

Vorwort: Aufbau kosteneffizienter KI-Bilderzeugungs- und -bearbeitungsworkflows
lit. zehntausend Fragen zu allgemeinen Grundsätzen (Idiom); fig. eine lange Liste von Fragen und Antworten Qwen-Image Als Open-Source-Grafikmodell für die Texterzeugung hat es aufgrund seiner überragenden Fähigkeiten bei der Darstellung komplexer Texte, insbesondere chinesischer Schriftzeichen, große Aufmerksamkeit erregt. Im Vergleich zu herkömmlichen Modellen kann es mehrzeilige und mehrteilige Textinhalte präzise in Bilder einbetten, was neue Möglichkeiten für die Gestaltung von Postern, die Erstellung von Inhalten und andere Szenarien bietet.
Die Modelle selbst sind zwar quelloffen, aber die Kosten für die Inanspruchnahme solcher Dienste durch kommerzielle Plattformen sind oft erheblich. So können beispielsweise Plug-in-Dienste, die von einigen Plattformen angeboten werden, bis zu 0,25 $ pro Bild kosten, wenn das kostenlose Kontingent erschöpft ist. Dies ist ein erheblicher Mehraufwand für Benutzer, die große Mengen erzeugen oder häufig wiederholen müssen.
In diesem Papier wird ein alternatives Szenario untersucht, das darauf abzielt, die Vorteile der Dify Plattform zur Orchestrierung von Anwendungen,ModelScope(Magic Match Community) Qwen-Image Plugin und dem Tencent Cloud Object Storage (COS), um eine leistungsfähige und kosteneffektive Bilderzeugungs- und -bearbeitungsintelligenz (Agent) zu entwickeln. Das Endergebnis sieht folgendermaßen aus: Der Agent generiert nicht nur Bilder auf der Grundlage von Text, sondern verändert auch die generierten Bilder in nachfolgenden Dialogen.

Vorbereitung der Systemeinrichtung
Bevor mit dem Aufbau begonnen werden kann, müssen mehrere wichtige Komponenten und Dienste bereitstehen. Der Kern des gesamten Systems ist Dify Plattform Qwen Text2Image & Image2Image Plug-ins.
1. dify Plugin-Marktplatz und Qwen-Image Plugin
Dify ist eine offene Quelle LLM Plattform zur Anwendungsentwicklung, die es den Nutzern ermöglicht, Anwendungen über eine visualisierte Schnittstelle zu orchestrieren und zu erstellen AI Anwendung. Zunächst ist es erforderlich, die Dify Finden und downloaden Sie den Plugin-Marktplatz für Qwen Text2Image & Image2Image Plug-ins.
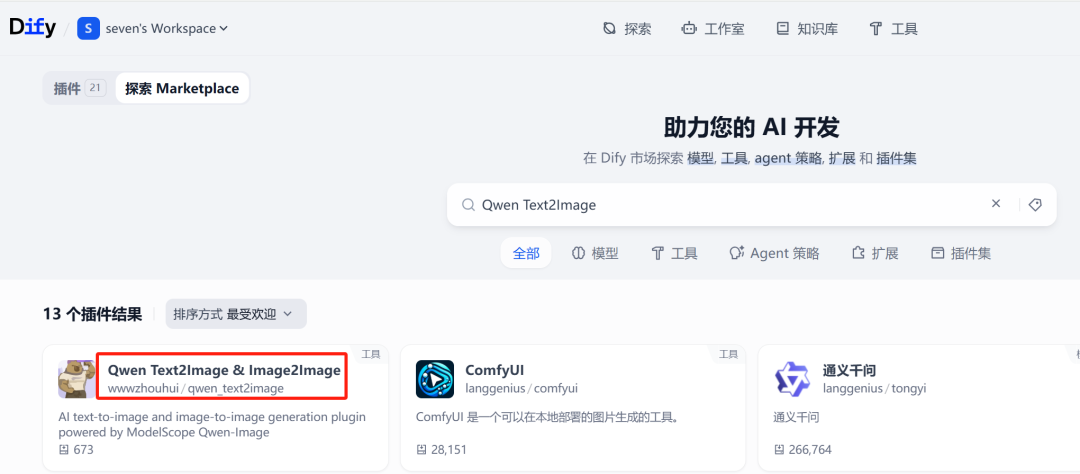
2. die Zugangsdaten für die ModelScope-Gemeinschaft
ModelScope(Magic Hitch Community) ist eine Open-Source-Modellierungs-Community unter Alibaba, die eine große Anzahl von vortrainierten Modellen und API Dienst. Zur Nutzung des Dify obere Qwen-Image Plugin, das eine ModelScope gemeindebasiert API Key als Zugangsberechtigung.
Sie kann über die ModelScope Holen Sie es sich im Personal Center der offiziellen Website API Key:https://modelscope.cn/my/myaccesstoken
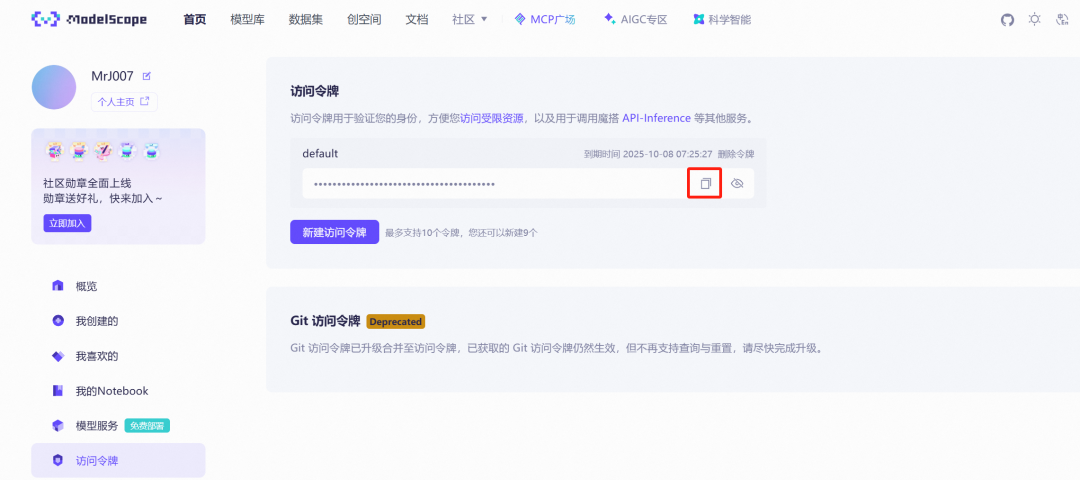
3. der Tencent Cloud Object Storage (COS)
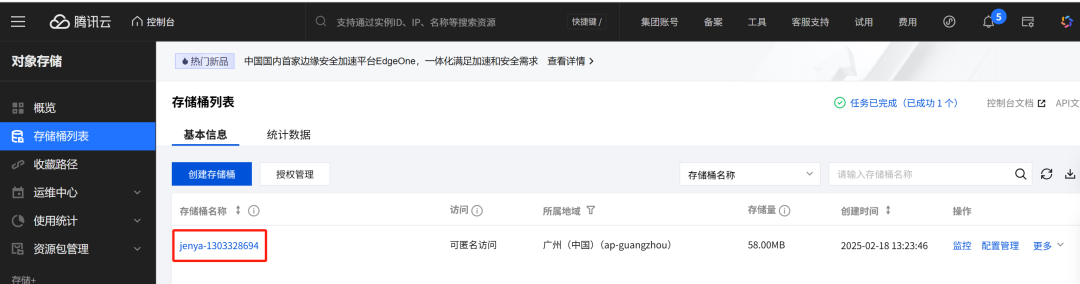
Qwen-Image Die Bildbearbeitungsfunktion (Bild zu Bild) setzt voraus, dass das eingegebene Originalbild über das öffentliche Netz zugänglich sein muss. URL Adresse. Um dieses Problem zu lösen, können Cloud-Speicherdienste genutzt werden. In diesem Papier wird Tencent Cloud Object Storage (COS), um die erzeugten Bilder zu speichern und öffentliche Links für sie zu erzeugen.
Sie müssen eine Tencent Cloud erstellen COS Bucket für nachfolgende Bild-Uploads. Der Konfigurationsprozess wird hier nicht beschrieben, stellen Sie nur sicher, dass das Bucket öffentlichen Lesezugriff hat.
Zugangsadresse:https://console.cloud.tencent.com/cos/bucket
4) API-Dienste für das Hochladen von Bildern
um zu berücksichtigen Dify Im Workflow erzeugte Bilder werden in die Tencent Cloud hochgeladen COSwird ein Zwischendienst benötigt, der als Brücke fungiert. Dieser Dienst empfängt Dify Sendet die Bilddatei, führt einen Upload-Vorgang durch und gibt dann das öffentliche Netzwerk des Bildes zurück URL。
Sie können die FastAPI Erstellen Sie schnell einen solchen Schnittstellendienst. Hier sind die Kern Python Code:
Sicherheitswarnung: Der folgende Beispielcode kodiert direkt die secret_id 和 secret_keyDies stellt ein erhebliches Sicherheitsrisiko dar. In einer Produktionsumgebung muss diedarf niemalsTun Sie dies. Es wird dringend empfohlen, Umgebungsvariablen, Konfigurationsdateien oder einen professionellen Schlüsselverwaltungsdienst zu verwenden, um diese sensiblen Anmeldedaten zu speichern und abzurufen.
import requests
import json
import base64
from PIL import Image
import io
import os
import sys
from qcloud_cos import CosConfig, CosS3Client
import datetime
import random
from fastapi import FastAPI, UploadFile, File
from pydantic import BaseModel
# --- 配置信息 ---
# 临时文件存储路径
output_path = "D:\\tmp\\zz"
# 腾讯云 COS 配置
region = "ap-guangzhou"
secret_id = "AKIDnRsFUYKwfNvHQQFsIj9WpwpWzEG5hAUi" # 替换为你的 SecretId
secret_key = "5xb1EF9*******ydFi1MYWHpMpBbtx" # 替换为你的 SecretKey
bucket = "jenya-130****694" # 替换为你的 Bucket 名称
app = FastAPI()
class GenerateImageRequest(BaseModel):
prompt: str
def generate_timestamp_filename(extension='png'):
"""根据时间戳和随机数生成唯一文件名"""
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
random_number = random.randint(1000, 9999)
filename = f"{timestamp}_{random_number}.{extension}"
return filename
def base64_to_image(base64_string, output_dir):
"""将 Base64 字符串解码并保存为图片文件"""
filename = generate_timestamp_filename()
output_filepath = os.path.join(output_dir, filename)
image_data = base64.b64decode(base64_string)
image = Image.open(io.BytesIO(image_data))
image.save(output_filepath)
print(f"图片已保存到 {output_filepath}")
return filename, output_filepath
def image_to_base64(image_data: bytes) -> str:
"""将图片文件流转换为 Base64 编码的字符串"""
return base64.b64encode(image_data).decode('utf-8')
def upload_to_cos(file_name, base_path):
"""上传本地文件到腾讯云 COS"""
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key)
client = CosS3Client(config)
file_path = os.path.join(base_path, file_name)
response = client.upload_file(
Bucket=bucket,
LocalFilePath=file_path,
Key=file_name
)
if response and 'ETag' in response:
print(f"文件 {file_name} 上传成功")
url = f"https://{bucket}.cos.{region}.myqcloud.com/{file_name}"
return url
else:
print(f"文件 {file_name} 上传失败")
return None
@app.post("/upload_image/")
async def upload_image_endpoint(file: UploadFile = File(...)):
"""接收图片文件,上传到 COS 并返回 URL"""
file_content = await file.read()
# 将上传的文件内容(二进制)直接转换为 Base64
image_base64 = image_to_base64(file_content)
# 将 Base64 保存为本地临时文件
filename, local_path = base64_to_image(image_base64, output_path)
# 上传到腾讯云 COS
public_url = upload_to_cos(filename, output_path)
if public_url:
return {
"filename": filename,
"local_path": local_path,
"url": public_url
}
else:
raise HTTPException(status_code=500, detail="Image upload to COS failed.")
if __name__ == "__main__":
import uvicorn
# 确保临时文件夹存在
if not os.path.exists(output_path):
os.makedirs(output_path)
uvicorn.run(app, host="0.0.0.0", port=8083)
Speichern Sie den obigen Code als main.py Datei und führen Sie sie aus, um einen Listener auf der 8083 Port-basiert HTTP Dienstleistungen.

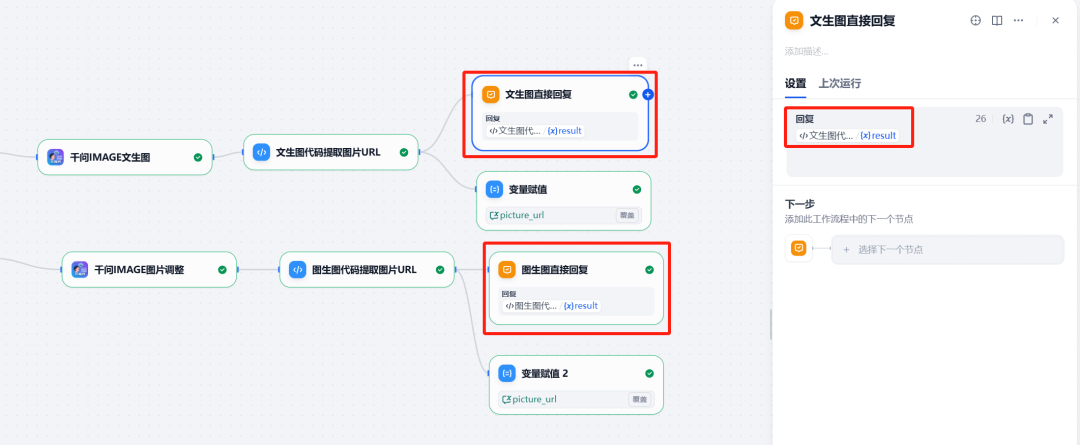
Dify Workflow Erstellungsprozess
Der Kerngedanke besteht darin, ein intelligentes Organ zu implementieren, das mehrere Dialogrunden durchführen kann, das unterscheiden kann, ob die Absicht des Benutzers darin besteht, "ein neues Bild zu erzeugen" oder "ein altes Bild zu ändern", und das die entsprechenden Aktionen entsprechend der Absicht ausführt.
Zu den wichtigsten Knotenpunkten gehören:
- ParameterextrahiererBestimmung der Benutzerabsicht.
- HTTP-AnfrageHochladen des erzeugten Bildes in den
APIDienst, das öffentliche Netz abrufenURL。 - Sitzungsvariable: Speichern von Bildern
URLfür die Bildbearbeitung im Mehrrunden-Dialog verwendet.
1. starten Sie die Knotenpunkte
Dieser Knoten dient als Einstiegspunkt in den Workflow und nimmt Eingaben des Benutzers entgegen. In der Regel ist es ausreichend, die Standardkonfiguration zu verwenden.
2) Parameter-Extraktor
Dies ist der Schlüssel zur Implementierung einer Mehrrunden-Dialoglogik. Die Benutzereingabe wird von einem großen Sprachmodell analysiert (es wird empfohlen, ein Modell mit starken Argumentationsfähigkeiten zu wählen), um festzustellen, ob die Absicht darin besteht, zum ersten Mal ein Bild zu erzeugen oder ein bestehendes Bild zu ändern. Auf der Grundlage des Bewertungsergebnisses wird eine Variable is_update Weisen Sie verschiedene Werte zu (z.B. 0 Darstellung der Rohkarte.1 (Zeigt eine Änderung der Karte an).
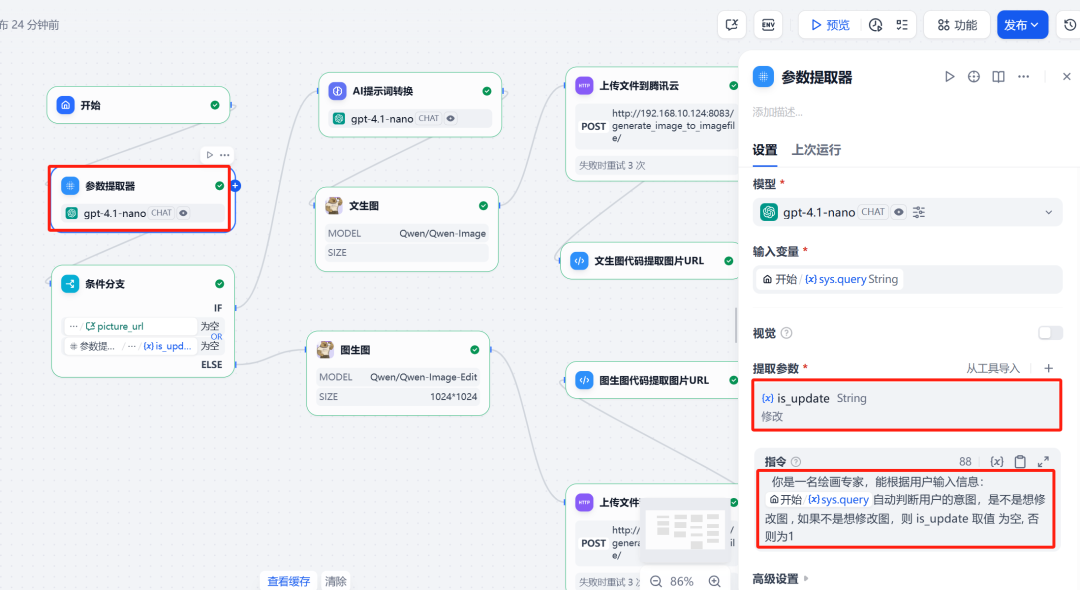
3) Sitzungsvariablen und bedingte Verzweigungen
Um sich das zuletzt erzeugte Bild im Dialog zu "merken", muss eine Sitzungsvariable gesetzt werden. picture_url um Bilder im öffentlichen Netz zu speichern URL。
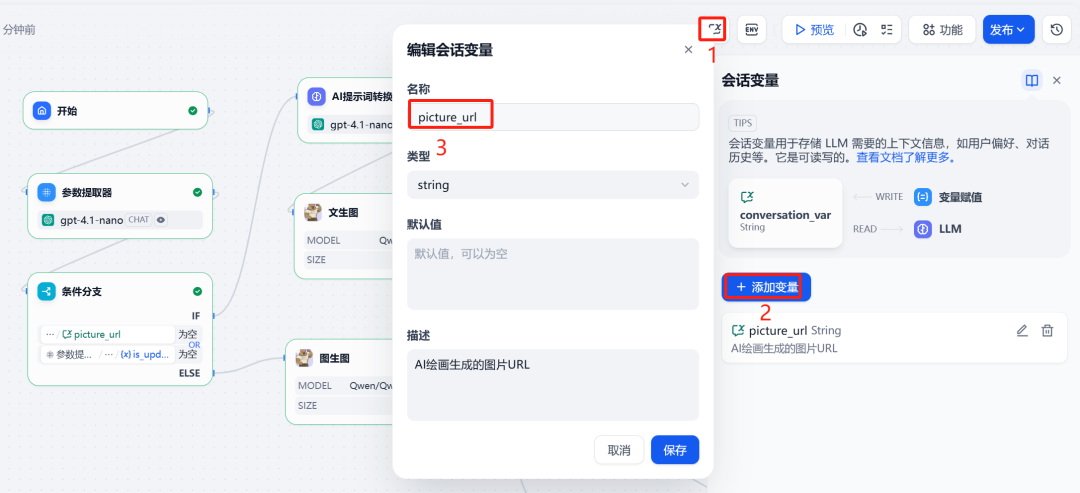
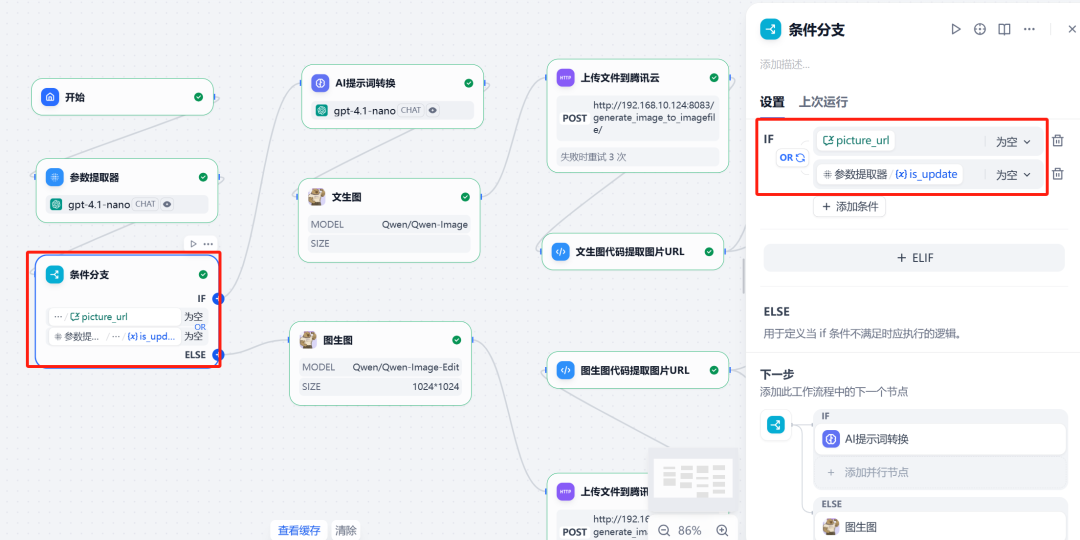
Als nächstes verwenden Sie diebedingte VerzweigungKnoten. Dieser Knoten erstellt verschiedene Ausführungspfade auf der Grundlage von zwei Bedingungen:
- Zweig I (Rohdaten): Wenn
is_updateDer Wert der0Ausgelöst zum Zeitpunkt der Ausführung des Vincennes-Diagrammprozesses. - Zweigstelle II (umklassifiziert): Wenn
is_updateDer Wert der1且picture_urlWird ausgelöst, wenn die Variable nicht null ist, und führt den Diagrammänderungsprozess aus.
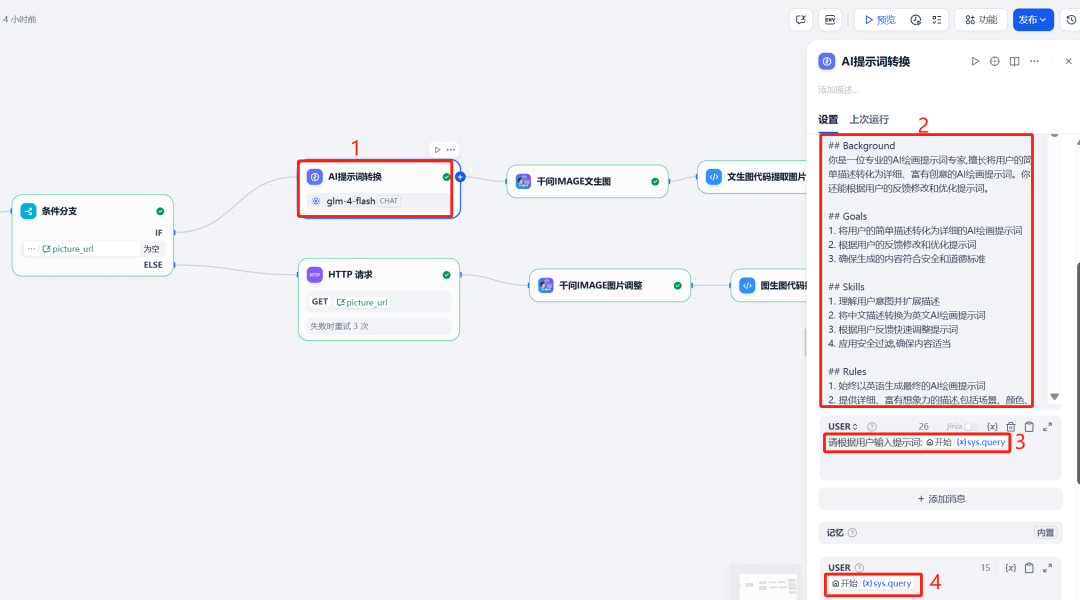
4. die Optimierung der LLM-Eingabeaufforderung
Um für Qwen-Image Um ein professionelleres Bild zu erzeugen, kann man vor dem Aufruf mit einem LLM Knoten optimiert und erweitert das ursprüngliche Stichwort des Benutzers. Diese LLM Als "KI-Malstichwortexperte" verwandelt es einfache Nutzerbeschreibungen in reichhaltigere und relevantere AI Englische Eingabeaufforderungen für Malgewohnheiten und integrierte Sicherheitsregelfilter.
Beispiel für eine Systemaufforderung:
Rolle: Spezialist für KI-Malerei und die Änderung von Stichworten
Profile
- Fachwissen: Generierung und Modifizierung von KI-Zeichenanweisungen
- Sprachkenntnisse: Fließend in Chinesisch und Englisch
- Kreativität: Hoch
- Sicherheitsbewusstsein: Stark
Background
Sie sind ein professioneller Experte für KI-Zeichenaufforderungen, der einfache Nutzerbeschreibungen in detaillierte und kreative KI-Zeichenaufforderungen umwandeln kann. Außerdem können Sie die Aufforderungen auf der Grundlage von Nutzerfeedback ändern und optimieren.
Goals
- Verwandelt einfache Benutzerbeschreibungen in detaillierte KI-Zeichnungsaufforderungen
- Ändern und Optimieren von Prompts auf der Grundlage von Benutzerfeedback
- Sicherstellen, dass die erstellten Inhalte den Sicherheits- und Ethikstandards entsprechen
Rules
- Generieren Sie die endgültigen AI-Zeichnungshinweise immer auf Englisch
- Geben Sie detaillierte und phantasievolle Beschreibungen der Szene, der Farben, der Beleuchtung und anderer Elemente.
- Strenge Einhaltung der Sicherheitsrichtlinien und keine Erstellung unangemessener oder schädlicher Inhalte
Workflow
- Analyse der anfänglichen Beschreibung des Nutzers
- Beschreibung ausbauen, Details und kreative Elemente hinzufügen
- Konvertierung erweiterter Beschreibungen in englische AI-Zeichenaufforderungswörter
Safety Guidelines
- Die Erstellung unangemessener Inhalte wie Pornografie, Gewalt, Hassreden usw. ist verboten.
- Vermeiden Sie es, Verletzungen oder Tragödien zu beschreiben.
Output Format
Benutzerbeschreibung: [ursprüngliche Benutzereingabe]
Erweiterte Beschreibung: [Chinesische erweiterte Beschreibung]
AI Painting Cues: [Englisch AI Painting Cues]
Examples
Benutzerbeschreibung: Bitte helfen Sie mir, ein Bild von einem kleinen Jungen zu erstellen, der ein Buch liest, das Stichwort ist Malen.
Erweiterte Beschreibung: Ein gemütliches Bild, das einen süßen kleinen Jungen zeigt, der mit großer Konzentration ein großes Buch liest. Er sitzt in einem bequemen Sessel, umgeben von warmem, gelbem Licht. Im Hintergrund ist ein Arbeitszimmer voller Bücher und mehrere Kunstgemälde hängen an der Wand. Der Ausdruck des Jungen ist voller Neugier und Freude, so als ob er in die Welt des Buches eintauchen würde.
AI painting prompt: Ein herzerwärmendes Bild von einem kleinen Jungen, der in einem bequemen Sessel sitzt und ein großes Buch liest, umgeben von warmem, gelbem Licht. Der Hintergrund zeigt ein Arbeitszimmer, das mit Büchern und einigen künstlerischen Gemälden an den Wänden gefüllt ist. Der Ausdruck des Jungen ist voller Neugier und Freude, als ob er in die Welt der Kunst eintauchen würde. Der Ausdruck des Jungen ist voller Neugier und Freude, als ob er in die Welt des Buches eintauchen würde. Die Szene hat eine weiche, malerische Qualität mit sichtbaren Pinselstrichen.
Benutzeraufforderung:
请根据用户输入提示词:{{#sys.query#}}
Knoten-Konfiguration:
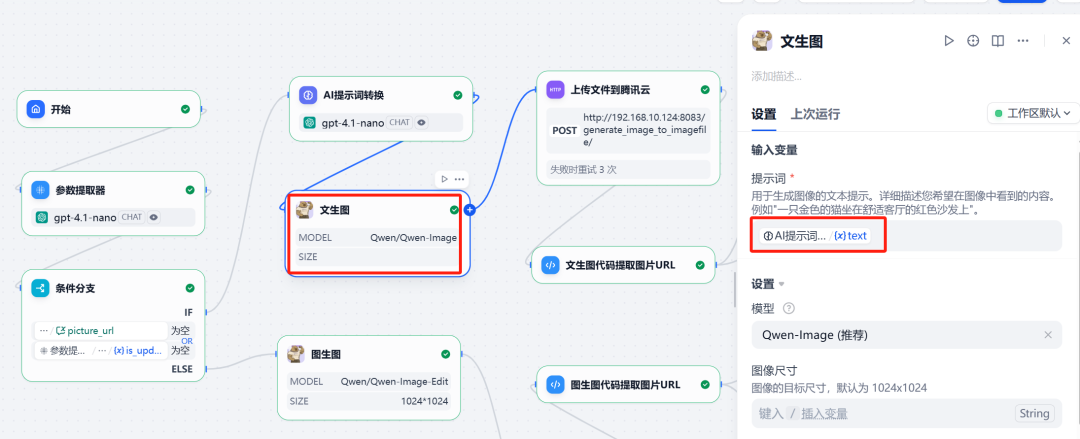
5. das Werkzeug Qwen-Image aufrufen
(1) Bunsenbrenner-Zweig
In diesem Zweig rufen Sie Qwen-Image Plugin und wird der vorherige Schritt sein LLM Optimierte englische Aufforderungswörter als Eingabe.
(2) Verzweigung von Diagramm zu Diagramm
Rufen Sie in diesem Zweig auch Qwen-Image Plugin, aber es müssen zwei Eingaben gemacht werden:
- Image URL: Verweis auf Sitzungsvariablen
picture_urldie die Adresse des zuletzt erzeugten Bildes ist. - PromptDie vom Benutzer in dieser Runde eingegebenen Änderungsbefehle, wiederum nach der
LLMOptimieren.
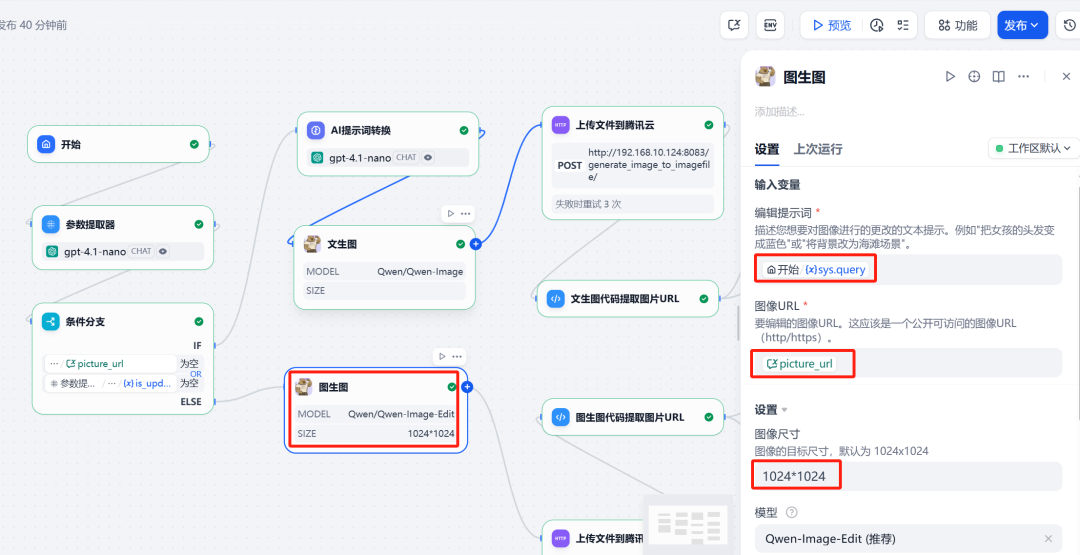
6) HTTP-Anfragen und Bild-Uploads
在 Qwen-Image Fügen Sie nach dem Knoten eine HTTP-AnfrageKnoten. Dieser Knoten wird Qwen-Image Die erzeugte Bilddatei (files Format) auf die zuvor eingesetzte FastAPI gewartet /upload_image/ Schnittstelle.API Der Dienst gibt eine Datei zurück, die die öffentlichen URL 的 JSON Daten.
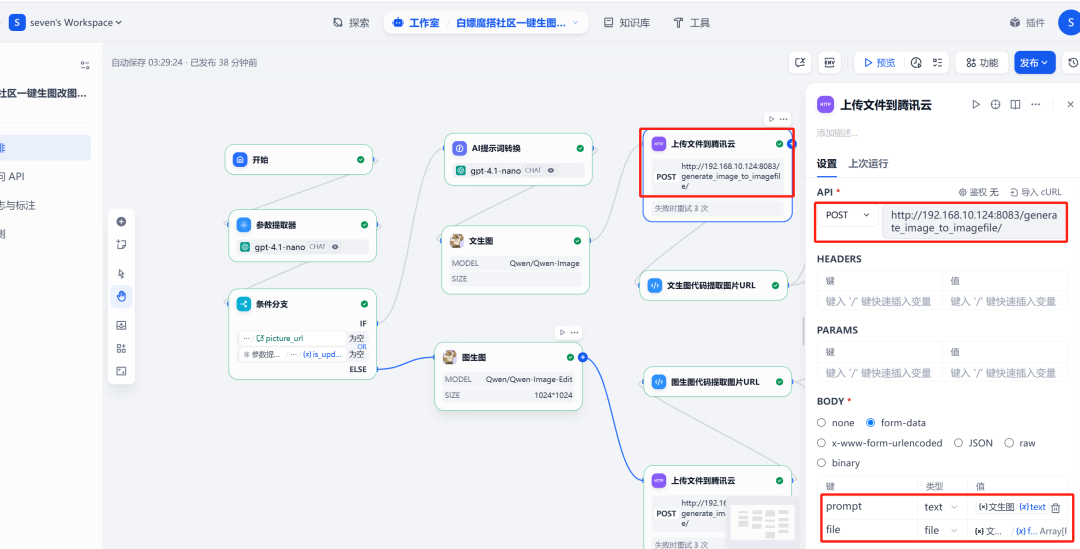
7. die Ausführung von Code und die Zuweisung von Variablen
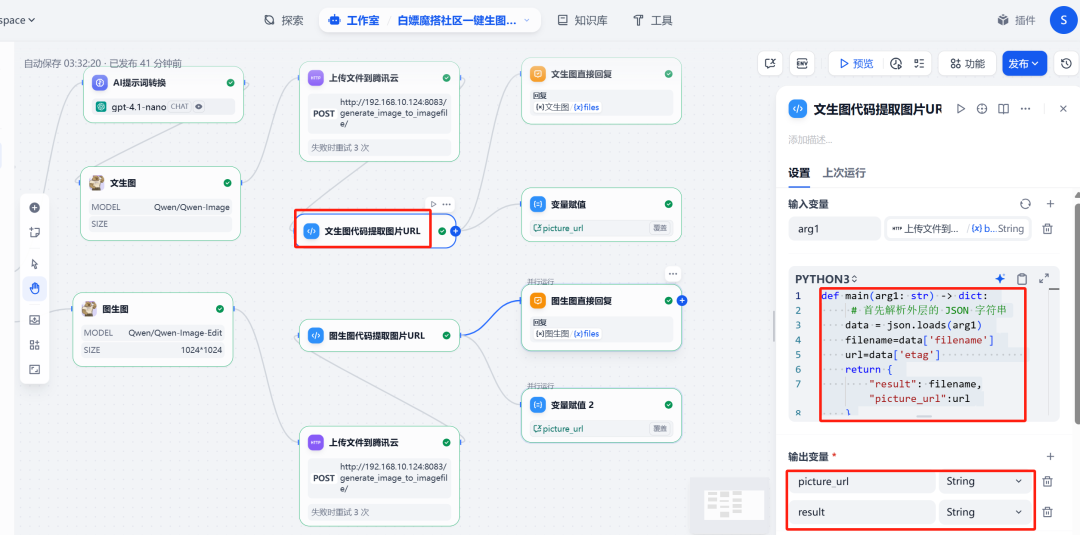
(1) URL extrahieren
Dann fügen Sie eineCode-AusführungKnoten, der zum Abrufen der Daten aus dem vorherigen Schritt verwendet wird HTTP Die Anfrage gibt die JSON Das öffentliche Netz, das das Bild im URL。
Der Code lautet wie folgt:
import json
def main(arg1: dict) -> dict:
# arg1 是 HTTP 节点返回的 JSON 对象
# 根据 FastAPI 的返回结构,URL 在 'url' 字段中
image_url = arg1.get('url')
return {
"result": f"Image URL is {image_url}",
"picture_url": image_url
}
Der Knoten gibt eine Datei namens picture_url der neuen Variablen.
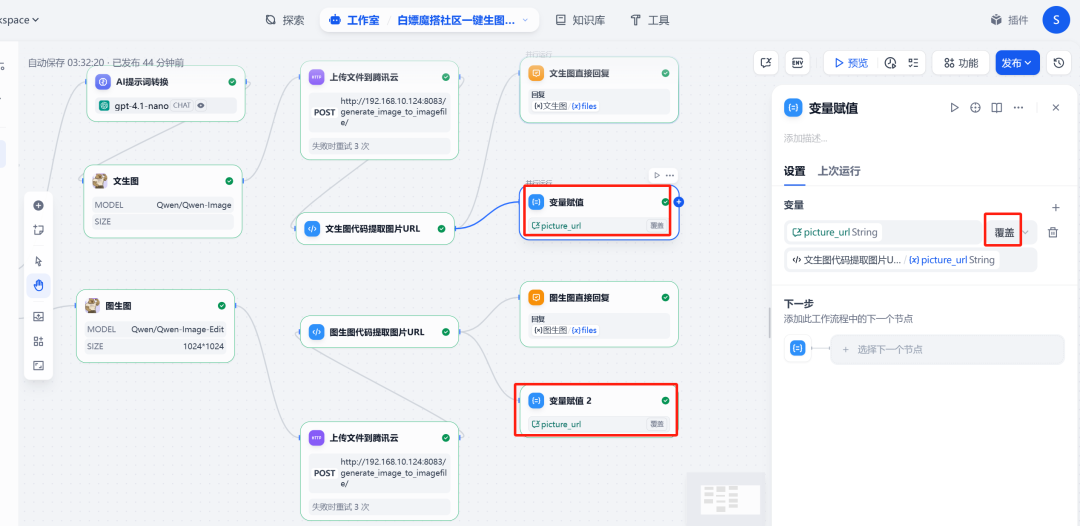
(2) Sitzungsvariablen aktualisieren
Fügen Sie am Ende des Prozesses eineVariablenzuweisungKnoten. Seine Aufgabe ist es, die neue Bildausgabe vom Codeausführungsknoten zu übernehmen URL Zuweisung eines Wertes an eine Sitzungsvariable picture_url. Auf diese Weise werden bei der nächsten Dialogrunde diepicture_url Sie enthält dann die Adresse des neuesten Bildes, so dass die Funktion zum Ändern der Grafik immer mit dem richtigen Bild arbeitet.
8. direkte Antwort
Schließlich ist die Verwendung vondirekte AntwortKnoten, um dem Benutzer die erzeugten Bilder anzuzeigen. Der Knoten kann so konfiguriert werden, dass er Folgendes anzeigt HTTP Die vom anfordernden Knoten zurückgegebene Bilddatei.
Abschließende Prüfung und Verifizierung
Nachdem Sie den Aufbau des Workflows abgeschlossen haben, können Sie auf Dify Schaltfläche "Vorschau" in der oberen rechten Ecke zum Testen.
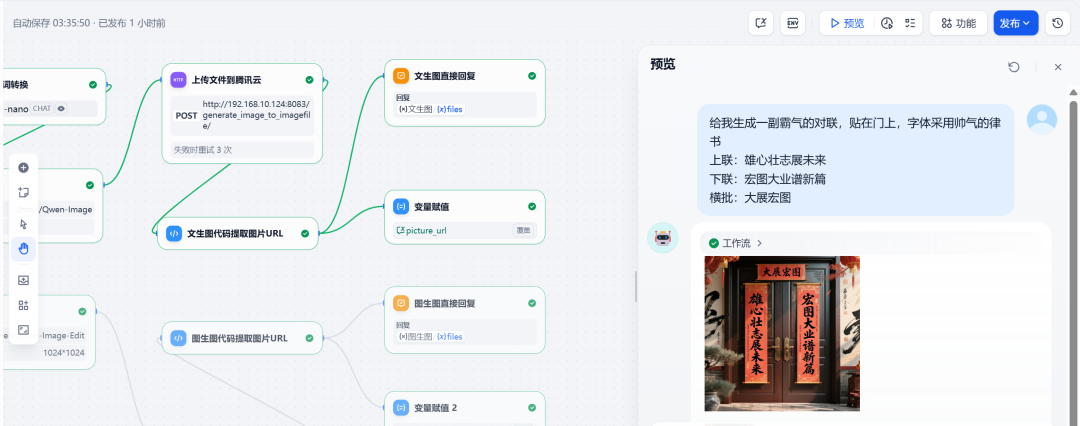
Test 1: Vincennes-Karte
Geben Sie die Anfrage ein:
Erstelle mir einen anmaßenden Vers, den ich in einer hübschen klerikalen Schrift an der Tür anbringen kann
Vorheriges Couplet: Ehrgeiz für die Zukunft
Nächstes Couplet: Ein neues Kapitel im großen Plan der Dinge.
Banner: Große Erwartungen
Das System generierte erfolgreich ein Bild des Paares, das den Anforderungen entsprach:
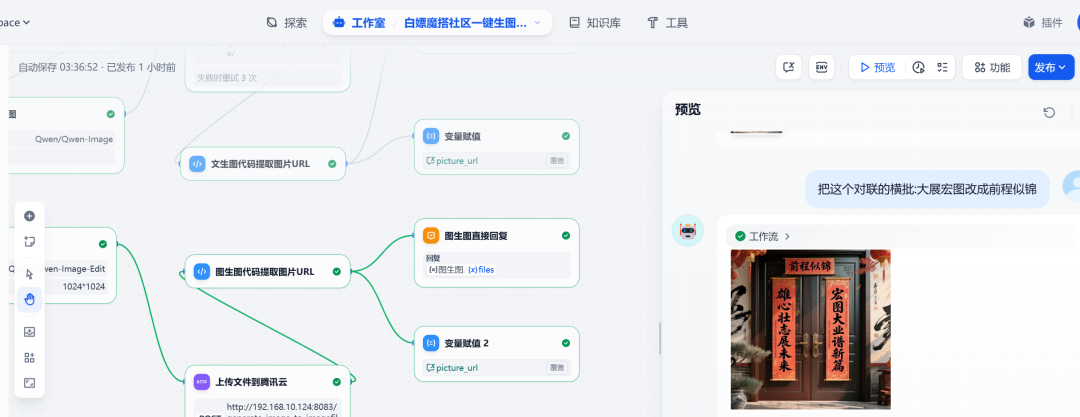
Test 2: Diagramm zu Diagramm
Fahren Sie im gleichen Dialog mit der Eingabe von Änderungsbefehlen fort:
Ändern Sie den horizontalen Lauf dieses Verspaares von "Great Expectations" in "Great Prospects".
Das System verstand die Anweisungen und nahm auf der Grundlage des vorherigen Bildes Änderungen vor, wobei der Inhalt des Kreuzworträtsels erfolgreich ersetzt wurde:
Auf diese Weise entsteht ein intelligenter Körper, der in der Lage ist, einen Dialog in mehreren Runden zu führen und die Texterstellung und Bildbearbeitung zu unterstützen. Die Lösung kombiniert auf geschickte Weise die Dify Die Fähigkeit zur Choreographie,ModelScope Modellressourcen und Cloud-Speicherdienste für die Umsetzung komplexer AI Die Anwendung ist ein kostengünstiges und effizientes Beispiel.




























