es wird eine virtuelle Umgebung empfohlen:python -m venv glm_env source glm_env/bin/activate # Linux/Mac glm_env\Scripts\activate # Windows - Klon-Lager
Holen Sie sich den GLM-4.5-Code von GitHub:git clone https://github.com/zai-org/GLM-4.5.git cd GLM-4.5 - Installation von Abhängigkeiten
Installiert die angegebene Version der Abhängigkeit, um Kompatibilität zu gewährleisten:pip install setuptools>=80.9.0 setuptools_scm>=8.3.1 pip install git+https://github.com/huggingface/transformers.git@91221da2f1f68df9eb97c980a7206b14c4d3a9b0 pip install git+https://github.com/vllm-project/vllm.git@220aee902a291209f2975d4cd02dadcc6749ffe6 pip install torchvision>=0.22.0 gradio>=5.35.0 pre-commit>=4.2.0 PyMuPDF>=1.26.1 av>=14.4.0 accelerate>=1.6.0 spaces>=0.37.1Hinweis: Die Kompilierung von vLLM kann lange dauern. Verwenden Sie die vorkompilierte Version, wenn Sie sie nicht benötigen.
- Modell Download
Die Modellgewichte werden in Hugging Face und ModelScope gehostet. Unten sehen Sie ein Beispiel für das Laden von GLM-4.5-Air:from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("zai-org/GLM-4.5-Air", trust_remote_code=True) model = AutoModel.from_pretrained("zai-org/GLM-4.5-Air", trust_remote_code=True).half().cuda() model.eval() - Hardware-Voraussetzung
- GLM-4.5-Air: 16 GB GPU-Speicher erforderlich (INT4 quantifiziert auf ~12 GB).
- GLM-4.5: Empfohlen für Multi-GPU-Umgebungen, erfordert etwa 32 GB RAM.
- CPU Reasoning: Der GLM-4.5-Air läuft auf einer CPU mit 32 GB RAM, ist aber langsam.
Verwendung
GLM-4.5 unterstützt Befehlszeilen-, Webinterface- und API-Aufrufe und bietet damit eine Vielzahl von Interaktionsmethoden.
Befehlszeilenargumentation
ausnutzen trans_infer_cli.py Skripte für den interaktiven Dialog:
python inference/trans_infer_cli.py --model_name zai-org/GLM-4.5-Air
- Geben Sie einen Text oder ein Bild ein, und das Modell gibt eine Antwort zurück.
- Unterstützt mehrere Dialogrunden und speichert automatisch den Verlauf.
- Beispiel: Erzeugen von Python-Funktionen:
response, history = model.chat(tokenizer, "写一个 Python 函数计算三角形面积", history=[]) print(response)Ausgabe:
def triangle_area(base, height): return 0.5 * base * height
Webschnittstelle
Starten Sie das Webinterface über Gradio mit Unterstützung für multimodale Eingaben:
python inference/trans_infer_gradio.py --model_name zai-org/GLM-4.5-Air
- Zugriff auf die lokale Adresse (normalerweise
http://127.0.0.1:7860)。 - Geben Sie einen Text ein oder laden Sie ein Bild oder eine PDF-Datei hoch und klicken Sie auf "Senden", um eine Antwort zu erhalten.
- Funktionen: Hochladen von PDFs, Modelle können geparst und Fragen beantwortet werden.
API-Dienste
GLM-4.5 unterstützt eine OpenAI-kompatible API unter Verwendung der vLLM Einsatz:
vllm serve zai-org/GLM-4.5-Air --limit-mm-per-prompt '{"image":32}'
- Beispiel-Anfrage:
import requests payload = { "model": "GLM-4.5-Air", "messages": [{"role": "user", "content": "分析这张图片"}], "image": "path/to/image.jpg" } response = requests.post("http://localhost:8000/v1/chat/completions", json=payload) print(response.json())
Featured Function Bedienung
- gemischtes Inferenzmodell
- Denkmuster Geeignet für komplexe Aufgaben wie mathematische Überlegungen oder den Aufruf von Werkzeugen:
model.chat(tokenizer, "解决方程:2x^2 - 8x + 6 = 0", mode="thinking")Das Modell wird detaillierte Lösungsschritte ausgeben.
- Modus Vivendi : Gut für schnelle Quizze:
model.chat(tokenizer, "翻译:Good morning", mode="non-thinking") - multimodale Unterstützung
- Verarbeitet Text- und Bildeingaben. Zum Beispiel das Hochladen von Bildern zu Mathe-Themen:
python inference/trans_infer_gradio.py --input math_problem.jpg - Hinweis: Die gleichzeitige Verarbeitung von Bildern und Videos wird derzeit noch nicht unterstützt.
- Verarbeitet Text- und Bildeingaben. Zum Beispiel das Hochladen von Bildern zu Mathe-Themen:
- Intelligente Programmierung
- Code generieren: Geben Sie die Aufgabenbeschreibung ein, um den vollständigen Code zu generieren:
response, _ = model.chat(tokenizer, "写一个 Python 脚本实现贪吃蛇游戏", history=[]) - Unterstützt Code-Vervollständigung und Fehlerbehebung für Rapid Prototyping.
- Code generieren: Geben Sie die Aufgabenbeschreibung ein, um den vollständigen Code zu generieren:
- Kontext-Cache (Datenverarbeitung)
- Optimieren Sie die Leistung bei langen Dialogen und reduzieren Sie Doppelzählungen:
model.chat(tokenizer, "继续上一轮对话", cache_context=True)
- Optimieren Sie die Leistung bei langen Dialogen und reduzieren Sie Doppelzählungen:
- Strukturierte Ausgabe
- Gibt das JSON-Format für eine einfache Systemintegration aus:
response = model.chat(tokenizer, "列出 Python 的基本数据类型", format="json")
- Gibt das JSON-Format für eine einfache Systemintegration aus:
caveat
- Bei der Verwendung von Transformatoren 4.49.0 kann es zu Kompatibilitätsproblemen kommen, empfohlen wird 4.48.3.
- Die vLLM-API unterstützt bis zu 300 Bilder in einer einzigen Eingabe.
- Stellen Sie sicher, dass der GPU-Treiber CUDA 11.8 oder höher unterstützt.
Anwendungsszenario
- Web-Entwicklung
GLM-4.5 generiert Front-End- und Back-End-Code, um die schnelle Erstellung moderner Webanwendungen zu unterstützen. Für die Erstellung interaktiver Webseiten sind beispielsweise nur wenige Sätze an Beschreibung erforderlich. - intelligente Frage und Antwort (Q&A)
Das Modell analysiert komplexe Anfragen und kombiniert Websuche und Wissensdatenbank, um präzise Antworten zu geben, die sich für den Kundenservice und Bildungsszenarien eignen. - Intelligentes Büro
Generieren Sie automatisch logische PPTs oder Poster mit Unterstützung für die Erweiterung des Inhalts aus Überschriften, geeignet für die Büroautomatisierung. - Codegenerierung
Generiert Code in Python, JavaScript und anderen Sprachen und unterstützt mehrere iterative Entwicklungsrunden für schnelles Prototyping und Fehlerbehebung. - komplexe Übersetzung
Übersetzung längerer akademischer oder politischer Texte mit semantischer Konsistenz und einem Stil, der für Veröffentlichungen und grenzüberschreitende Dienste geeignet ist.
QA
- Was ist der Unterschied zwischen GLM-4.5 und GLM-4.5-Air?
GLM-4.5 (355 Milliarden Parameter, 32 Milliarden aktiv) eignet sich für hochleistungsfähige Schlussfolgerungen; GLM-4.5-Air (106 Milliarden Parameter, 12 Milliarden aktiv) ist leichter und eignet sich für ressourcenbeschränkte Umgebungen. - Wie kann die Geschwindigkeit des Denkens optimiert werden?
Verwenden Sie die GPU-Beschleunigung, aktivieren Sie die INT4-Quantisierung oder wählen Sie GLM-4.5-Air, um die Ressourcenanforderungen zu reduzieren. - Unterstützt es die kommerzielle Nutzung?
Ja, die MIT-Lizenz erlaubt die freie kommerzielle Nutzung. - Wie gehen Sie mit langen Kontexten um?
Native Unterstützung für 128K-Kontexte, aktivierenyarnDie Parameter können noch erweitert werden.






























