



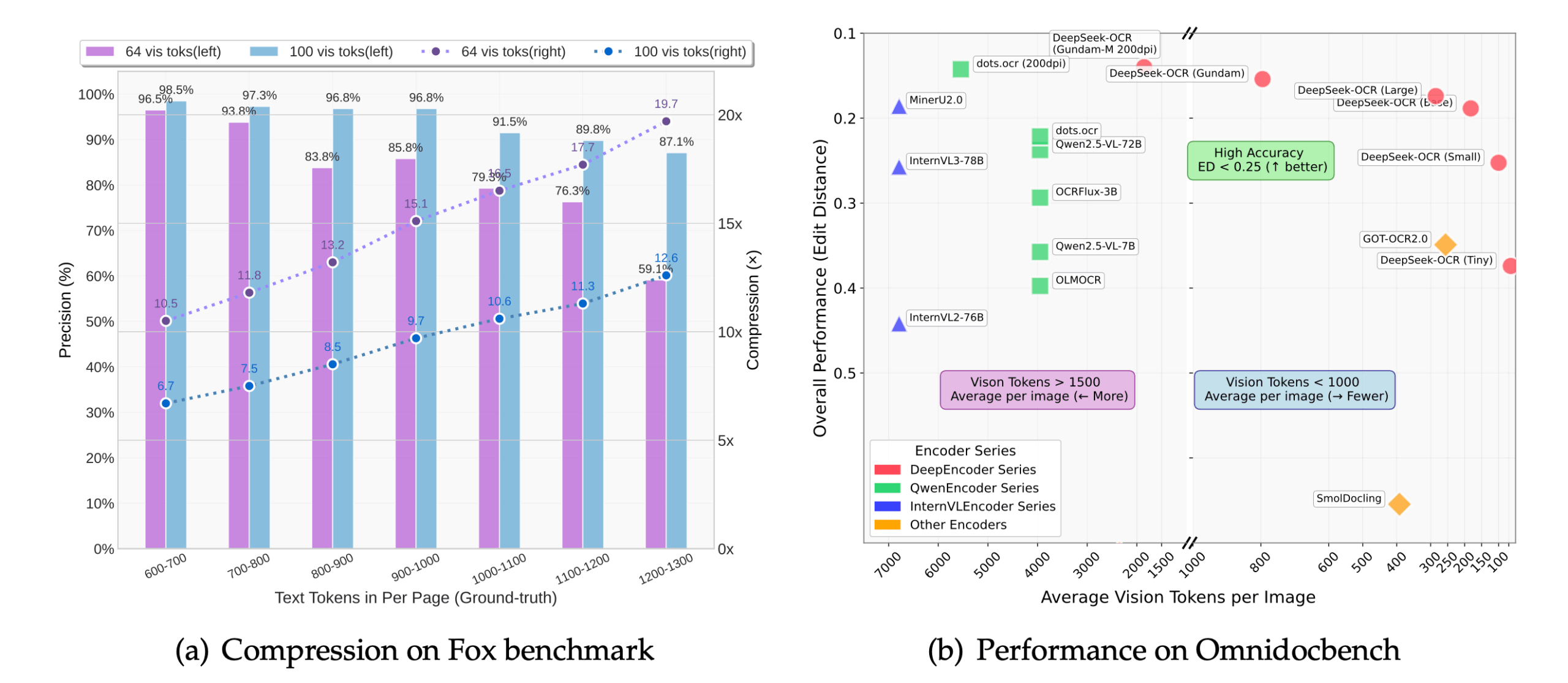
DeepSeek-OCR ist ein optisches Zeichenerkennungswerkzeug (OCR), das von DeepSeek-AI entwickelt und als Open Source zur Verfügung gestellt wird. Es schlägt einen neuen Ansatz namens "Contextual Optical Compression" vor, der die Rolle des visuellen Codierers aus der Perspektive des Large Language Model (LLM) neu überdenkt. Anstatt einfach nur Text in einem Bild zu erkennen, rendert das Tool lange Textinhalte wie z. B. eine Dokumentseite in ein Bild, das dann in eine kleinere Menge von "Vision Tokens" komprimiert wird. Der Decoder des Sprachmodells rekonstruiert dann den ursprünglichen Text aus diesen Bildpunkten. Mit diesem Ansatz kann die Anzahl der eingegebenen Token um das 7- bis 20-fache reduziert werden, so dass große Modelle weniger Rechenressourcen für die Bearbeitung sehr langer Dokumente benötigen, was die Verarbeitungseffizienz und -geschwindigkeit erhöht. Das Projekt unterliegt der MIT-Open-Source-Lizenz.
Funktionsliste
- Kontextuelle optische KomprimierungDie vom Modell verarbeitete Datenmenge wird durch die Komprimierung von Bildern in visuelle Token drastisch reduziert, was die Speichernutzung verringert und die Geschwindigkeit der Schlussfolgerungen erhöht.
- Hochpräzise ErkennungBei einer 10-fachen Komprimierung wird immer noch eine Erkennungsgenauigkeit von ca. 97% erreicht, wobei das Layout, die Typografie und die räumliche Beziehung des Dokuments erhalten bleiben.
- Strukturierte AusgabeDie Fähigkeit, Dokumente, insbesondere Seiten mit komplexem Layout (z.B. Tabellen, Listen, Überschriften), direkt in das Markdown-Format zu konvertieren, wobei die Struktur des Originaltextes erhalten bleibt.
- Multitasking-UnterstützungDurch Änderung des Eingabeaufforderungsworts (Prompt) kann das Modell verschiedene Aufgaben erfüllen, z. B:
- Konvertieren Sie das gesamte Dokument in Markdown.
- Allgemeine OCR-Erkennung von Bildern.
- Analysiert die Diagramme im Dokument.
- Beschreiben Sie den Inhalt des Bildes im Detail.
- Mehrere AuflösungsmodiUnterstützt eine breite Palette fester Auflösungen von 512 x 512 bis 1280 x 1280 sowie einen dynamischen Auflösungsmodus für die Verarbeitung von Dokumenten mit ultrahoher Auflösung.
- Leistungsstarkes ReasoningIntegriert mit vLLM und Transformers-Framework, erreicht es eine Geschwindigkeit von etwa 2500 Token/Sekunde bei der Verarbeitung von PDF-Dateien auf A100-40G GPUs.
- HandschrifterkennungHandschriftliche Inhalte werden bei guter Beleuchtung und Auflösung besser erkannt als mit vielen herkömmlichen OCR-Tools.
Hilfe verwenden
Die Installation und Verwendung von DeepSeek-OCR richtet sich hauptsächlich an Entwickler und erfordert eine gewisse Programmiergrundlage. Nachfolgend finden Sie eine detaillierte Beschreibung der Vorgehensweise, die sich im Wesentlichen in drei Teile gliedert: Umgebungskonfiguration, Installation und Codeerstellung.
Schritt 1: Vorbereitung der Umwelt
Die offiziell empfohlenen Umgebungen sind CUDA 11.8 und PyTorch 2.6.0. Bevor Sie beginnen, müssen Sie Git und Conda installieren.
- Projektlager klonen
Klonen Sie zunächst die offizielle DeepSeek-OCR-Codebasis von GitHub auf Ihren lokalen Computer. Öffnen Sie ein Terminal (Befehlszeilentool) und geben Sie den folgenden Befehl ein:git clone https://github.com/deepseek-ai/DeepSeek-OCR.gitWenn er ausgeführt wird, erstellt er im aktuellen Verzeichnis eine Datei namens
DeepSeek-OCRdes Ordners. - Erstellen und Aktivieren der Conda-Umgebung
Um Abhängigkeitskonflikte mit anderen Python-Projekten auf Ihrem Computer zu vermeiden, empfiehlt es sich, eine separate virtuelle Conda-Umgebung zu erstellen.# 创建一个名为deepseek-ocr的Python 3.12.9环境 conda create -n deepseek-ocr python=3.12.9 -y # 激活这个新创建的环境 conda activate deepseek-ocrNach erfolgreicher Aktivierung erscheint vor der Terminal-Eingabeaufforderung die Meldung
(deepseek-ocr)Worte.
Schritt 2: Installieren von Abhängigkeiten
In einer aktivierten Conda-Umgebung müssen die für die Ausführung des Modells erforderlichen Python-Bibliotheken installiert werden.
- Installation von PyTorch
Installieren Sie die an CUDA 11.8 angepasste PyTorch-Version entsprechend den offiziellen Anforderungen.pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118 - Andere Kernabhängigkeiten installieren
Das Projekt stützt sich auf die vLLM-Bibliothek für Hochleistungsinferenzen und erfordert außerdem die Installation derrequirements.txtAndere in der Datei aufgeführte Pakete.# 进入项目文件夹 cd DeepSeek-OCR # 安装vLLM(注意:官方提供了编译好的whl文件链接,也可以自行编译) # 示例是下载官方提供的whl文件进行安装 pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl # 安装requirements.txt中的所有依赖 pip install -r requirements.txt - Flash Attention installieren (optional, aber empfohlen)
Um eine optimale Geschwindigkeit zu erreichen, wird empfohlen, die Flash Attention Library zu installieren.pip install flash-attn==2.7.3 --no-build-isolationAchtung! Sie können diese Bibliothek auch deinstalliert lassen, wenn Ihr Grafikprozessor nicht unterstützt wird oder die Installation fehlschlägt. Später im Code müssen Sie die
_attn_implementation='flash_attention_2'Mit diesem Parameter läuft das Modell zwar, aber langsamer.
Schritt 3: Ausführen des Inferenzcodes
DeepSeek-OCR bietet zwei gängige Inferenzansätze: basierend auf demTransformersDie One-Shot-Inferenz der Bibliothek und eine Bibliothek, die aufvLLMder leistungsstarken Batch-Inferenz.
Ansatz 1: Schnelle Inferenz mit Transformatoren (geeignet für Einzelbildprüfungen)
Dieser Ansatz ist einfach zu kodieren und ideal, um Modelleffekte schnell zu testen.
- Erstellen Sie eine Python-Datei, z. B.
test_ocr.py。 - Kopieren Sie den folgenden Code in eine Datei. Dieser Code lädt das Modell und führt die OCR-Erkennung für ein bestimmtes Bild durch.
import torch from transformers import AutoModel, AutoTokenizer import os # 指定使用的GPU,'0'代表第一张卡 os.environ["CUDA_VISIBLE_DEVICES"] = '0' # 模型名称 model_name = 'deepseek-ai/DeepSeek-OCR' # 加载分词器和模型 tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) # 加载模型,使用flash_attention_2加速,并设置为半精度(bfloat16)以节省显存 model = AutoModel.from_pretrained( model_name, trust_remote_code=True, _attn_implementation='flash_attention_2', use_safetensors=True ).eval().cuda().to(torch.bfloat16) # 定义输入的图片路径和输出路径 image_file = 'your_image.jpg' # <-- 将这里替换成你的图片路径 output_path = 'your/output/dir' # <-- 将这里替换成你的输出文件夹路径 # 定义提示词,引导模型执行特定任务 # 这个提示词告诉模型将文档转换为Markdown格式 prompt = "<image>\n<|grounding|>Convert the document to markdown. " # 执行推理 res = model.infer( tokenizer, prompt=prompt, image_file=image_file, output_path=output_path, base_size=1024, image_size=640, crop_mode=True, save_results=True, test_compress=True ) print(res) - laufender Code
Platzieren Sie ein zu erkennendes Bild (z. B.your_image.jpg) in dasselbe Verzeichnis wie das Skript und führen Sie es dann aus:python test_ocr.pyAm Ende des Programmlaufs wird der erkannte Text auf dem Terminal ausgedruckt, während das Ergebnis in dem von Ihnen angegebenen Ausgabepfad gespeichert wird.
Möglichkeit zwei: vLLM für Stapelverarbeitung verwenden (geeignet für die Verarbeitung einer großen Anzahl von Bildern oder PDF)
Der vLLM-Modus ist leistungsfähiger und für Produktionsumgebungen geeignet.
- Änderung der Konfigurationsdatei
gehen inDeepSeek-OCR-master/DeepSeek-OCR-vllmVerzeichnis, öffnen Sie dieconfig.pyDatei, ändern Sie den Eingabepfad in dieser Datei (INPUT_PATH) und den Ausgangspfad (OUTPUT_PATH) und andere Einstellungen. - ausführbares Skript
In diesem Verzeichnis werden Skripte für verschiedene Aufgaben bereitgestellt:- Verarbeitet Streaming-Bilddaten:
python run_dpsk_ocr_image.py - PDF-Dateien verarbeiten:
python run_dpsk_ocr_pdf.py - Führen Sie Benchmark-Tests durch:
python run_dpsk_ocr_eval_batch.py
- Verarbeitet Streaming-Bilddaten:
Anwendungsszenario
- Digitalisierung von Dokumenten
Nach dem Scannen von Papierbüchern, Verträgen, Berichten usw. in Bilder können Sie diese mit DeepSeek-OCR schnell in bearbeitbaren, durchsuchbaren elektronischen Text umwandeln, wobei die ursprünglichen Beschriftungen, Listen und Tabellenstrukturen hervorragend erhalten bleiben. - Extraktion von Informationen
Automatisches Extrahieren von Schlüsselinformationen wie Betrag, Datum, Projektname usw. aus Bildern von Rechnungen, Quittungen, Formularen usw., wodurch die Dateneingabe automatisiert und manuelle Vorgänge reduziert werden. - Bildung und Forschung
Forscher können mit diesem Tool Textinhalte in Papieren, alten Büchern, Archiven und anderen dokumentarischen Materialien schnell identifizieren und konvertieren, um anschließend Daten zu analysieren und Inhalte abzurufen. - Anwendungen zur Barrierefreiheit
Durch die Erkennung von Text in Bildern und die Erstellung detaillierter Beschreibungen kann es sehbehinderten Nutzern helfen, den Inhalt der Bilder zu verstehen, z. B. beim Lesen von Speisekarten, Straßenschildern oder Produktanleitungen.
QA
- Ist DeepSeek-OCR kostenlos?
Ja, DeepSeek-OCR ist ein Open-Source-Projekt, das der MIT-Lizenz unterliegt und von den Nutzern frei verwendet, verändert und weitergegeben werden kann. - Welche Sprachen werden unterstützt?
Das Modell demonstriert seine Leistungsfähigkeit vor allem bei der Verarbeitung englischer und chinesischer Dokumente. Da es auf einem großen Sprachmodell basiert, hat es theoretisch das Potenzial für die Verarbeitung mehrerer Sprachen, aber der genaue Effekt muss anhand von tatsächlichen Tests bewertet werden. - Was ist das Prinzip der Verarbeitung von PDF-Dateien?
DeepSeek-OCR arbeitet selbst mit Bildern. Wenn eine PDF-Datei eingegeben wird, rendert (konvertiert) das Programm zunächst jede Seite der PDF-Datei in ein Bild, erkennt dann diese Bilder Seite für Seite und führt schließlich die Ergebnisse aller Seiten zu einer einzigen Ausgabe zusammen. - Kann ich es auch ohne NVIDIA-GPU verwenden?
Die offizielle Dokumentation und die Tutorials basieren auf NVIDIA GPU- und CUDA-Umgebungen. Obwohl das Modell theoretisch auch auf einer CPU laufen kann, ist es sehr langsam und für praktische Anwendungen nicht geeignet. Es wird daher dringend empfohlen, es auf einem Gerät mit einem NVIDIA-Grafikprozessor zu verwenden. - Was sind die Vorteile der "kontextbezogenen optischen Kompression"?
Der Hauptvorteil ist die Effizienz. Wenn herkömmliche Modelle lange Texte verarbeiten, steigt der Rechen- und Speicherbedarf mit der Länge des Textes drastisch an. Durch die Komprimierung von Textbildern in eine kleine Anzahl visueller Token kann DeepSeek-OCR denselben oder sogar noch längere Inhalte mit weniger Ressourcen verarbeiten, wodurch die Verarbeitung umfangreicher Dokumente auf begrenzter Hardware möglich wird.































