

Beim Aufbau von Wissensbasis-Quiz-Anwendungen auf der Grundlage großer Sprachmodelle (Large Language Models, LLMs) verwenden die Entwickler üblicherweise Retrieval Augmented Generation (RAG)-Techniken. Die praktische Effektivität von RAG wird jedoch oft durch ein zentrales Paradoxon eingeschränkt: Wie kann die Abfrage derPräzisionkontextabhängigVollständigkeitWenn der Textabschnitt zu klein ist, kann er zwar die Anfrage des Benutzers genau treffen, aber er bietet nicht genügend Kontext für den LLM, was zu einer Verringerung der Antwortqualität führt. Wenn der Textabschnitt (Chunk) zu klein ist, kann er zwar die Benutzerabfrage genau treffen, aber der Kontext, der dem LLM zur Verfügung gestellt wird, ist unzureichend, was zu einer Verringerung der Qualität der Antwort führt; wenn der Abschnitt zu groß ist, kann er, obwohl der Kontext vollständig ist, zu viel Rauschen einbringen, was wiederum die Genauigkeit der Abfrage verringert.
Um diese Herausforderung zu bewältigen. Dify Eingeführt in Version 1.9.0 als neue Funktion namens Parent-child-HQ Eine integrierte Pipeline-Vorlage für die Wissensverarbeitung. Die Vorlage verwendet die "Parent-Child Chunking"-Strategie (Eltern-Kind-Chunking) durch eine clevere hierarchische Chunking-Methode, die versucht, sowohl den Fisch als auch die Bärentatze gleichzeitig zu erreichen. In diesem Beitrag werden wir diese Funktion anhand des Kernkonzepts, der praktischen Konfiguration und der Quellcode-Implementierung auf drei Ebenen analysieren.
Kernkonzept: Vater-Sohn-Chunking-Strategie
Die Kernidee der "Parent-Child Chunking"-Strategie besteht darin, die Textinformationen für die Verarbeitung in zwei Ebenen zu strukturieren, um die unterschiedlichen Anforderungen an die Textgranularität zwischen dem Abrufabgleich und der Inhaltserstellung zu entkoppeln.
- Child Chunks für exakten AbgleichDas Originaldokument wird in eine Reihe feinkörniger, hochkonzentrierter "Chunks" aufgeteilt. Diese Teilstücke bestehen in der Regel aus einem Satz oder einem kurzen Absatz und werden ausschließlich für die Berechnung der semantischen Ähnlichkeit mit dem Suchvektor des Nutzers verwendet. Aufgrund ihrer geringen Granularität können sehr genaue Übereinstimmungen erzielt werden.
- Parent Chunks werden verwendet, um den vollständigen Kontext zu liefernJeder Sub-Chunk gehört zu einem größeren "Parent", bei dem es sich um einen kompletten Absatz, einen Abschnitt oder sogar ein ganzes Dokument handeln kann. Sobald das System die relevantesten Treffer in den untergeordneten Chunks gefunden hat, wird der gesamte "übergeordnete Chunk", der die untergeordneten Chunks enthält, zur Inhaltsgenerierung in den LLM eingespeist.
Dieser Mechanismus stellt sicher, dass das LLM bei der Beantwortung einer Frage den vollständigsten ursprünglichen Kontext "liest", in dem sich die passenden Informationen befinden, und so eine logisch kohärente und informative Antwort erzeugt.
Diese fortschrittliche Strategie stützt sich auf das Vektor-Retrieval, um die semantische Ähnlichkeit zu berechnen, und unterstützt daher nur die Dify-Wissensbasis in der HQ (Hohe Qualität) Indizierungsmodus. Der qualitativ hochwertige Modus vektorisiert den Text mit Hilfe des Einbettungsmodells und unterstützt das Vektorsuchverfahren und das hybride Suchverfahren, während der wirtschaftliche Modus nur einen invertierten Index auf der Grundlage von Schlüsselwörtern erstellt, der die operativen Anforderungen des Parent-Child-Chunking nicht erfüllen kann.

Praxisanleitung: Konfigurieren der Parent-Child-HQ-Wissensdatenbank
Um diese Funktion in Dify zu nutzen, müssen Sie zunächst die Parent-child-HQ Diese Wissensbasis behandelt Prozessvorlagen.
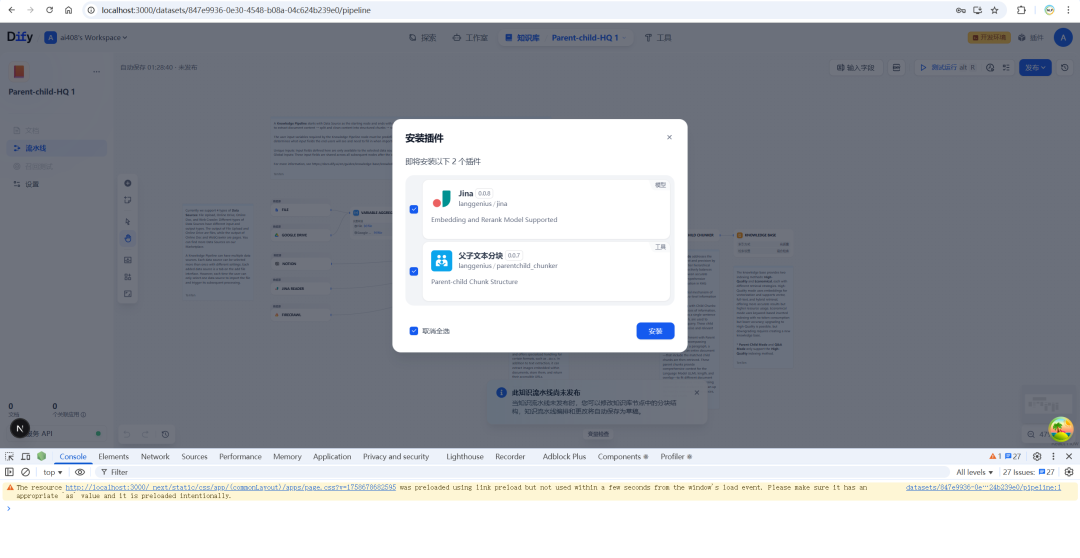
Nach der Installation ist der zentralste Knoten in der Pipeline der "Parent-Child-Textchunk".
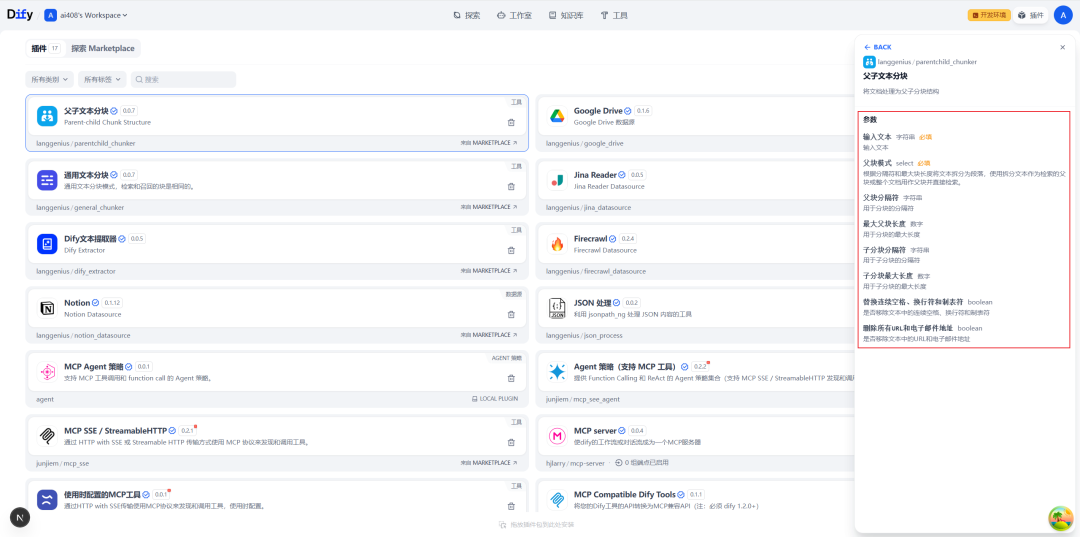
Konfiguration des Chunking-Knotens
Im Einstellungsbild dieses Knotens können Sie die Aufteilungsregeln für übergeordnete und untergeordnete Blöcke im Detail festlegen.
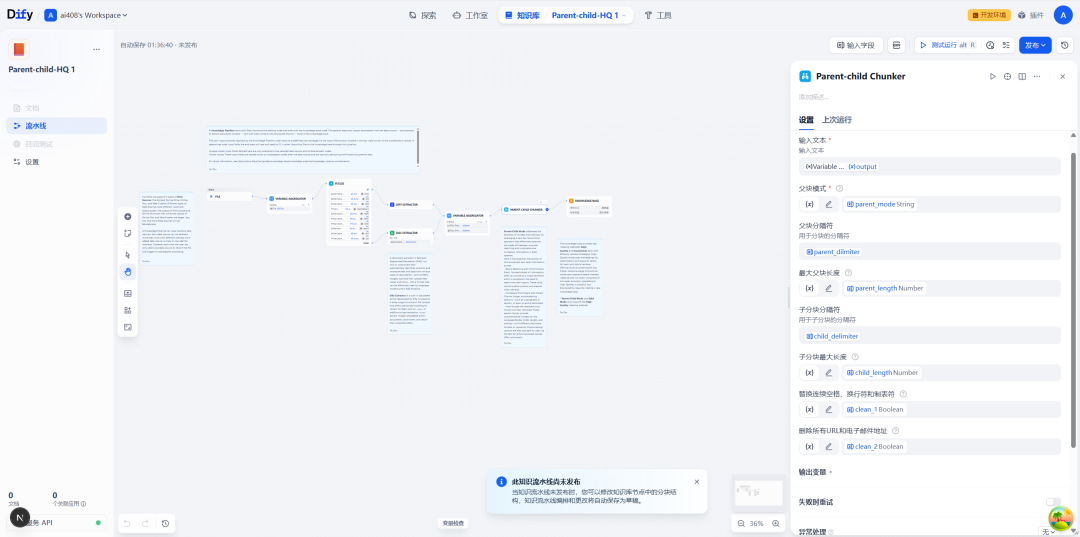
| Konfigurationsobjekt | Anweisungen |
|---|---|
| Trennzeichen für übergeordnete Abschnitte | Legt fest, wie der übergeordnete Block ausgeschnitten werden soll. Dies geschieht in der Regel mit der Option \n\n(zwei Zeilenumbrüche), um nach Absätzen zu trennen. |
| Maximale Länge des übergeordneten Chunks | Maximale Zeichenanzahl für einen einzelnen übergeordneten Block. |
| Unterschachtabscheider | Legt fest, wie Unterblöcke innerhalb des übergeordneten Blocks weiter unterteilt werden sollen. Dies kann mit der Option \n(einzelnes Zeilenumbruchzeichen) Zeilenweise Trennung. |
| Maximale Subchunk-Länge | Maximale Zeichenanzahl für einen einzelnen Teilblock. |
| übergeordnetes Blockmodell | Definieren Sie den Geltungsbereich des übergeordneten Blocks, stellen Sie paragraph(Absätze) und full_doc(vollständige Dokumentation) zwei Modi. |
In diesem Fall bestimmt das "Elternblockmuster" die Makrogrenze des Kontexts:
- Absatzmuster (
paragraph mode)Text in mehrere übergeordnete Blöcke nach Trennzeichen (z. B. Absatz) aufteilen. Dies ist der am häufigsten verwendete Modus, der ein gutes Gleichgewicht zwischen Präzision und kontextuellem Umfang herstellt. - Volltextmodus (
full_doc mode)das gesamte Dokument als einen großen übergeordneten Block behandeln (über 10.000) tokens (der Teil, der abgeschnitten wird). Dieser Modus eignet sich für bestimmte Szenarien, in denen ein globaler Kontext erforderlich ist.
Darüber hinaus unterstützen die Vorverarbeitungsoptionen das Entfernen von zusätzlichen Leerzeichen, URLs und E-Mail-Adressen aus dem Text, um die Datenqualität zu verbessern.
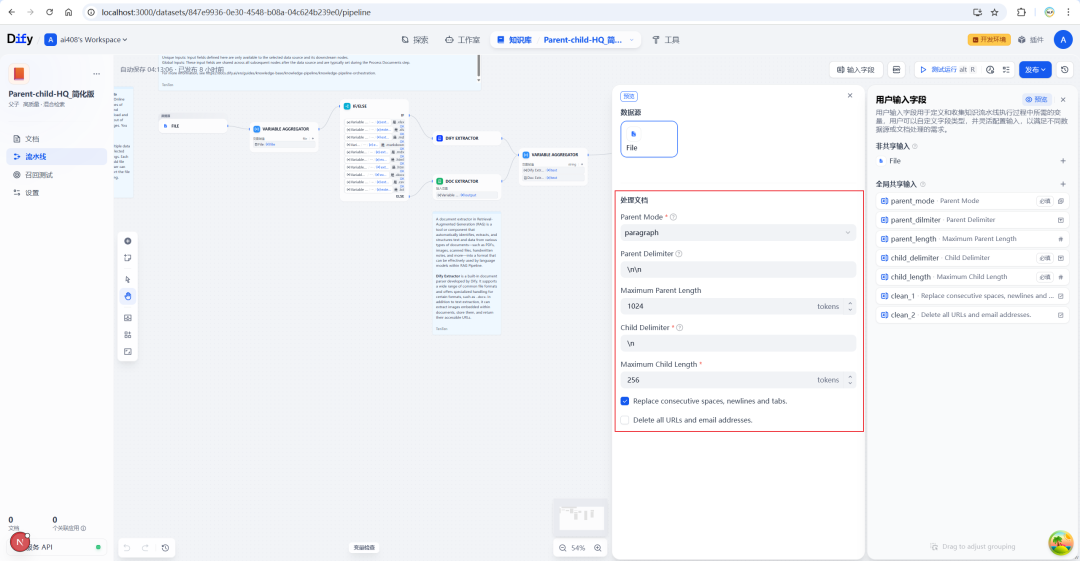
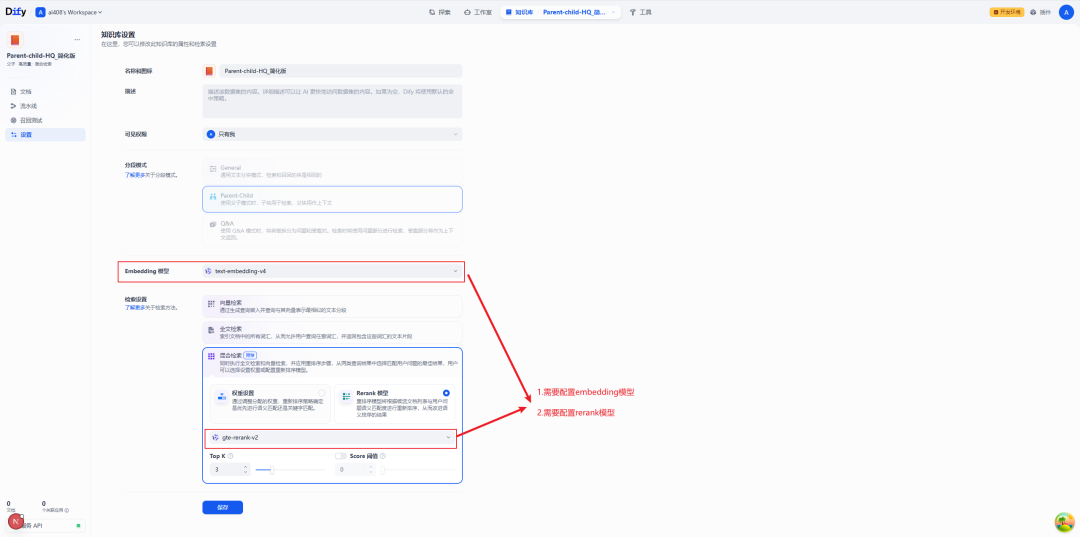
Aufbau eines hochwertigen Index
Wie bereits erwähnt.Parent-Child Das Modell muss in Verbindung mit dem HQ-Index verwendet werden. Daher müssen Sie das Einbettungsmodell und das Rerank-Modell in den Einstellungen der Wissensdatenbank konfigurieren.
Inbetriebnahme und Betrieb
Nachdem Sie alle Konfigurationen vorgenommen haben, können Sie den Chunking-Effekt mithilfe der Debugging-Funktion testen. Geben Sie den Beispieltext ein und führen Sie die Pipeline aus, um deutlich zu sehen, wie der ursprüngliche Text in Eltern-Kind-Strukturen organisiert ist.
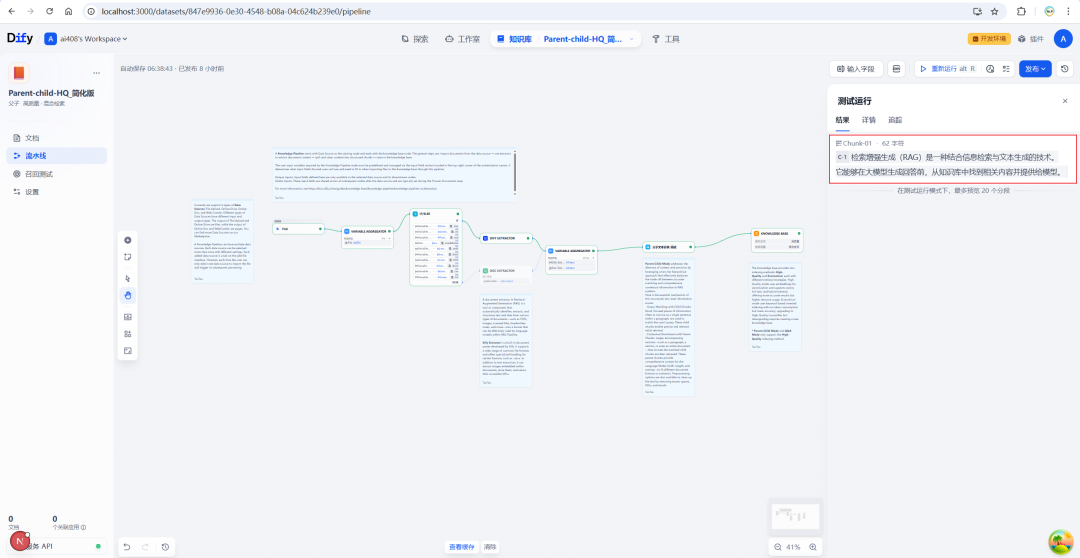
Der abschließende Lauf führt zu einer strukturierten Darstellung des übergeordneten Blocks und der Liste der darin enthaltenen untergeordneten Blöcke.
Vertiefung der Architektur: Implementierungslogik auf der Code-Ebene
Um besser zu verstehen, wie es funktioniert, tauchen wir ein in die parentchild_chunker Der Quellcode des Plug-ins wird analysiert. Das nachstehende UML-Zeitdiagramm fasst den gesamten Ablauf des Plug-ins vom Start über den Empfang von Daten bis hin zur Verarbeitung und Rückgabe der Ergebnisse zusammen.
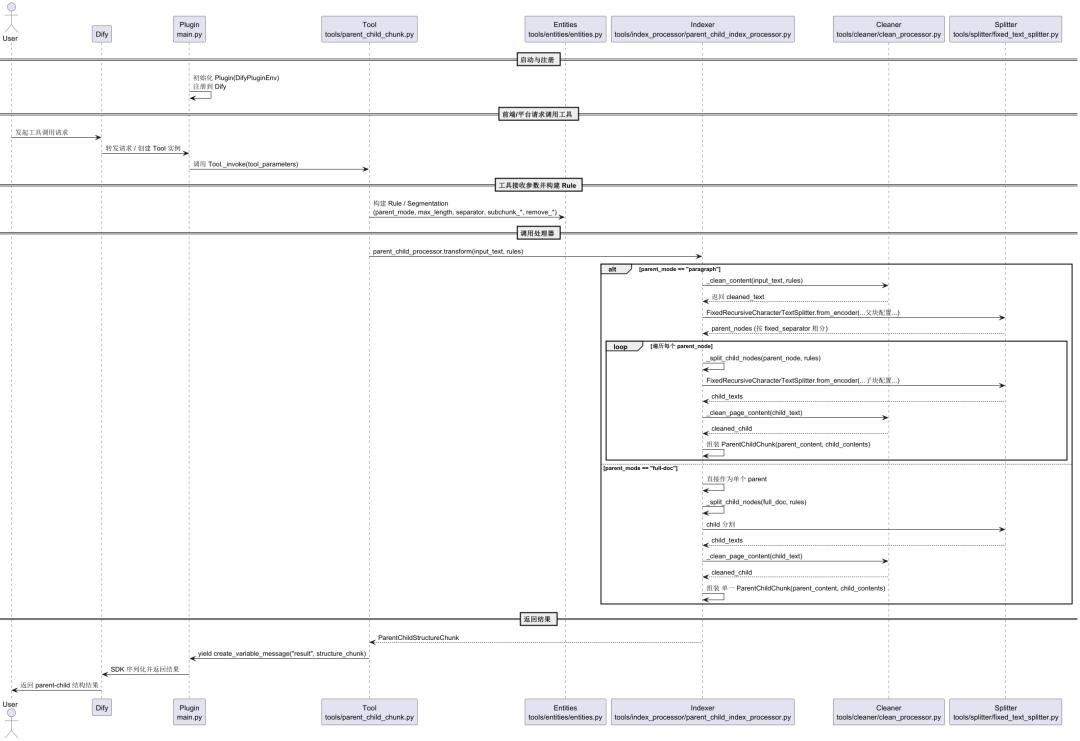
Der gesamte Prozess der Datenverarbeitung lässt sich in den folgenden Hauptschritten zusammenfassen:
1. der Start des Plug-ins und der Aufruf des Tools
Wenn die Dify Plattform gestartet wird.main.py Datei dient als Einstiegspunkt für das Plugin und ist verantwortlich für die Initialisierung und Registrierung bei Dify ParentChildChunkTool Die Fähigkeiten des Die Front-End-Formulare, Eingabeparameter und Ausgabeformate des Tools werden von der tools/parent_child_chunk.yaml Datei-Definition.
Wenn der Benutzer das Werkzeug aufruft, instanziiert das Dify SDK die tools/parent_child_chunk.py definiert in ParentChildChunkTool Klasse und rufen deren _invoke Methode, die die vom Front-End übergebenen Parameter (z. B. die input_text、parent_mode usw.) übergeben.
2) Kernverarbeitung und Textbereinigung
_invoke Die Hauptaufgabe der Methode ist der Aufruf der tools/index_processor/parent_child_index_processor.py definiert in ParentChildIndexProcessorSie ist der Dreh- und Angelpunkt der gesamten Geschäftslogik. Dies ist der Dreh- und Angelpunkt der gesamten Geschäftslogik.
Vor dem Chunking durchläuft der Text zunächst die tools/cleaner/clean_processor.py den Nagel auf den Kopf treffen CleanProcessor Bereinigung. Dieses Modul ist für die Entfernung ungültiger Zeichen und die selektive Zusammenführung überflüssiger Leerzeichen oder die Entfernung von URLs und E-Mail-Adressen entsprechend der Konfiguration des Benutzers zuständig, wodurch die Qualität des anschließend verarbeiteten Textes gewährleistet wird.
3. intelligente Textsegmentierung
Die Textsegmentierung ist der technische Kern der Parent-Child-Chunking-Strategie und wird hauptsächlich von der tools/splitter/ Mehrere Splitter-Implementierungen im Katalog. Unter ihnen ist derFixedRecursiveCharacterTextSplitter ist der Schlüssel.
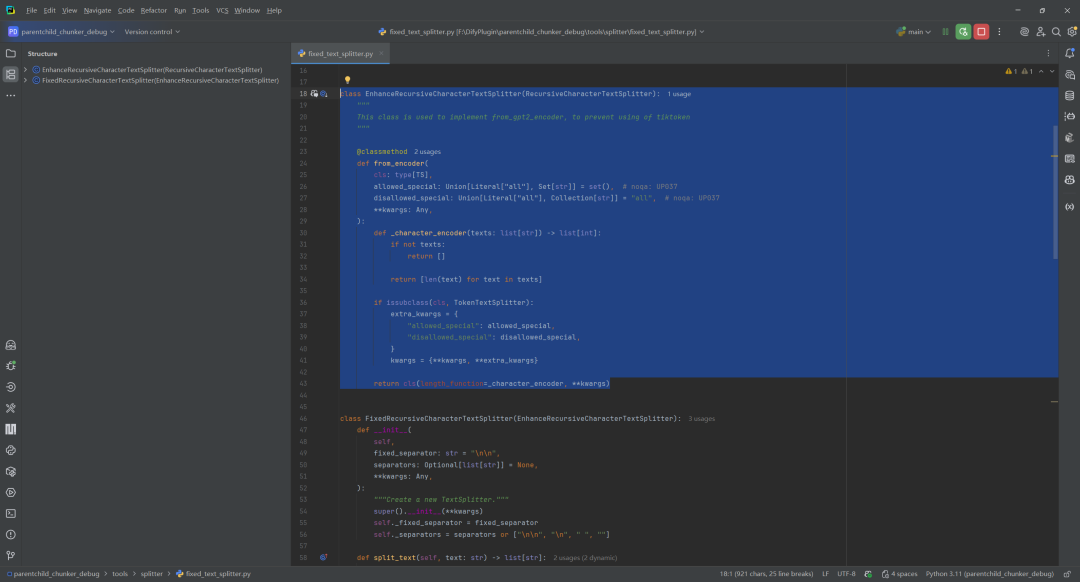
Hier sind zwei Hauptgruppen zu unterscheiden:
EnhanceRecursiveCharacterTextSplitterDie Hauptverbesserung besteht darin, dass es eine Möglichkeit bietet, ein neues System auf der Grundlage der Anzahl der Zeichen zu erstellen (anstelle dertiktoken) berechnet die Textlänge auf eine Weise, die die Abhängigkeit von einem bestimmten Tokenisierer vermeidet. Die Segmentierungslogik ist mit rekursiven Standardzeichensegmentierern konsistent.FixedRecursiveCharacterTextSplitterDiese Klasse fügt der rekursiven Partitionierung einen wichtigen Schritt hinzu - dieBeginnen Sie mit der Verwendung eines festen, hochprioritärenfixed_separator(z. B. für die Absätze\n\n), um die erste Teilung vorzunehmen. Dann wird die interne rekursive Logik erneut aufgerufen, um nur die Blöcke zu unterteilen, die die Längengrenze überschreiten.
Diese Strategie der "groben Unterteilung und anschließenden Verfeinerung" entspricht perfekt den Erfordernissen des Eltern-Kind-Chunking: zunächst durch die \n\n Trennen Sie den semantisch vollständigen übergeordneten Block (Absatz), und verwenden Sie dann feinere Trennzeichen innerhalb des übergeordneten Blocks (z. B. \n) Schneiden Sie Teilblöcke aus.
4 Aufbau der Datenstruktur und Rückgabe
Nach Reinigung und SpaltungParentChildIndexProcessor wird sich stützen auf paragraph 或 full-doc Muster, das eine Liste der Inhalte von Elternblöcken und der entsprechenden Inhalte von Kindblöcken in der Datei ParentChildChunk Objekte. Diese Objekte werden schließlich in der ParentChildStructureChunk in der Struktur.
Die Definitionen dieser Datenstrukturen befinden sich in der Datei tools/entities/entities.pyDurch die Verwendung des Pydantic-Modells wird sichergestellt, dass die Daten normalisiert und konsistent sind.
Endlich.ParentChildChunkTool passieren (eine Rechnung oder Inspektion etc.) yield self.create_variable_message(...) Rückgabe der verarbeiteten strukturierten Daten an das Dify SDK, um die Ausführung des gesamten Pipelineknotens abzuschließen.
Mit diesem gut durchdachten Verarbeitungsablauf und dem flexiblen Textsplitter kann dieParent-child-HQ Vorlagen bieten Entwicklern ein leistungsstarkes und elegantes Werkzeug, das das Problem der RAG Das anhaltende Dilemma zwischen Kontext und Genauigkeit in Anwendungen.





























