



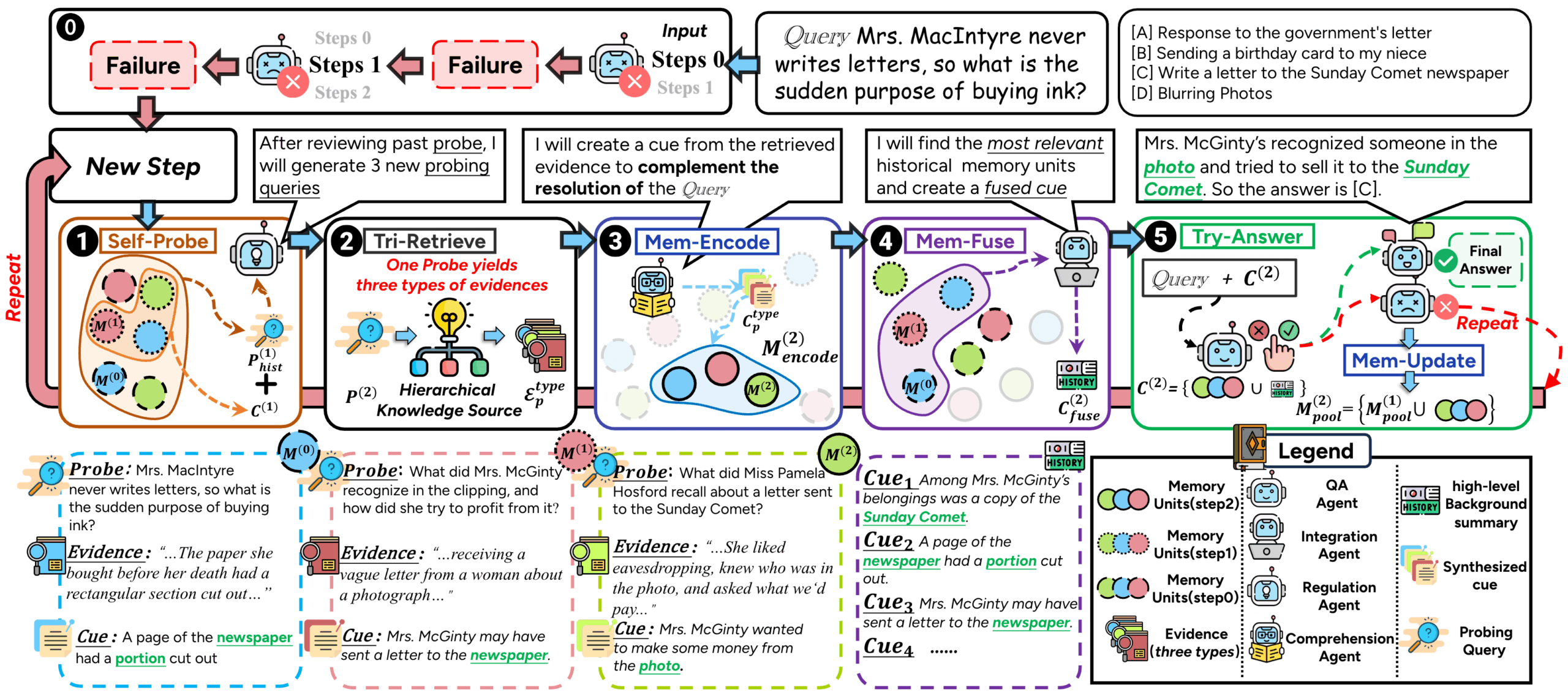
ComoRAG ist ein Retrieval Augmented Generation (RAG) System, das für lange Dokumente und das Verstehen von Erzählungen mit mehreren Dokumenten entwickelt wurde. Herkömmliche RAG-Methoden stoßen oft auf Schwierigkeiten, wenn sie mit langen Geschichten oder Romanen zu tun haben, die komplexe Handlungen und sich entwickelnde Charakterbeziehungen aufweisen. Dies liegt daran, dass die meisten von ihnen einen zustandslosen, einmaligen Abrufansatz verwenden, der es schwierig macht, weitreichende kontextuelle Assoziationen zu erfassen. ComoRAG ist vom menschlichen kognitiven Prozess inspiriert, der davon ausgeht, dass narratives Denken kein einmaliger Vorgang ist, sondern ein dynamischer, sich entwickelnder Prozess, der die Integration von neu erworbenen Erkenntnissen mit dem vorhandenen Wissen erfordert. Wenn ComoRAG auf Schwierigkeiten bei der Argumentation stößt, setzt es eine iterative Argumentationsschleife in Gang. Es generiert Sondierungsfragen, um neue Anhaltspunkte zu erkunden, und integriert die neu gewonnenen Informationen in einen globalen Speicherpool, so dass nach und nach ein kohärenter Kontext für die ursprüngliche Frage entsteht. Dieser Zyklus "Denken→Prüfen→Abrufen→Integrieren→Lösen" macht es besonders geeignet für die Bearbeitung komplexer Probleme, die ein globales Verständnis erfordern.
Funktionsliste
- Rahmen für das kognitive GedächtnisIn Anlehnung an die Art und Weise, wie das menschliche Gehirn Informationen verarbeitet, werden komplexe Probleme durch iterative Denkschleifen bearbeitet, um einen dynamischen, zustandsabhängigen Denkprozess zu erreichen.
- Unterstützung mehrerer ModelleIntegration und Unterstützung einer breiten Palette von Large Language Models (LLMs) und eingebetteten Modellen, so dass Benutzer eine Verbindung zur OpenAI API herstellen oder lokale vLLM-Server und eingebettete Modelle einsetzen können.
- Graph Enhanced SearchNutzung von Graphenstrukturen für Abfragen und Schlussfolgerungen, um komplexe Beziehungen zwischen Entitäten besser zu erfassen und zu verstehen.
- Flexible DatenverarbeitungBereitstellung von Werkzeugen zum Chunking von Dokumenten, Unterstützung von Token-, Wort-, Satz- und anderen Zerlegungsmethoden.
- Modularer AufbauDas System ist so konzipiert, dass es modular und erweiterbar ist, was eine sekundäre Entwicklung und Funktionserweiterung erleichtert.
- Automatisierte BewertungMit Auswertungsskripten, die eine Vielzahl von Indikatoren wie F1, EM (Exact Match) usw. unterstützen, lässt sich die Wirksamkeit von Q&A leicht quantitativ bewerten.
Hilfe verwenden
ComoRAG ist ein leistungsfähiges generatives Framework, das sich auf das Verstehen und die Argumentation bei der Verarbeitung langer narrativer Texte konzentriert. Es verbessert die Leistung des Modells bei Aufgaben wie der Abfrage von langen Texten und der Informationsextraktion durch eine einzigartige kognitive iterative Schleife erheblich.
Konfiguration und Installation der Umgebung
Bevor Sie das Programm verwenden können, müssen Sie die Laufzeitumgebung konfigurieren.
- Python-Version: Empfohlene Verwendung
Python 3.10oder höher. - Installation von AbhängigkeitenNachdem Sie den Projektcode geklont haben, installieren Sie alle erforderlichen Abhängigkeitspakete mit dem folgenden Befehl im Stammverzeichnis des Projekts. Für eine bessere Leistung wird eine GPU-Umgebung empfohlen.
pip install -r requirements.txt - UmgebungsvariableWenn Sie die OpenAI API verwenden wollen, müssen Sie die entsprechenden Umgebungsvariablen setzen
OPENAI_API_KEY. Wenn Sie ein lokales Modell verwenden, müssen Sie den Pfad zu diesem Modell konfigurieren.
Vorbereitung der Daten
ComoRAG benötigt Datendateien in einem bestimmten Format, um zu funktionieren. Sie müssen Korpusdateien und Q&A-Dateien vorbereiten.
- Korpusdatei (corpus.jsonl)Diese Datei enthält alle Dokumente, die abgerufen werden müssen. Die Datei ist
jsonlFormat, ist jede Zeile ein JSON-Objekt, das ein Dokument darstellt.idIdentifier: Ein eindeutiger Bezeichner für das Dokument.doc_idIdentifikator für die Gruppe oder das Buch, zu dem das Dokument gehört.title: Titel des Dokuments.contents: Der ursprüngliche Inhalt des Dokuments.
Beispiel:
{"id": 0, "doc_id": 1, "title": "第一章", "contents": "很久很久以前..."} - Q&A-Datei (qas.jsonl)Diese Datei enthält die Fragen, die vom Modell beantwortet werden müssen. Auch hier ist jede Zeile ein JSON-Objekt.
idEin eindeutiger Identifikator für die Ausgabe.question:: Spezifische Fragen.golden_answers:: Liste der Standardantworten auf Fragen.
Beispiel:
{"id": "1", "question": "故事的主角是谁?", "golden_answers": ["灰姑娘"]}
Chunking von Dokumenten
Da lange Dokumente nicht direkt vom Modell verarbeitet werden können, müssen sie zunächst in kleinere Teile zerlegt werden. Das Projekt bietet die chunk_doc_corpus.py Skript, um dies zu tun.
Sie können den Korpus mit folgendem Befehl zerlegen:
python script/chunk_doc_corpus.py \
--input_path dataset/cinderella/corpus.jsonl \
--output_path dataset/cinderella/corpus_chunked.jsonl \
--chunk_by token \
--chunk_size 512 \
--tokenizer_name_or_path /path/to/your/tokenizer
--input_pathPfad zur Original-Korpusdatei.--output_pathDer Pfad, in dem die Datei nach dem Chunking gespeichert werden soll.--chunk_by:: Chunking-Basis, die sein kanntoken、word或sentence。--chunk_sizeDie Größe der einzelnen Chunks.--tokenizer_name_or_pathToken: Gibt den Pfad zum Teilnehmer an, der für die Berechnung des Tokens verwendet wird.
Zwei Betriebsarten
ComoRAG kann auf zwei verschiedene Arten ausgeführt werden: über die OpenAI-API oder über einen lokal installierten vLLM-Server.
Modus 1: Verwendung der OpenAI-API
Dies ist der einfachste und schnellste Weg, um zu beginnen.
- Konfiguration ändern: Öffnen
main_openai.pyDatei, finden Sie dieBaseConfigTeilweise geändert.config = BaseConfig( llm_base_url='https://api.openai.com/v1', # 通常无需修改 llm_name='gpt-4o-mini', # 指定使用的OpenAI模型 dataset='cinderella', # 数据集名称 embedding_model_name='/path/to/your/embedding/model', # 指定嵌入模型的路径 embedding_batch_size=32, need_cluster=True, # 启用语义/情景增强 output_dir='result/cinderella', # 结果输出目录 ... ) - laufendes ProgrammSobald die Konfiguration abgeschlossen ist, führen Sie das Skript direkt aus.
python main_openai.py
Modus 2: Verwendung eines lokalen vLLM-Servers
Sie können diesen Modus wählen, wenn Sie über ausreichende Rechenressourcen (z. B. GPUs) verfügen und das Modell lokal ausführen möchten, um den Datenschutz zu gewährleisten und die Kosten zu senken.
- Starten des vLLM-ServersZunächst müssen Sie einen vLLM-Server starten, der mit der OpenAI-API kompatibel ist.
python -m vllm.entrypoints.openai.api_server \ --model /path/to/your/model \ --served-model-name your-model-name \ --tensor-parallel-size 1 \ --max-model-len 32768--model: Der Pfad zu Ihrem lokalen großen Sprachmodell.--served-model-name: Vergeben Sie einen Namen für Ihren Musterdienst.--tensor-parallel-sizeAnzahl der verwendeten GPUs.
- Überprüfung des Serverstatus: Sie können verwenden
curl http://localhost:8000/v1/modelsum zu überprüfen, ob der Server erfolgreich gestartet wurde. - Konfiguration ändern: Öffnen
main_vllm.pyDatei, ändern Sie die Konfiguration in dieser Datei.# vLLM服务器配置 vllm_base_url = 'http://localhost:8000/v1' served_model_name = '/path/to/your/model' # 与vLLM启动时指定的模型路径一致 config = BaseConfig( llm_base_url=vllm_base_url, llm_name=served_model_name, llm_api_key="EMPTY", # 本地服务器不需要真实的API Key dataset='cinderella', embedding_model_name='/path/to/your/embedding/model', # 本地嵌入模型路径 ... ) - laufendes ProgrammSobald die Konfiguration abgeschlossen ist, führen Sie das Skript aus.
python main_vllm.py
Bewertungsergebnisse
Nach Beendigung des Programms werden die erzeugten Ergebnisse in der Datei result/ Verzeichnis. Sie können das eval_qa.py Skripte zur automatischen Bewertung der Leistung des Modells.
python script/eval_qa.py /path/to/result/<dataset>/<subset>
Das Skript berechnet Metriken wie EM (Exact Match Rate) und F1 Score und generiert die results.json usw.
Anwendungsszenario
- Lange Geschichten/Drehbuchanalysen
Für Schriftsteller, Drehbuchautoren oder Literaturwissenschaftler kann ComoRAG als leistungsfähiges Analyseinstrument dienen. Die Benutzer können einen ganzen Roman oder ein Drehbuch importieren und dann komplexe Fragen zur Entwicklung der Handlung, zur Entwicklung der Beziehungen zwischen den Figuren oder zu bestimmten Themen stellen, und das System ist in der Lage, durch die Integration von Informationen aus dem gesamten Text Erkenntnisse zu liefern. - Wissensdatenbank Q&A auf Unternehmensebene
Innerhalb einer Organisation gibt es oft eine riesige Menge an technischer Dokumentation, Projektberichten und Regeln und Vorschriften. ComoRAG verarbeitet diese langen, komplexen und miteinander verbundenen Dokumente und baut ein intelligentes Q&A-System auf. Die Mitarbeiter können direkt in natürlicher Sprache Fragen stellen, wie z. B. "Was sind die wichtigsten Unterschiede und Risiken zwischen der technischen Umsetzung von Option A und Option B im Projekt Q3". Das System ist in der Lage, mehrere Berichte zu konsolidieren und genaue Antworten zu geben. - Studium von Rechtsinstrumenten und Fallakten
Anwälte und juristische Mitarbeiter müssen eine große Anzahl langer juristischer Dokumente und historischer Akten lesen. ComoRAG hilft ihnen dabei, den zeitlichen Ablauf eines Falles schnell zu sortieren, den Zusammenhang zwischen verschiedenen Beweisstücken zu analysieren und komplexe Fragen zu beantworten, die die Synthese mehrerer Dokumente erfordern, um zu einer Schlussfolgerung zu gelangen, was die Effizienz der Fallanalyse erheblich verbessert. - Wissenschaftliche Forschung und Literaturrecherche
ComoRAG kann Forschern dabei helfen, Fragen zu mehreren Veröffentlichungen in einem bestimmten Bereich zu stellen, Schlüsselinformationen zu extrahieren und einen Wissensgraphen zu erstellen, der ihnen hilft, die globale Dynamik und die zentralen Herausforderungen ihres Forschungsgebiets schnell zu erfassen.
QA
- Was sind die Hauptunterschiede zwischen ComoRAG und den traditionellen RAG-Methoden?
Der Hauptunterschied besteht darin, dass ComoRAG einen dynamischen, iterativen Denkprozess einführt, der von der Kognitionswissenschaft inspiriert ist. Während herkömmliche RAGs in der Regel einmalige, zustandslose Suchvorgänge sind, generiert ComoRAG aktiv neue Sondierungsfragen, wenn es auf schwer zu beantwortende Fragen stößt, und führt mehrere Such- und Informationskonsolidierungsrunden durch, um einen sich ständig erweiternden "Gedächtnispool" zu bilden, der bei der endgültigen Argumentation hilft. - Was sind die Voraussetzungen für die Verwendung eines lokalen vLLM-Servers?
Die Verwendung eines lokalen vLLM-Servers erfordert in der Regel einen leistungsstarken NVIDIA-Grafikprozessor und ausreichend Videospeicher, je nach Größe des zu ladenden Modells. Außerdem muss das CUDA-Toolkit installiert sein. Dieser Ansatz ist zwar anfangs kompliziert einzurichten, bietet aber eine höhere Datensicherheit und schnellere Inferenzen. - Kann ich mein eigenes eingebettetes Modell ersetzen?
Ja. Die Architektur von ComoRAG ist modular aufgebaut, und Sie können bequemembedding_modelKatalog, um Unterstützung für neue eingebettete Modelle hinzuzufügen. Stellen Sie einfach sicher, dass Ihr Modell Text in Vektoren umwandeln kann und passen Sie die Schnittstellen des Systems zum Laden und Aufrufen von Daten an. - Unterstützt dieser Rahmen die Verarbeitung multimodaler Daten wie Bilder oder Audio/Video?
Aus der grundlegenden Beschreibung des Projekts geht hervor, dass sich ComoRAG derzeit auf die Verarbeitung langer textueller Erzählungen konzentriert, wie z. B. lange Dokumente und Q&A mit mehreren Dokumenten. Während der modulare Aufbau die Möglichkeit bietet, die multimodalen Fähigkeiten in Zukunft zu erweitern, ist die Kernfunktionalität der aktuellen Version auf Textdaten ausgerichtet.
































