

Das dystopischste Drehbuch der Tech-Industrie spielt sich ab. Ein milliardenschwerer Sicherheitsgigant, der seine Anfänge in der Abwehr von automatisierten Bots hatte, hat es sich zur Aufgabe gemacht, das einfachste und vielleicht sogar leistungsfähigste automatisierte Crawler-Tool der Welt zu entwickeln.
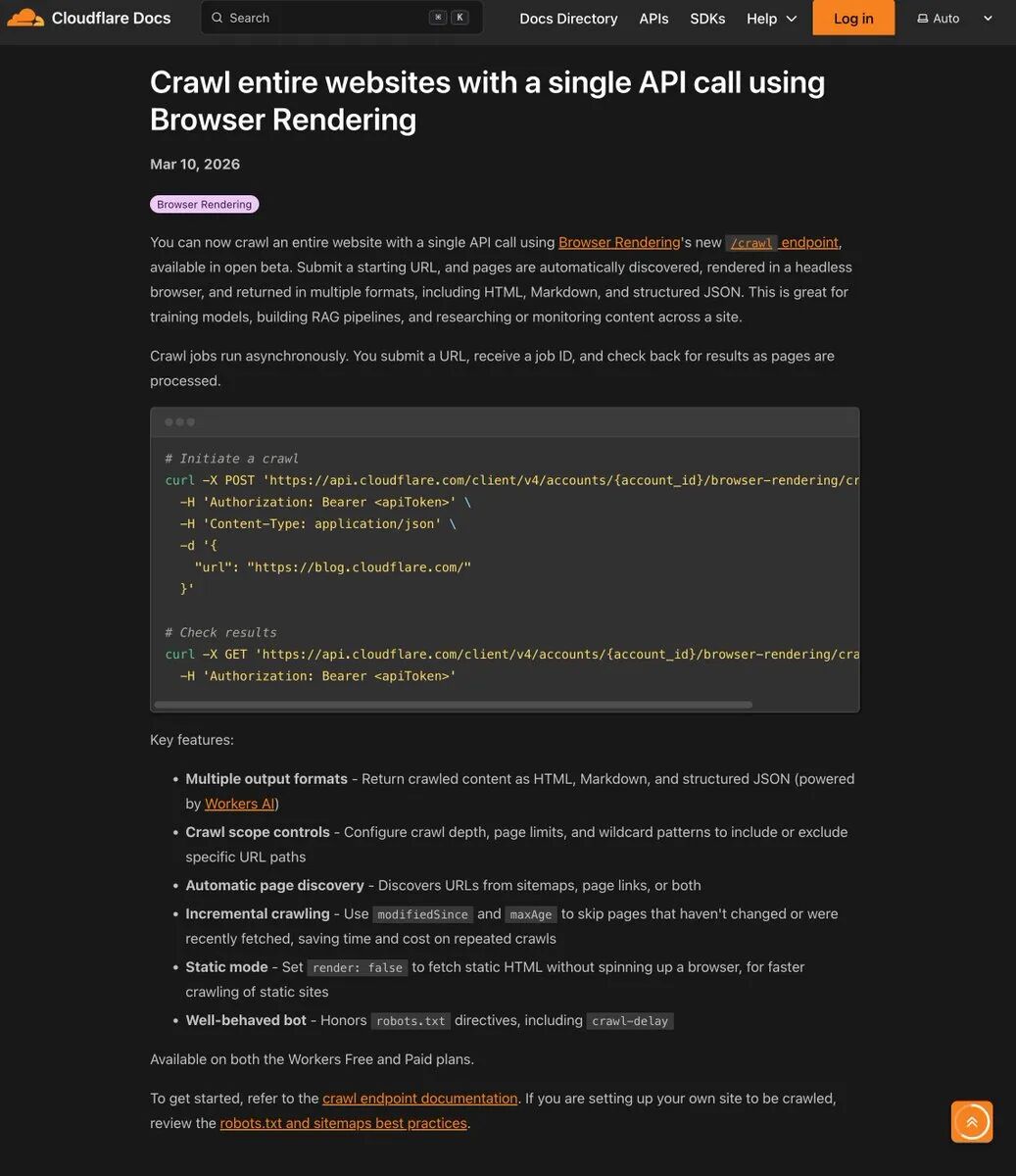
Im März 2026 ging Cloudflare mit einer neuen Beta-Funktion für Browser-Rendering live:/crawl API.
Sie müssen kein komplexes Framework konfigurieren, sich nicht mit CAPTCHA herumschlagen und keine Puppeteer- oder Playwright-Browser-Cluster auf einem Server mit Speicherlecks verwalten. Alles, was Sie tun müssen, ist, eine HTTP-POST-Anfrage mit einer Start-URL zu senden, und der Rest der Seitenerkennung, des JavaScript-Renderings und des Pagings wird vom globalen Edge-Netzwerk des Unternehmens erledigt. Am Ende des Tages wird es Ihnen sauberes HTML, Markdown oder strukturiertes JSON ausspucken.

Ironischerweise haben unzählige Entwickler in den letzten Jahren für die Dienste von Cloudflare bezahlt, um sich gegen Crawler zu schützen. Jetzt sehen sich dieselben Leute die Dokumentation an und lernen, wie sie die API von Cloudflare nutzen können, um die Websites anderer Leute zu crawlen.
Verborgene Ambitionen: Ein Rendering-Imperium mit 9 Endpunkten
Während alle Augen auf die /crawl Wenn es um den Schock geht, übersehen viele Menschen die dahinter stehende Infrastruktur./crawl Es ist kein isoliertes Hack-Spielzeug, sondern das letzte Puzzleteil in der gesamten REST-API-Matrix von Cloudflare Browser Rendering.
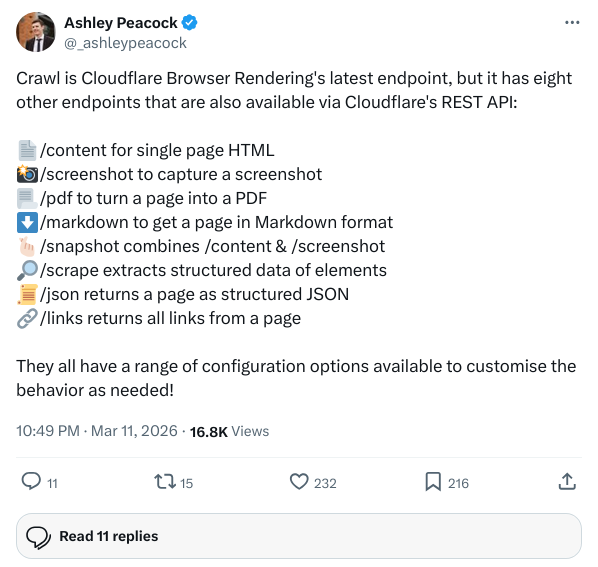
Schauen Sie sich die vollständige Liste der aktuellen Endpunkte genau an, und Sie werden feststellen, dass die Möglichkeiten des Browsers tatsächlich vollständig abgebaut wurden:
| Anfangs- oder Endpunkt (in Geschichten usw.) | Funktionelle Beschreibung |
|---|---|
/content |
Erhalten Sie eine vollständig gerenderte einzelne HTML-Seite |
/screenshot |
Visuelles Bildschirmfoto der Webseite |
/pdf |
Seite zu PDF |
/markdown |
Markdown-Extraktion für AI |
/snapshot |
Enthält einen hybriden Schnappschuss aus Inhalt und Bildmaterial |
/scrape |
Strukturiertes Crawling auf der Grundlage von DOM-Knoten |
/json |
Direkte Ausgabe der extrahierten strukturierten Daten in Kombination mit Workers AI |
/links |
Topo Crawl Essential Ganzseiten-Link-Extraktion |
/crawl |
Automatisierter Whole Site Crawl (neu hinzugekommen) |
In der Vergangenheit mussten Sie entweder das alte Scrapy verwenden, um statische Seiten zu erstellen, oder einen umfangreichen Satz von Node.js-Diensten aufbauen, um echte Browser auszuführen. Jetzt verwandelt Cloudflare diesen Prozess in zwei minimalistische Schritte:
- eine Aufgabe einleitenSenden Sie die Start-URL an
/crawlDie Job-ID einer asynchronen Ausführung ist sofort verfügbar. - Abfrage vonNehmen Sie die Job-ID und überprüfen Sie den Fortschritt. Die Aufträge können bis zu 7 Tage lang in ihrem Datenzentrum laufen und die Ergebnisse werden 14 Tage lang aufbewahrt.
Die in das System eingebauten Parameter bieten ein extrem hohes Maß an Kontrolle. Sie können die limit Um ein maximales Crawl-Limit von 100.000 Seiten festzulegen, verwenden Sie die depth Begrenzen Sie die Linktiefe, oder verwenden Sie die includePatterns usw. werden nur Inhalte unter einem bestimmten Pfad erfasst. Noch tödlicher ist die render Parameter. Wenn Sie nur rein statische Dokumentstationen crawlen müssen, setzen Sie die render einrichten als falsewird das Browser-Rendering übersprungen und die gleichzeitige Erfassung mit hoher Geschwindigkeit durchgeführt; wenn es sich um eine einseitige Anwendung (SPA) handelt, schalten Sie die render Sie können den Inhalt nach der Ausführung von JavaScript extrahieren.
Nullschwellige Fallstricke
Dieser infrastrukturelle Tiefschlag übt sofort eine Anziehungskraft auf das bestehende Unternehmens-Ökosystem aus.
Die Entwickler von RAG-Anwendungen (Retrieval Augmented Generation) sind die ersten Nutznießer. Große Modelle brauchen sauberen Text, HTML-Tags sind für sie ein Fremdwort. Wo Entwickler früher alle möglichen regulären Extraktoren und Bereinigungsskripte schreiben mussten, erhalten sie jetzt mit einer einzigen Anfrage direkt Markdown zurück. ai data engineers, Indie-Entwickler und sogar kleine Startup-Teams müssen nicht mehr eine spezielle Person einstellen, um eine Crawler-Pipeline zu pflegen.
Aber für die Unternehmen, die sich auf Crawler-SaaS spezialisiert haben, ist das so, als würde man die Hitze aus dem Feuer nehmen. Nehmen wir zum Beispiel Firecrawl, dessen Kerngeschäftsmodell darin besteht, Crawler in brauchbare APIs zu kapseln, und das wir jetzt mit Cloudflare auf den Tisch legen:
| Dimension (math.) | Cloudflare /crawl | Firecrawl |
|---|---|---|
| ursprüngliche Ausrichtung | APIs auf Infrastrukturebene | SaaS für vertikale Szenarien |
| Abrechnungsmodell | Browserbasierte Abrechnung | Abrechnung nach Anzahl der gecrawlten Seiten |
| Knotenpunktnetz | Großer globaler Pool von Edge-Knoten | Relativ eingeschränkte Serverexporte |
| Benutzerfreundlichkeit | Erfordert ein Cloudflare-Konto bei Workers. | Kinderleichte Registrierung und Nutzung |
| Strukturierte Extraktion | Native Integration Arbeitnehmer AI /json Anfangs- oder Endpunkt (in Geschichten usw.) |
Integrierte Extraktion großer Modelle für eine bessere Out-of-the-Box-Erfahrung |
Firecrawl ist immer noch führend bei der Produktverpackung und der Benutzerfreundlichkeit für Nutzer ohne technischen Hintergrund. Aber Cloudflare hat einen unüberwindbaren Graben: Rechenkosten und Knotengröße.
Solange Sie während des Beta-Tests das JavaScript-Rendering nicht einschalten (render: false), ist die Schnittstelle völlig kostenlos. Selbst mit aktiviertem Rendering bietet die kostenlose Version 10 Minuten Browserzeit pro Tag; die kostenpflichtige Version (ab 5 $ pro Monat) bietet 10 Stunden pro Monat und berechnet Ihnen für jede weitere Stunde nur 0,09 $ pro Stunde. Die stündliche Abrechnung kehrt die traditionelle Logik der Abrechnung pro Anfrage vollständig um, und bei hohem Crawling-Bedarf sind die Kosten fast vernachlässigbar.
sowohl Schild als auch Speer
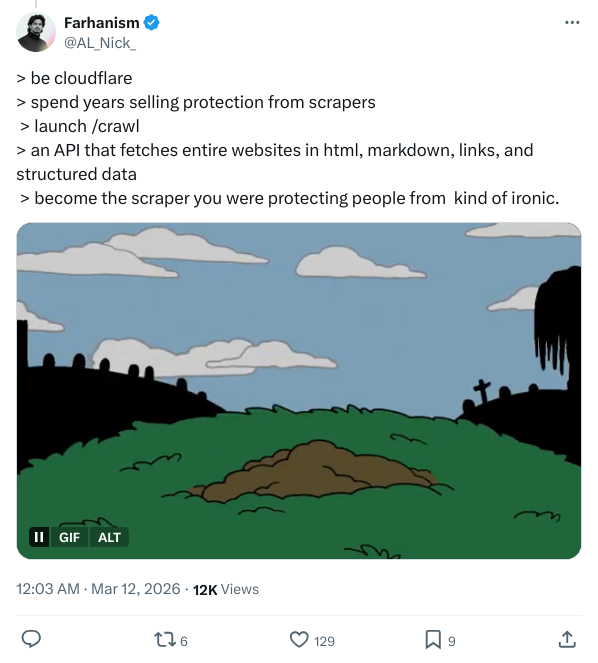
Zurück zur ursprünglichen Ironie. Die Aufregung im sozialen Netzwerk kam nicht von ungefähr. x Ein Tweet des Nutzers @AL_Nick_ traf die Logik des Unternehmens, Dinge zu tun, punktgenau:
be cloudflare
spend years selling protection from scrapers
launch /crawl
become the scraper you were protecting people from
Das dazugehörige Bild ist der klassische Satz von Batman: “Entweder du gehst als Held in den Ruhestand oder du erlebst, wie du ein Schurke wirst.”
Angesichts all der Kritik im Netz haben sich die Verantwortlichen von Cloudflare in den Kommentaren sehr geschickt verteidigt: Sie glauben, dass die Ursache für die gewalttätigen Crawler, die das Internet heute überschwemmen, darin liegt, dass “die Entwicklungskosten für einen höflichen Crawler zu hoch sind”. Daher bieten sie eine offizielle API an, die sich standardmäßig an robots.txt hält, die Häufigkeit der Gleichzeitigkeit kontrolliert, um den Zielserver nicht zu überfordern, und einen kanonischen User-Agent verwendet.
Das ist ein logisches Argument, aber es täuscht nicht über die geschäftliche Raffinesse hinweg. Die Realität liegt auf dem Tisch: Unternehmen, die für die fortschrittlichen WAFs von Cloudflare bezahlen, verfügen über Schutzmechanismen, die Cloudflare selbst daran hindern können, Daten zu versenden. /crawl Anfrage?
Ein Entwickler aus der chinesischen Community, @chuhaiqu, hat den Nagel auf den Kopf getroffen, als er sagte: “Früher verlangte man Geld dafür, dass man Crawler blockierte. Jetzt: man wird dafür bezahlt, dass man anderen beim Crawlen hilft”.”
Dies ist eigentlich das ultimative Privileg eines plattformbasierten Unternehmens. Durch die Kommerzialisierung der Crawling-Fähigkeiten stärkt Cloudflare die Abhängigkeit der Entwickler von seinem Workers-Computing-Ökosystem. Es ist ihnen egal, ob Sie andere crawlen oder andere daran hindern, Sie zu crawlen. Solange die Daten fließen und der Datenverkehr durch ihre Edge-Knoten läuft, ist der Zähler auf dem neuesten Stand.
Praktische Anwendung: Bereitstellung Ihrer Datenpumpe in fünf Minuten
Abgesehen von der Geschäftsethik ist dieses Tool aus der Sicht eines Entwicklers wirklich zu schön, um wahr zu sein. Alles, was Sie brauchen, ist ein Cloudflare-Konto mit aktivierten Workers und ein API-Token mit Browser-Rendering-Rechten.
Mit weniger als 30 Codezeilen können Sie eine vollständige Daten-Crawling-Aufgabe auf Website-Ebene durchführen:
async function crawlSite(url, apiToken, accountId) {
// 1. 发起 POST 请求,创建爬取任务
const startRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl`,
{
method: 'POST',
headers: {
'Authorization': `Bearer ${apiToken}`,
'Content-Type': 'application/json'
},
// 请求输出 Markdown,对于静态内容关闭渲染以加速
body: JSON.stringify({ url, formats:['markdown'], render: false })
}
);
const { result: jobId } = await startRes.json();
// 2. 轮询 GET 请求,等待庞大的任务集群完成作业
while (true) {
const checkRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}?limit=1`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
const data = await checkRes.json();
if (data.result.status !== 'running') break;
// 礼貌的等待时间
await new Promise(r => setTimeout(r, 3000));
}
// 3. 任务结束,提取洗净后的数据
const finalRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
return (await finalRes.json()).result.records;
}
Sie begleiteten sogar die Veröffentlichung der begleitenden MCP Server, d.h. Sie können den Cursor oder Claude KI-IDEs wie diese rufen das System direkt über natürliche Sprache auf. Welche Daten Sie benötigen, die KI ruft automatisch diese minimalistische API auf, um sie zurückzuholen.
Die alten Schranken bröckeln, und die Grenzkosten des Datenzugangs nähern sich unaufhaltsam dem Nullpunkt. Das sind absolut schlechte Nachrichten für die Verfechter offener Inhalte im Internet.





































