

Die Entwicklung multimodaler Makromodelle tritt in eine neue Phase ein, die sich von der einfachen Bilderkennung ("Sehen") zu komplexen logischen Schlussfolgerungen und tiefem Verständnis ("Sehen und Denken") entwickelt. Kürzlich hat Smart Spectrum AI die folgende Software veröffentlicht und frei zugänglich gemacht GLM-4.1V-Thinking in der Serie GLM-4.1V-9B-Thinking Modelle, die neue Fortschritte in ihren kognitiven Fähigkeiten höherer Ordnung bei der visuellen Sprachmodellierung zeigen.
Die zentrale Neuerung des Modells ist die Einführung einer Methode namens Verstärkungslernen mit Curriculum Sampling (RLCS, Reinforcement Learning with Curriculum Sampling) Trainingsstrategie. Bei diesem Ansatz wird das Modell trainiert, indem Aufgaben von leicht bis schwer geplant werden, ähnlich wie beim menschlichen Lernprozess, was zu erheblichen Fortschritten bei komplexen logischen Aufgaben führt.
Am auffälligsten ist seine Leistungsfähigkeit. Trotz der GLM-4.1V-9B-Thinking Mit nur 9 Milliarden Parametern erreicht oder übertrifft sie sogar die 72 Milliarden Parameter von 18 maßgeblichen Benchmarks. Qwen2.5-VL-72BDieses Ergebnis stellt die traditionelle Vorstellung in Frage, dass "größere Modelle leistungsfähiger sind". Dieses Ergebnis stellt die traditionelle Vorstellung "je größer das Modell, desto leistungsfähiger ist es" in Frage und verdeutlicht das große Potenzial fortschrittlicher Modellarchitekturen und effizienter Trainingsstrategien zur Verbesserung der Leistung und zur Einsparung von Ressourcen.

Links zu verwandten Ressourcen:
- Dissertation. GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
- Offene Quellcode-Repositories.
- Online-Erfahrung.
- API-Dokumentation. Großes Modell Offene Plattform
Demonstration der Kernkompetenzen und Anwendungen des Modells
GLM-4.1V-9B-Thinking Durch die Einführung des Chain-of-Thought-Mechanismus ist es möglich, den detaillierten Argumentationsprozess bei der Ausgabe der Antwort darzustellen. Dies verbessert nicht nur die Genauigkeit und Reichhaltigkeit der Antworten, sondern auch die Interpretierbarkeit der Ergebnisse. Das Modell integriert umfangreiche multimodale Verarbeitungsmöglichkeiten durch hybrides Training.
- Video- und Bildverstehen. Die Fähigkeit, bis zu zwei Stunden Videomaterial zu analysieren oder detaillierte Fragen und Antworten zu komplexen Bildinhalten zu stellen, zeugt von einer starken logischen Analyse.
- Interdisziplinäre Problemlösung. Unterstützt das schematische Lösen von Problemen in den Fächern Mathematik, Physik, Biologie, Chemie und anderen Fächern und kann detaillierte Schritte zum Nachdenken über diese Probleme angeben.
- Hochpräzise Informationsextraktion. Genaue Erkennung und Strukturierung der Ausgabe von Text und grafischen Informationen in Bildern und Videos.
- Dokumentation und Schnittstelleninteraktion. Es kann von Haus aus den Inhalt von Dokumenten in den Bereichen Finanzen, Verwaltung und anderen Bereichen verstehen und kann GUI-Elemente erkennen und Befehle wie Klicken und Schieben ausführen, indem es als "intelligenter GUI-Körper" fungiert.
- Von der Vision zur Codegenerierung. Fähigkeit, automatisch Front-End-Code auf der Grundlage von Screenshots der eingegebenen Schnittstelle zu schreiben.
Nachstehend finden Sie einige Beispiele für typische Anwendungen:
Beispiel 1: Grafische Analyse und Argumentation
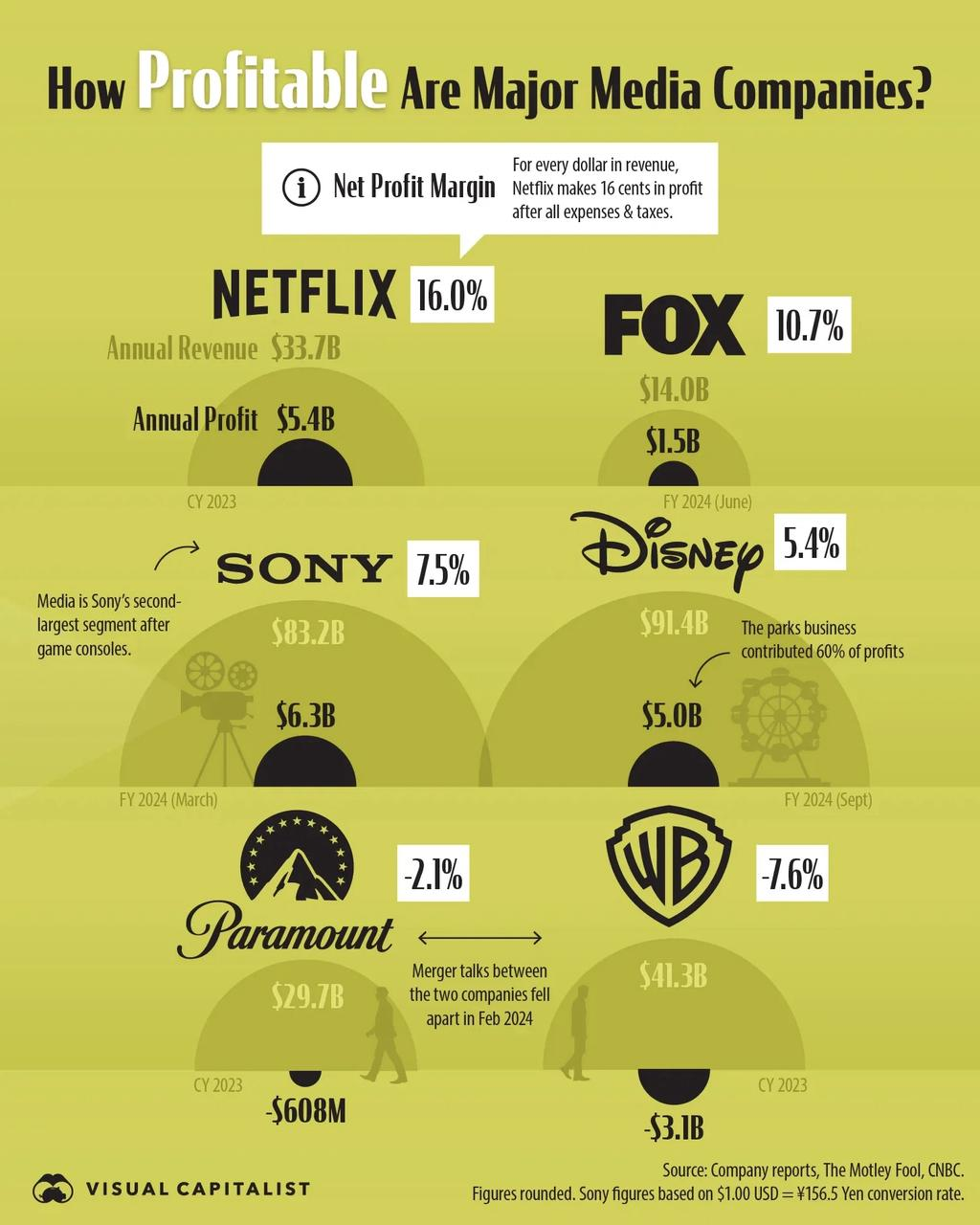
Eingabebefehl.
Nennen Sie das Unternehmen mit dem höchsten Jahresgewinn in diesem Diagramm und den größten Geschäftsbereich dieses Unternehmens.
Modellausgabe.
Sony hat mit $6,3 Mrd. den höchsten Jahresgewinn. Für Sony heißt es in der Notiz: "Medien sind Sonys zweitgrößtes Segment nach Spielkonsolen", das größte Segment sind also Spielkonsolen. Das größte Segment sind also Spielkonsolen.
Beispiel 2: Lösen von GCE Level Matheaufgaben

Eingabebefehl.
Bitte helfen Sie mir bei diesem Thema, indem Sie einen detaillierten Prozess und eine Antwort geben.
Modell-Output (partieller Argumentationsprozess).
- Es ist bekannt, dass PA ⊥ Ebene ABCD, also PA ⊥ AD und PA ⊥ AB.
- Da AB ⊥ AD und der Schnittpunkt von PA und AB A ist, ist AD ⊥ Ebene PAB.
- Da AD ⊂ Ebene PAD, Ebene PAB ⊥ Ebene PAD.
Beispiel 3: Identifizierung und Bedienung der grafischen Benutzeroberfläche (GUI)

Eingabebefehl.
Helfen Sie mir in der APP, ein Treffen mit Dr. Smith in vierzehn Tagen um 15 Uhr zu organisieren.
Modellausgänge (Betriebsanleitung).
Action: {“action_type”: “click”, “box_2d”: [[27,840,122,885]]}
Beispiel 4: Anhand des Bildes wird der Front-End-Webcode generiert
Diese Funktion zeigt die leistungsstarke Fähigkeit des Modells, visuelle Entwürfe direkt in brauchbaren Code zu übersetzen, was die Effizienz der Front-End-Entwicklung erheblich steigert.
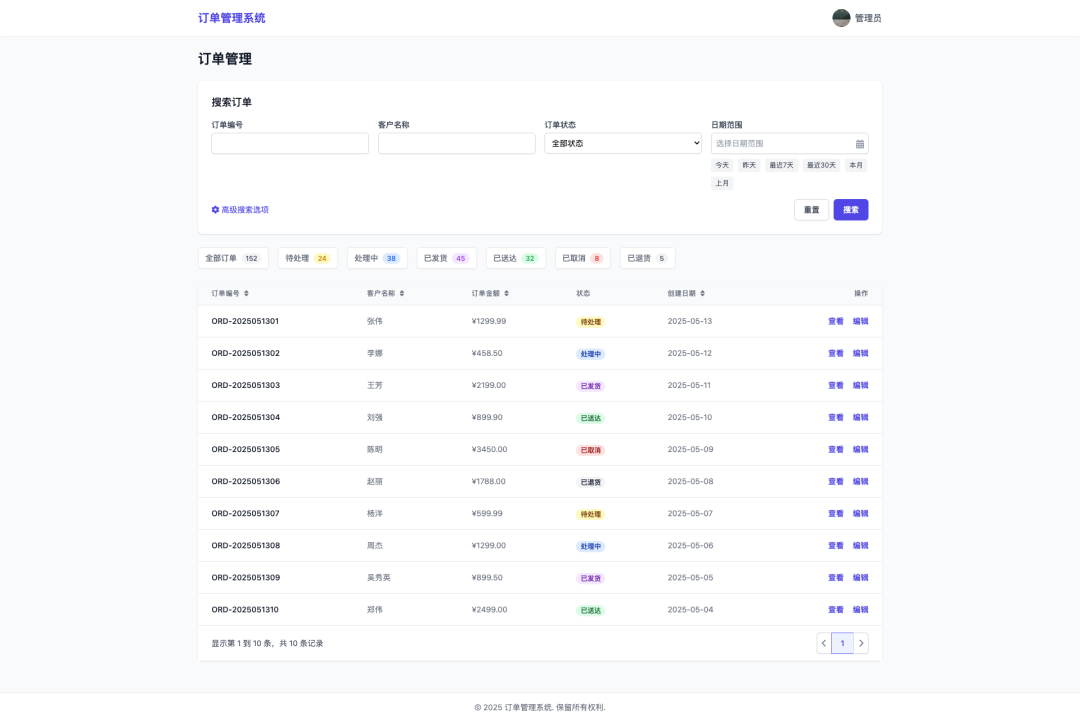
Eingabebefehl.
Bitte erstellen Sie eine Webseite ähnlich dem Eingabebild und konvertieren Sie sie in eine React Code.
Modell-generierter React-Code.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>订单管理系统</title>
<script src="https://cdn.jsdelivr.net/npm/react@18.0.0/umd/react.development.js"></script>
<script src="https://cdn.jsdelivr.net/npm/react-dom@18.0.0/umd/react-dom.development.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@babel/standalone/babel.js"></script>
<script src="https://cdn.tailwindcss.com"></script>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css"></link>
<link href="https://fonts.geekzu.org/css2?family=Noto+Sans+SC:wght@400;500;700&display=swap" rel="stylesheet">
<style>
body {
font-family: 'Noto Sans SC', sans-serif;
background-color: #f5f5f5;
}
</style>
</head>
<body>
<div id="root"></div>
<script type="text/babel">
const Header = () => {
return (
<header className="bg-white shadow-sm py-4 px-6 flex justify-between items-center border-b">
<h1 className="text-xl font-medium text-indigo-600">订单管理系统</h1>
<div className="flex items-center">
<img src="https://placehold.co/32x32" alt="管理员头像" className="w-8 h-8 rounded-full mr-2" />
<span>管理员</span>
</div>
</header>
);
};
const SearchForm = () => {
return (
<div className="bg-white rounded-md shadow-sm p-6 mb-4">
<h2 className="text-lg font-medium mb-4">搜索订单</h2>
<div className="grid grid-cols-1 md:grid-cols-4 gap-4">
<div>
<label className="block text-sm mb-1">订单编号</label>
<input type="text" className="w-full border rounded-md px-3 py-2" />
</div>
<div>
<label className="block text-sm mb-1">客户名称</label>
<input type="text" className="w-full border rounded-md px-3 py-2" />
</div>
<div>
<label className="block text-sm mb-1">订单状态</label>
<select className="w-full border rounded-md px-3 py-2 appearance-none bg-white">
<option>全部状态</option>
</select>
</div>
<div>
<label className="block text-sm mb-1">日期范围</label>
<div className="relative">
<input type="text" placeholder="选择日期范围" className="w-full border rounded-md px-3 py-2" />
<div className="absolute right-2 top-2 text-gray-400">
<i className="fas fa-calendar"></i>
</div>
</div>
<div className="flex flex-wrap mt-2 gap-2">
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">今天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">昨天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">最近7天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">最近30天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">本月</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">上月</button>
</div>
</div>
</div>
<div className="flex items-center justify-between mt-4">
<a href="#" className="text-indigo-600 flex items-center text-sm">
<i className="fas fa-cog mr-1"></i> 高级搜索选项
</a>
<div className="flex gap-2">
<button className="px-4 py-2 border rounded-md text-sm">重置</button>
<button className="px-4 py-2 bg-indigo-600 text-white rounded-md text-sm">搜索</button>
</div>
</div>
</div>
);
};
const OrderStatusFilters = () => {
const filters = [
{ name: "全部订单", count: 152, active: true },
{ name: "待处理", count: 24, active: false },
{ name: "处理中", count: 38, active: false },
{ name: "已发货", count: 45, active: false },
{ name: "已送达", count: 32, active: false },
{ name: "已取消", count: 8, active: false },
{ name: "已退货", count: 5, active: false },
];
return (
<div className="flex flex-wrap gap-2 mb-4">
{filters.map((filter, index) => (
<button
key={index}
className={`px-4 py-2 rounded-md text-sm ${
filter.active
? "bg-indigo-100 text-indigo-700"
: "bg-white border"
}`}
>
{filter.name} {filter.count > 0 && <span className="ml-1">{filter.count}</span>}
</button>
))}
</div>
);
};
const OrderTable = () => {
const orders = [
{ id: "ORD-2025051301", customer: "张伟", amount: "¥1299.99", status: "待处理", date: "2025-05-13" },
{ id: "ORD-2025051302", customer: "李娜", amount: "¥458.50", status: "处理中", date: "2025-05-12" },
{ id: "ORD-2025051303", customer: "王芳", amount: "¥2199.00", status: "已发货", date: "2025-05-11" },
{ id: "ORD-2025051304", customer: "刘强", amount: "¥899.90", status: "已送达", date: "2025-05-10" },
{ id: "ORD-2025051305", customer: "陈明", amount: "¥3450.00", status: "已取消", date: "2025-05-09" },
{ id: "ORD-2025051306", customer: "赵丽", amount: "¥1788.00", status: "已退货", date: "2025-05-08" },
{ id: "ORD-2025051307", customer: "杨洋", amount: "¥599.99", status: "待处理", date: "2025-05-07" },
{ id: "ORD-2025051308", customer: "周杰", amount: "¥1299.00", status: "处理中", date: "2025-05-06" },
{ id: "ORD-2025051309", customer: "吴秀英", amount: "¥899.50", status: "已发货", date: "2025-05-05" },
{ id: "ORD-2025051310", customer: "郑伟", amount: "¥2499.00", status: "已送达", date: "2025-05-04" },
];
const getStatusClass = (status) => {
switch(status) {
case "待处理": return "bg-yellow-100 text-yellow-800";
case "处理中": return "bg-blue-100 text-blue-800";
case "已发货": return "bg-purple-100 text-purple-800";
case "已送达": return "bg-green-100 text-green-800";
case "已取消": return "bg-red-100 text-red-800";
case "已退货": return "bg-gray-100 text-gray-800";
default: return "bg-gray-100 text-gray-800";
}
};
return (
<div className="overflow-x-auto">
<table className="min-w-full bg-white">
<thead>
<tr className="bg-gray-50 text-left text-sm">
<th className="px-6 py-3 font-medium text-gray-500">订单编号 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">客户名称 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">订单金额 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">状态 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">创建日期 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">操作</th>
</tr>
</thead>
<tbody className="divide-y divide-gray-200">
{orders.map((order, index) => (
<tr key={index} className="hover:bg-gray-50">
<td className="px-6 py-4 text-sm">{order.id}</td>
<td className="px-6 py-4 text-sm">{order.customer}</td>
<td className="px-6 py-4 text-sm">{order.amount}</td>
<td className="px-6 py-4">
<span className={`px-2 py-1 rounded-full text-xs ${getStatusClass(order.status)}`}>
{order.status}
</span>
</td>
<td className="px-6 py-4 text-sm">{order.date}</td>
<td className="px-6 py-4 text-sm">
<button className="text-indigo-600 mr-3">查看</button>
<button className="text-indigo-600">编辑</button>
</td>
</tr>
))}
</tbody>
</table>
</div>
);
};
const Pagination = () => {
return (
<div className="flex items-center justify-between mt-4 text-sm">
<div>显示第 1 到 10 条,共 10 条记录</div>
<div className="flex items-center">
<button className="px-3 py-1 border rounded-l-md">
<i className="fas fa-chevron-left"></i>
</button>
<button className="px-3 py-1 border-t border-b bg-indigo-100 text-indigo-600">1</button>
<button className="px-3 py-1 border rounded-r-md">
<i className="fas fa-chevron-right"></i>
</button>
</div>
</div>
);
};
const Footer = () => {
return (
<footer className="py-4 text-center text-gray-500 text-sm">
© 2025 订单管理系统. 保留所有权利.
</footer>
);
};
const App = () => {
return (
<div className="min-h-screen flex flex-col">
<Header />
<main className="flex-1 max-w-7xl mx-auto w-full px-4 py-6">
<h1 className="text-2xl font-medium mb-6">订单管理</h1>
<SearchForm />
<OrderStatusFilters />
<OrderTable />
<Pagination />
</main>
<Footer />
</div>
);
};
ReactDOM.render(<App />, document.getElementById('root'));
</script>
</body>
</html>
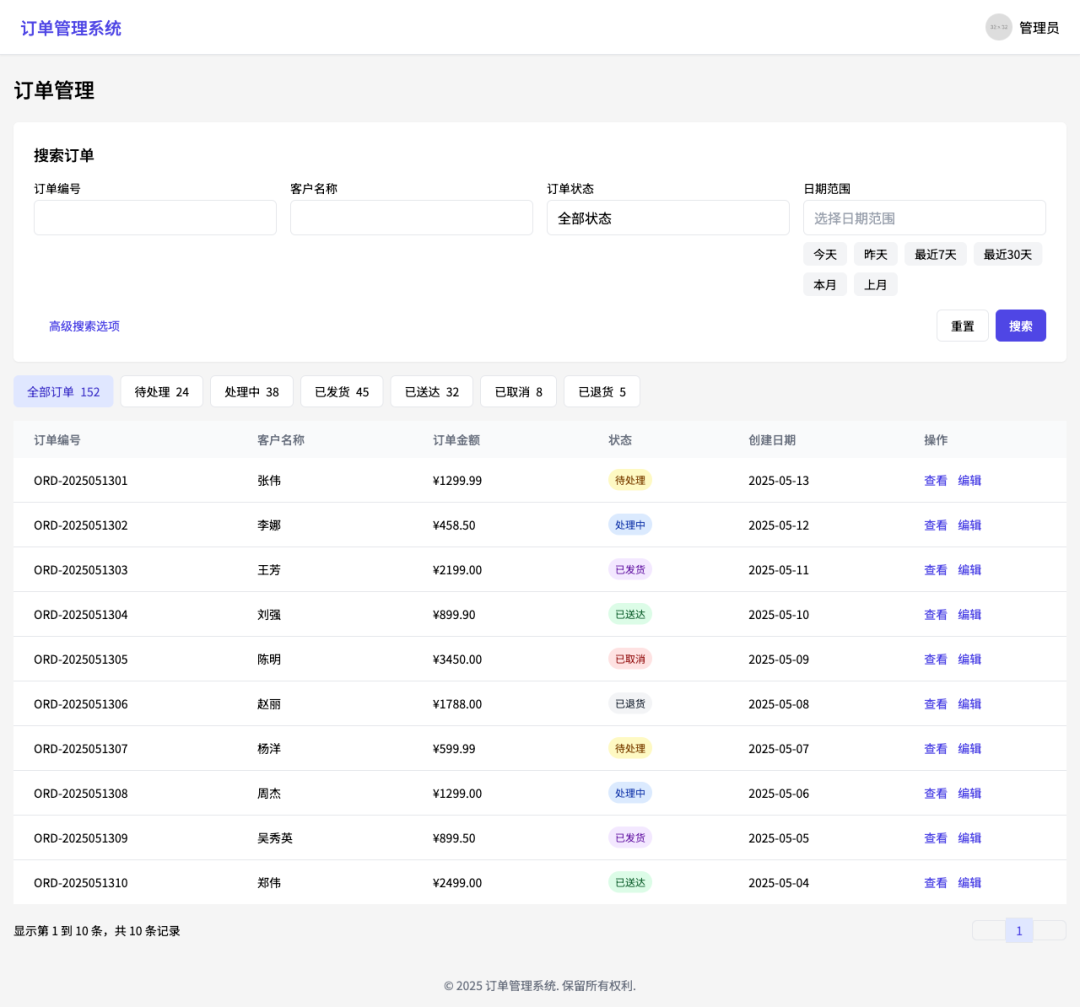
Beispiel 5: Prinzipielle Analyse von physikalischen Phänomenen
Eingabebefehl.
Was ist der Grund für dieses Phänomen? Warum befindet sich Wasser in der mittleren Tasse?
Modellausgabe.
Dieses Phänomen ist auf das **Kapillarphänomen (oder die Kapillarwirkung)** zurückzuführen. Konkret: Seidenpapier ist ein poröses Material, und die Lücken zwischen seinen Fasern sind ähnlich wie "Kapillaren". Wenn der linke und der rechte Becher, die verschiedenfarbige Flüssigkeiten enthalten, durch ein Papiertuch mit dem leeren Becher in der Mitte verbunden sind, wird das Papiertuch die rote Flüssigkeit auf der linken Seite und die blaue Flüssigkeit auf der rechten Seite durch die Lücken in den Fasern zum leeren Becher in der Mitte transportieren, indem es die eigene Wasseraufnahmefähigkeit des Papiertuchs und die Kapillarität zwischen den Fasern nutzt. Im Laufe dieses Transportvorgangs füllt sich der leere Becher in der Mitte allmählich mit Flüssigkeit, was zu dem Phänomen des "Wassers im mittleren Becher" führt.
Technische Struktur und Ausbildungsmethodik
GLM-4.1V-Thinking Die effiziente Leistung ist auf die verfeinerte Modellarchitektur und den stufenweisen Trainingsprozess zurückzuführen.
Modellarchitektur
Die Modellarchitektur besteht aus drei Teilen: einem visuellen Encoder (ViT Encoder), einem Adapter (MLP Projector) und einem Sprachdecoder.
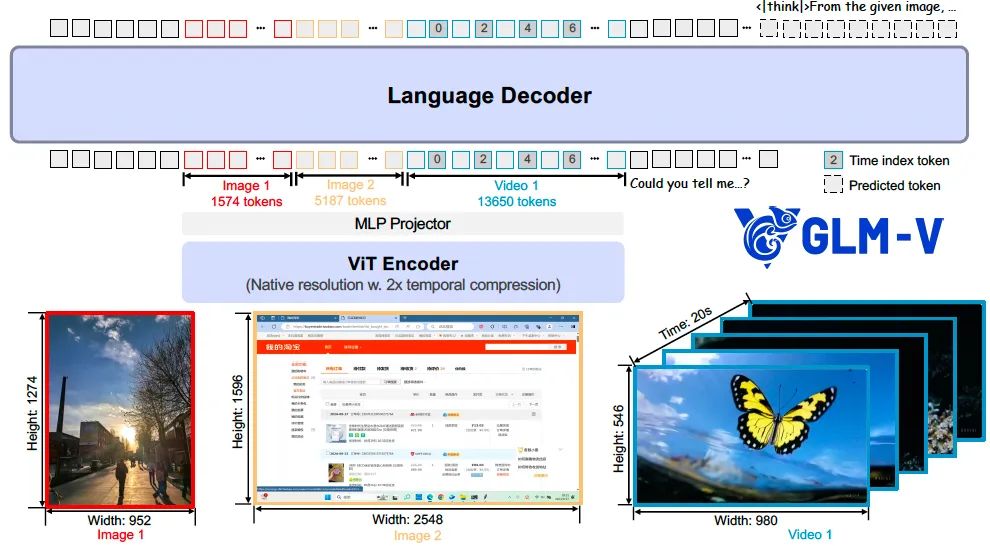
Das Modell wurde ausgewählt AIMv2-Huge als visueller Kodierer, und die 2D-Faltung wird darin in 3D erweitert, um die zeitliche Dimension des Videoinputs effizient zu behandeln. Das Modell wird in zwei wesentlichen Punkten verbessert, um seine Anpassungsfähigkeit an Bilder mit beliebiger Auflösung und beliebigem Seitenverhältnis zu erhöhen:
- Zweidimensionale Rotationspositionskodierung (2D-RoPE). Diese Technologie hilft dem Modell, die räumlichen Beziehungen innerhalb eines Bildes besser zu verstehen, so dass es extreme Seitenverhältnisse von über 200:1 und hochauflösende Bilder über 4K stabilisieren kann.
- Dynamische Auflösungsanpassung. Durch die Beibehaltung der absoluten Positionseinbettung des vortrainierten ViT-Modells und die Kombination mit doppelter kubischer Interpolation kann das Modell während des Trainings dynamisch an Eingaben mit unterschiedlichen Auflösungen angepasst werden.
Im Abschnitt Sprachdecoder erweitert das Modell die ursprüngliche Rotationspositionskodierung (RoPE) um Dreidimensionale Rotationspositionskodierung (3D-RoPE)die das räumliche Verständnis des Modells bei der Verarbeitung gemischter Grafik-/Videoeingaben erheblich verbessert, ohne die Leistung bei der Verarbeitung von reinem Text zu beeinträchtigen.
Ausbildungsprozess
Das Training des Modells ist in drei Phasen unterteilt: Pre-Training, überwachtes Fine-Tuning (SFT) und Reinforcement Learning (RL).
- Vorschulungsphase. Es ist in zwei Unterphasen unterteilt: allgemeines multimodales Vortraining und kontinuierliches Training mit langem Kontext. Ersteres zielt darauf ab, ein grundlegendes multimodales Verständnis aufzubauen; letzteres erweitert die Verarbeitungssequenzlänge des Modells auf 32.768, indem Videobildsequenzen und sehr lange grafische Inhalte eingeführt werden, um die Verarbeitung von hochauflösenden und langen Videos zu verbessern.
- Phase der überwachten Feinabstimmung (SFT). In dieser Phase wird das Modell mit Hilfe eines hochwertigen Chain-of-Thought-Datensatzes (CoT) vollständig parametrisch abgestimmt. Alle Trainingsbeispiele haben ein einheitliches Format und zwingen das Modell zu lernen, detaillierte Argumentationsprozesse zu generieren, anstatt direkte Antworten zu geben.
<think> {推理过程} </think> <answer> {最终答案} </answer>Dieser Schritt stärkt die Fähigkeit des Modells, über lange Zeiträume hinweg kausal zu denken.
- Kursstichprobe Intensivlernen (RLCS) Phase. Dies ist der Schlüssel zur Verbesserung der Leistung des Modells. Auf der Grundlage des überwachten, fein abgestimmten Modells kombinierte das Entwicklungsteam Reinforcement Learning based on Verifiable Rewards (RLVR) und Reinforcement Learning based on Human Feedback (RLHF). Unter Verwendung eines "Course Sampling"-Mechanismus beginnt das Modell mit einfachen Aufgaben in mehreren Dimensionen, wie z. B. MINT-Problemlösung, GUI-Interaktion und Dokumentenverständnis, und geht dann schrittweise zu komplexen Aufgaben über. Dieses dynamische Lernparadigma von einfach bis schwierig optimiert die Leistung des Modells in Bezug auf Nutzen, Genauigkeit und Stabilität.






































