



DeepSieve ist ein quelloffenes Retrieval Augmented Generation (RAG)-Framework, das auf GitHub gehostet wird und sich auf die Verarbeitung komplexer Abfragen und Multi-Source-Daten konzentriert. DeepSieve wurde von MinghoKwok entwickelt und unterstützt die Verarbeitung strukturierter Daten (z. B. SQL-Tabellen, JSON-Protokolle) und unstrukturierter Daten (z. B. Wikipedia) und eignet sich für Szenarien, die eine mehrstufige Argumentation erfordern. Der Schwerpunkt liegt auf einem modularen Design, und die Benutzer können die Funktionalität ihren Bedürfnissen entsprechend anpassen, so dass es für Forscher und Entwickler geeignet ist, um komplexe Datenanalyseaufgaben zu bewältigen. Das Projekt wurde am 29. Juli 2025 als Preprint auf arXiv veröffentlicht, und der vollständige Korpus wurde auf Arkiv hochgeladen.
Funktionsliste
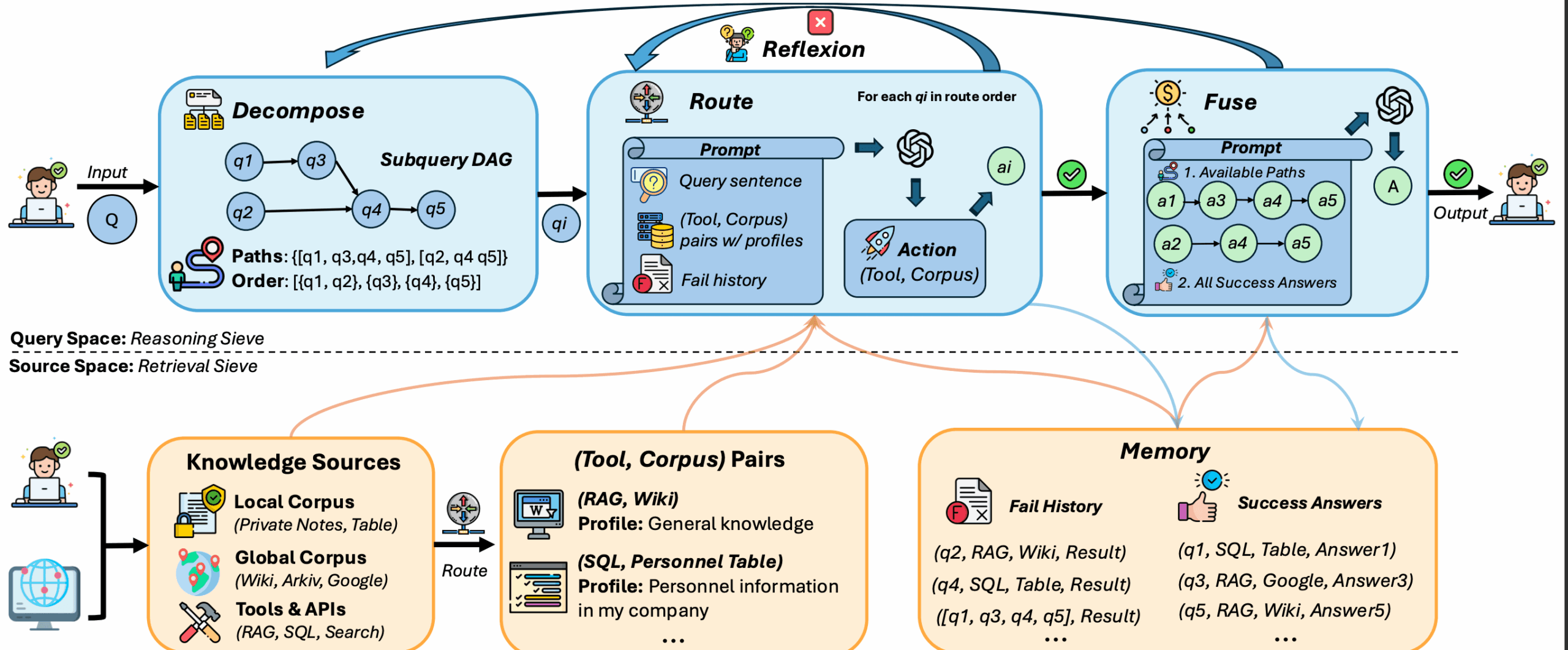
- Zerlegung der Abfrage Komplexe Abfrage in mehrere einfache Teilprobleme aufteilen, um sie präzise zu bearbeiten.
- Teilaspekt Routing Intelligente Zuordnung von Teilfragen zu geeigneten Tools oder Datenquellen (z. B. lokale Datenbanken oder globale Wissensdatenbanken).
- Reflexionsmechanismen Automatische Erkennung fehlgeschlagener Suchvorgänge und Wiederholungsversuche, wobei bis zu zwei Wiederholungen möglich sind.
- Konvergenz der Antworten : Integrieren Sie die Antworten auf die Teilfragen, um die endgültige vollständige Antwort zu erstellen.
- Unterstützt mehrere Datenquellen Umgang mit heterogenen Daten wie SQL-Tabellen, JSON-Logs, Wikipedia usw.
- Zwei RAG-Modi Die Suchmodi sind einfach (Naiv) und grafisch strukturiert (Graph), um unterschiedlichen Bedürfnissen gerecht zu werden.
- Detaillierte Protokollierung Speichern von Zwischenergebnissen, Fusionshinweisen und Leistungsmetriken für jede Abfrage zur einfachen Fehlersuche und Optimierung.
- Modularer Aufbau Benutzer können Funktionsmodule mit Befehlszeilenschaltern aktivieren oder deaktivieren, um flexibel zu sein.
Hilfe verwenden
Einbauverfahren
DeepSieve ist ein Python-basiertes Open-Source-Projekt. Sie müssen das Repository über GitHub klonen und die Umgebung konfigurieren. Hier sind die detaillierten Schritte:
- Klon-Lager
Führen Sie den folgenden Befehl in einem Terminal aus, um das DeepSieve-Repository lokal zu klonen:git clone https://github.com/MinghoKwok/DeepSieve.gitRufen Sie den Projektkatalog auf:
cd DeepSieve - Installation von Abhängigkeiten
Das Projekt hängt von Python 3.7+ und verwandten Bibliotheken für maschinelles Lernen und Datenverarbeitung ab. Installieren Sie die Abhängigkeiten:pip install -r requirements.txtfür den Fall, dass
requirements.txtWird nicht mitgeliefert, es wird empfohlen, die Kernbibliothek manuell zu installieren:pip install numpy pandas scikit-learn openaiEs wird empfohlen, eine virtuelle Umgebung zu verwenden, um Konflikte mit Abhängigkeiten zu vermeiden:
python -m venv venv source venv/bin/activate # Linux/macOS venv\Scripts\activate # Windows - Umgebungsvariablen konfigurieren
DeepSieve verwendet das Large Language Model (LLM) zur Verarbeitung von Abfragen, die eine Konfiguration von API-Schlüsseln erfordern. Zum Beispiel kann die Verwendung des DeepSeek Modelle:export OPENAI_API_KEY=your_api_key export OPENAI_MODEL=deepseek-chat export OPENAI_API_BASE=https://api.deepseek.com/v1Je nach Verwendungsmodus (Naiv oder Graph) setzen Sie die RAG Art:
export RAG_TYPE=naive # 或 graph - Überprüfung der Umgebung
Vergewissern Sie sich, dass alle Abhängigkeiten korrekt installiert sind und dass der API-Schlüssel gültig ist. Wenn Sie eine benutzerdefinierte Datenquelle verwenden, überprüfen Sie, ob der Datendateipfad richtig konfiguriert ist.
DeepSieve ausführen
DeepSieve wird über die Befehlszeile ausgeführt und bietet eine flexible Parameterkonfiguration. Im Folgenden wird die grundlegende Verwendung beschrieben:
Naives RAG-Modell
Der naive Modus ist für einfache Aufgaben geeignet. Führen Sie den folgenden Befehl aus:
export RAG_TYPE=naive
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
--dataset: Geben Sie den Datensatz an (z. B.hotpot_qa)。--sample_sizeLegen Sie die Anzahl der Behandlungsproben fest.--decomposeEnable query decomposition.--use_routingEnable sub-issue routing.--use_reflectionErmöglichung von Reflexionsmechanismen.--max_reflexion_times: Legen Sie die maximale Anzahl der Reflexionen fest.
Grafik RAG-Modus
Graphschema eignet sich für komplexe Abfragen und erfordert die Unterstützung von Graphstrukturen:
export RAG_TYPE=graph
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
Module deaktivieren
Benutzer können Funktionen deaktivieren, indem sie Befehlszeilenparameter entfernen. Beispiel:
- Keine Abfragezerlegung verwenden: entfernen
--decompose。 - Nicht verwendete Routen: entfernen
--use_routing。 - Nicht verwendete Reflexionen: entfernen
--use_reflection。
Ausgabeergebnis
Die folgenden Dateien werden für jeden Lauf erstellt:
- Ergebnisse für jede Abfrage:
outputs/{rag_type}_{dataset}/query_{i}_results.jsonl - Fusions-Tipp:
outputs/{rag_type}_{dataset}/query_{i}_fusion_prompt.txt - Allgemeine Leistungsindikatoren:
overall_results.txt和overall_results.json
Hauptfunktionen
Zerlegung der Abfrage
DeepSieve unterteilt komplexe Abfragen in Teilprobleme. Zum Beispiel wird die Abfrage "Umsatz und Anzahl der Mitarbeiter eines Unternehmens im Jahr 2023" aufgeteilt in:
- Teilfrage 1: Ermitteln Sie die Einnahmen des Unternehmens im Jahr 2023.
- Teilfrage 2: Ermitteln Sie die Anzahl der Beschäftigten in einem Unternehmen.
Betriebsverfahren:
- Geben Sie eine Abfrage in ein Skript oder eine Befehlszeile ein.
- Führen Sie das Skript aus, und DeepSieve schlüsselt die Abfrage automatisch auf und zeigt die Teilprobleme an (die im Protokoll angezeigt werden).
Teilaspekt Routing
Jede Unterfrage ist dem entsprechenden Werkzeug oder der entsprechenden Datenquelle zugeordnet. Beispiel:
- Strukturierte Daten(z. B. SQL-Tabellen), die an Datenbankabfragetools weitergeleitet werden.
- Unstrukturierte Daten (z. B. Wikipedia), die an Text-Retrieval-Tools weitergeleitet werden.
Die Benutzer müssen keine manuellen Angaben machen, DeepSieve übernimmt die Weiterleitung automatisch. Protokolldateien prüfenquery_{i}_results.jsonlDetails zur Route können eingesehen werden.
Reflexionsmechanismen
Wenn der Abruf eines Teilaspekts fehlschlägt, versucht DeepSieve es automatisch bis zu zweimal erneut. Der Reflexionsprozess wird im Protokoll aufgezeichnet, und der Benutzer kann den Grund für den Fehlschlag und das Ergebnis des erneuten Versuchs einsehen.
Konvergenz der Antworten
DeepSieve konsolidiert die Antworten auf die Unterfragen, um die endgültige Antwort zu erstellen. Zum Beispiel würden die Antworten auf die obige Unternehmensabfrage zusammengeführt werden:
- "Im Jahr 2023 wird das Unternehmen einen Umsatz von X $ und Y Mitarbeiter haben."
Fusionsspitzen werden in der Dateiquery_{i}_fusion_prompt.txtdie für den Benutzer leicht zu überprüfen ist.
Vorsichtsmaßnahmen für die Verwendung
- Vorbereitung der Daten Vergewissern Sie sich, dass die Eingabedaten im richtigen Format vorliegen (z. B. CSV, JSON), um Kodierungsfehler zu vermeiden.
- API-Schlüssel Bestätigen Sie, dass der LLM-API-Schlüssel gültig ist und dass die Netzwerkverbindung stabil ist.
- Protokollkontrolle Ansicht nach der Ausführung
outputs/Katalogs, der Analyse von Leistungsmetriken und Fehlerprotokollen. - Unterstützung der Gemeinschaft Wenn Sie auf Probleme stoßen, besuchen Sie die GitHub Issues Seite oder das arXiv Paper für weitere Informationen.
Anwendungsszenario
- akademische Forschung
Forscher verarbeiten Daten aus verschiedenen Quellen (z. B. Wikipedia und experimentelle Datenbanken), um mit DeepSieve schnell komplexe Fragen zu beantworten. Zum Beispiel bei der Analyse von biologischen Datensätzen und genetischen Assoziationen in der Literatur. - Analyse von Geschäftsdaten
Unternehmensanalysten nutzen DeepSieve zur Verarbeitung von Verkaufsdaten und Kundenprotokollen, um mehrdimensionale Fragen zu beantworten, z. B. "Welche Produkte werden im Jahr 2023 die höchsten Verkaufszahlen und eine hohe Kundenzufriedenheit aufweisen?" . - Datenschutzsensible Szenarien
DeepSieve unterstützt private Datenquellen (z. B. interne Datenbanken) zur Verarbeitung von Abfragen ohne Zusammenführung von Daten, geeignet für die Finanz- oder Gesundheitsbranche. - Open-Source-Entwicklung
Entwickler nutzen das modulare Design von DeepSieve zur Erweiterung der Funktionalität oder zur Integration in bestehende Systeme für die kundenspezifische Datenverarbeitung.
QA
- Welche Datenquellen werden von DeepSieve unterstützt?
Unterstützung für SQL-Tabellen, JSON-Protokolle, Wikipedia usw., der spezifische Umfang der Unterstützung sollte in der Projektdokumentation oder der Konfigurationsdatei angegeben werden. - Wie kann ich einen Laufzeitfehler beheben?
Sondeoutputs/Log-Datei im Verzeichnis, um die Fehlerdetails zu sehen. Vergewissern Sie sich, dass die Version der Abhängigkeitsbibliothek korrekt ist und der API-Schlüssel gültig ist. - Unterschied zwischen Graph-Modus und Naiv-Modus?
Der naive Modus eignet sich für einfache Abfragen und ist schnell; der Graphmodus eignet sich für komplexe mehrstufige Schlussfolgerungen mit höherer Genauigkeit, aber höheren Rechenkosten. - Wie kann ich Code beisteuern?
Forken Sie das Repository, ändern Sie den Code und reichen Sie einen Pull Request ein.CONTRIBUTING.mdDokumentation, die der Code-Spezifikation folgt.


























