

Vorwort
Das Wissen eines großen Sprachmodells (Large Language Model, LLM) ist durch den Stichtag seiner Trainingsdaten begrenzt. Ein Modell, das vor Januar 2025 trainiert wurde, kann beispielsweise keine Antworten auf Ereignisse geben, die seither eingetreten sind, wie etwa die Frage nach dem aktuellen Datum. Die Ausstattung von Modellen mit vernetzten Suchfunktionen, die es ihnen ermöglichen, auf der Grundlage von Echtzeitinformationen zu antworten, kann ihre Anwendungsszenarien erheblich erweitern und die Genauigkeit ihrer Antworten verbessern. Cherry Studio Es werden eine Reihe von vernetzten Suchfunktionen angeboten, die es jedem Modell ermöglichen, sich mit dem Internet zu verbinden.

Dieser Artikel beschreibt die Cherry Studio Die Netzwerk-Suchfunktion bietet einen detaillierten Konfigurations- und Praxisleitfaden.
Funktion Konfiguration
Bevor Sie die vernetzte Suche verwenden, müssen Sie sie entsprechend konfigurieren. Öffnen Sie die Cherry Studio Auf dem Einstellungsbildschirm konzentriert sich der rechte Bereich auf alle Optionen für die Websuche.
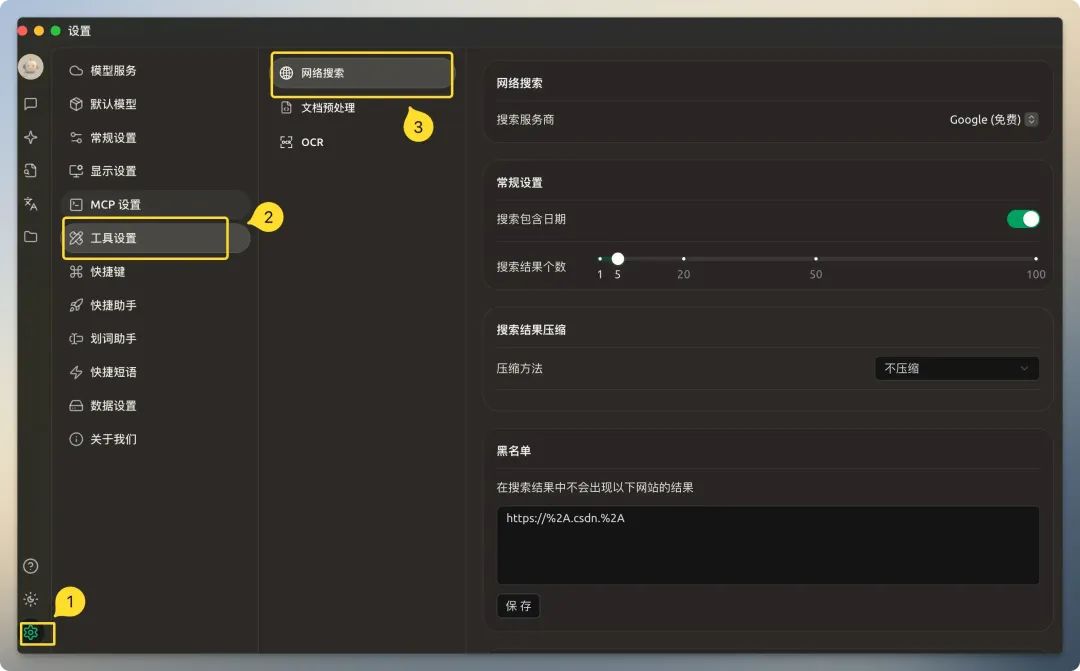
Suchdienstanbieter
Cherry Studio Eine Vielzahl von Suchanbietern ist integriert. Sie lassen sich in zwei Hauptkategorien einteilen:Traditionelle Suchmaschinen(z.B.. 百度、谷歌、必应undNative AI-Suchmaschine(z.B.. Tavily、Exa)。
Traditionelle SuchmaschinenWas zurückgegeben wird, ist eine komplette Webseite, die für das visuelle Lesen durch den Menschen konzipiert wurde und eine Menge "Rauschen" wie Navigationsleisten, Werbung, Skripte usw. enthält, die nichts mit dem Kerninhalt zu tun haben. Wenn diese Informationen direkt in das KI-Modell eingespeist werden, steigen nicht nur die Kosten für das Token drastisch an, sondern auch die Qualität der Antwort wird durch die Informationsverschmutzung verringert.
Native AI-SuchmaschineAndererseits sind sie auf die Bereitstellung großer Sprachmodelle spezialisiert. Sie haben die Suchergebnisse im Back-End vorverarbeitet und optimiert und liefern saubere, verfeinerte, strukturierte Textdaten, die sich besser für die direkte maschinelle Verarbeitung eignen.

Tavily
Tavily ist ein Dienstleistungsanbieter, der sich auf Such-APIs für große Sprachmodelle spezialisiert hat. Seine Hauptstärke ist die Fähigkeit, hochrelevante, verfeinerte und strukturierte Daten zurückzugeben, indem irrelevante Informationen aus herkömmlichen Webseiten herausgefiltert werden, wodurch der Umfang und die Kosten des dem Modell zugeführten Kontexts reduziert werden.Tavily s kostenloser Plan bietet 1.000 API-Aufrufe pro Monat ohne Kreditkartenbindung und direkten Zugang innerhalb Chinas. Nach der Anmeldung erhalten Sie einfach den API-Schlüssel im Backend und füllen die entsprechenden Felder aus.


Searxng
Searxng ist eine quelloffene Meta-Suchmaschine (https://github.com/searxng/searxng), der Ergebnisse aus mehreren Suchdiensten zusammenfasst. Die Nutzer können sich auf die offizielle Dokumentation beziehen, um den Dienst selbst einzurichten und so den Datenschutz und die Kontrolle zu verbessern.

Exa
Exa (ehemals Metaphor) ist ein weiterer KI-orientierter Suchanbieter, dessen beste Eigenschaft darin besteht, dass er eine neuronale Suche auf der Grundlage von "Semantik" anbietet. Im Gegensatz zur traditionellen Suche, die auf der Übereinstimmung von Schlüsselwörtern beruhtExa Es versteht die wahre Absicht hinter einer Anfrage besser (wenn Sie zum Beispiel nach "wie wird die Zukunft der KI-Telefone aussehen" suchen, versteht es, dass dies eine offene, konzeptionelle Frage ist), um tiefergehende und relevantere Ergebnisse zu finden. Sie unterstützt auch bereichsspezifische Suchen, z. B. nach Aufsätzen,Github Warehouse und Wikipedia. Neue Benutzer erhalten ein kostenloses Guthaben von 10 $.


Bocha
inländisch 博查 Es bietet auch einen multimodalen KI-Such-API-Dienst an, aber sein Dienst ist ein rein kostenpflichtiges Modell ohne kostenlose Credits.

Kürzlich eingeführt Mit der drohenden Einstellung der Bing Search API, könnte die Secret Tower API eine neue Option sein?Auch neue Optionen.
Allgemeine Einstellungen
Einschalten empfohlen "Suche enthält Datum" für weitere aktuelle Informationen. Es wird empfohlen, die Anzahl der Suchergebnisse auf dem Standardwert von 5 zu belassen. Wenn Sie zu viele Ergebnisse einstellen, erhöht sich nicht nur der Token-Verbrauch, sondern es kann auch zu Verarbeitungsfehlern kommen, weil das Kontextfenster des Modells überschritten wird.

Suchergebnisse Kompression
Diese Funktion wird verwendet, um den Inhalt der gesuchten Webseiten zu verarbeiten und zu verfeinern, damit er den kontextuellen Beschränkungen des Modells entspricht. Das Verständnis der Unterschiede zwischen diesen drei Optionen ist entscheidend für die Optimierung der Effizienz und der Kosten der vernetzten Suche.

| Komprimierungsverfahren | Blickwinkel | Nachteile | Anwendbare Szenarien |
|---|---|---|---|
| unkomprimiert | Einfach zu implementieren und schnell zu bearbeiten. | Hohe Anfälligkeit für die Überschreitung von Modellkontextgrenzen, hohe Token-Kosten und viele irrelevante Informationen. | Nur gelegentlich verfügbar, wenn das Modellkontextfenster sehr groß ist und die Suchergebnisseite sehr übersichtlich ist. |
| abschneiden. | Die Kontrolle ist einfach und direkt und kann Überschreitungen wirksam vermeiden. | Es kann dazu führen, dass Inhalte abgeschnitten werden, bevor wichtige Informationen verfügbar sind, was zu Informationsverlusten führt. | Schnelle, kostengünstige Suche nach Modellen mit begrenzten Kontextfenstern, wobei jedoch das Risiko unvollständiger Informationen in Kauf genommen wird. |
| RAG | Höchste Genauigkeit bei der Erkennung und Bereitstellung der relevantesten Informationen, wodurch die "KI-Illusion" wirksam reduziert wird. | Konfiguration und Berechnung sind relativ komplex, mit einigen Anforderungen an das Einbettungsmodell. | Dies ist der fortschrittlichste und empfohlene Ansatz für ernsthafte Anfragen, bei denen die Qualität der Antwort hoch ist. |
- unkomprimiertBereitstellung der Original-Webinhalte direkt am Modell.
- abschneiden.Hard Truncation: Hartes Abschneiden überlanger Inhalte durch Festlegen der Anzahl der Zeichen oder der Tokenanzahl. Dies ist eine einfache und brutale Kontrollmethode, aber das Risiko besteht darin, dass sich kritische Informationen im abgeschnittenen Teil befinden können.
- RAGDiese Option ist nicht einfach "Kompression", sondern steht für Suche Verbesserte Generation(Retrieval-Augmented Generation).
RAGist ein fortschrittliches KI-Framework, das zunächst relevante Informationen aus einer externen Wissensdatenbank abruft und diese Informationen dann zusammen mit der ursprünglichen Frage des Nutzers an das Modell weiterleitet, damit dieses genauere und zuverlässigere Antworten generieren kann. Sein Arbeitsprinzip lässt sich wie folgt vereinfachen: Es nutzt zunächst die Modelle einbetten Alle gesuchten Textabschnitte und Benutzerfragen werden in numerische Vektoren umgewandelt, und dann wird die Ähnlichkeit im Vektorraum berechnet, um die relevantesten Textabschnitte für die Benutzerfrage herauszufinden. Schließlich werden nur diese hochrelevanten Segmente als Kontext für das größere Modell bereitgestellt. Dies ist so, als würde das Modell eine "offene Prüfung" ablegen und direkt zu den Seiten mit den richtigen Antworten blättern, wodurch die aktuellsten Daten effizient genutzt werden und die Wahrscheinlichkeit, dass das Modell "halluziniert" (d. h. Fakten erfindet), erheblich verringert wird. AuswahlRAGNach der Komprimierungsmethode müssen Sie auch dieEmbeddingParameter wie das Modell und die Einbettungsdimension.

Schwarze Listen und Abonnements
- schwarze ListenUnterstützt die Verwendung von regulären Ausdrücken, um Suchergebnisse für bestimmte Seiten herauszufiltern, z.B. um Seiten mit minderwertigem Inhalt zu blockieren.
- Blacklist-AbonnementDurch das Abonnieren von Links auf der schwarzen Liste, die von der Gemeinschaft gepflegt werden (z.B.
https://git.io/ublacklist) können Sie bekanntermaßen minderwertige oder spammige Websites in großen Mengen blockieren, ohne sie manuell einzeln hinzufügen zu müssen.


Exkursion an Ort und Stelle
Cherry Studio Die verbundenen Suchvorgänge lassen sich in zwei Kategorien einteilen: modellinterne Suchvorgänge und Suchdienste von Dritten.
Modell Eingebaute Suche
Einige Modellanbieter (z.B. OpenRouter) hat eine integrierte Netzwerk-Suchfunktion in seine Modelle integriert. Diese Funktion kann direkt in den Modelleinstellungen aktiviert werden.

以 OpenRouter Kostenlose Modelle angeboten Kimi K2 Ist die Suche beispielsweise ausgeschaltet, kann sie das aktuelle Datum nicht beantworten; ist sie eingeschaltet, antwortet sie korrekt und liefert die Quelle der Information. Es ist wichtig zu beachten, dass einige Modelle zwar behaupten, die Vernetzung zu unterstützen, in der Praxis aber ineffektiv sind oder nicht richtig funktionieren (z. B. bestimmte GitHub Models)。
Wenn Sie keine geeignete kostenlose API für große Modelle gefunden haben, können Sie hier eine auswählen:Freie Big Model API-Liste
Suchdienste von Drittanbietern
Wenn das Modell nicht über integrierte Suchfunktionen verfügt, wird ein Suchdienst eines Drittanbieters zum Schlüssel. Bei dessen Nutzung treten jedoch zwei Hauptprobleme auf:
- Erhöhter Token-Verbrauch
- Fehlschlag aufgrund langer Suchergebnisse, die die Grenzen des Modellkontexts überschreiten
Cherry Studio Der Prozess der Suche nach Dritten ist in zwei Phasen unterteilt:
Stufe 1: Extraktion von Suchbegriffen und Beschaffung von Inhalten
Wenn ein Nutzer eine Frage sendet, gibt das System die ursprüngliche Frage nicht direkt an die Suchmaschine weiter. Stattdessen ruft es zunächst das große Modell auf und verwendet eine ausgeklügelte Eingabeaufforderungsvorlage, die es dem Modell ermöglicht, die Absicht des Nutzers zu analysieren und prägnante Schlüsselwörter zu extrahieren, die sich am besten für die Verwendung in der maschinellen Suche eignen. Dieser Ansatz ist bekannt alsUmformulierung von Anfragen (Query Rewriting)die die Genauigkeit der nachfolgenden Suchvorgänge erheblich verbessern können.

unter Cherry Studio Schlüsselwort-Extraktor Prompt Vorlage. Wie Sie sehen können, verwendet es XML-Tags (wie<websearch>), um das Modell zu zwingen, strukturierte Inhalte auszugeben, die direkt vom Programm geparst werden können, eine übliche "strukturierte Prompt"-Technik.
You are an AI question rephraser. Your role is to rephrase follow-up queries from a conversation into standalone queries that can be used by another LLM to retrieve information through web search.
**Use user's language to rephrase the question.**
Follow these guidelines:
1. If the question is a simple writing task, greeting (e.g., Hi, Hello, How are you), or does not require searching for information (unless the greeting contains a follow-up question), return 'not_needed' in the 'question' XML block. This indicates that no search is required.
2. If the user asks a question related to a specific URL, PDF, or webpage, include the links in the 'links' XML block and the question in the 'question' XML block. If the request is to summarize content from a URL or PDF, return 'summarize' in the 'question' XML block and include the relevant links in the 'links' XML block.
3. For websearch, You need extract keywords into 'question' XML block.
4. Always return the rephrased question inside the 'question' XML block. If there are no links in the follow-up question, do not insert a 'links' XML block in your response.
5. Always wrap the rephrased question in the appropriate XML blocks: use <websearch></websearch> for queries requiring real-time or external information. Ensure that the rephrased question is always contained within a <question></question> block inside the wrapper.
6. *use websearch to rephrase the question*
There are several examples attached for your reference inside the below 'examples' XML block.
<examples>
1. Follow up question: What is the capital of France
Rephrased question:`
<websearch>
<question>
Capital of France
</question>
</websearch>
`
2. Follow up question: Hi, how are you?
Rephrased question:`
<websearch>
<question>
not_needed
</question>
</websearch>
`
3. Follow up question: What is Docker?
Rephrased question: `
<websearch>
<question>
What is Docker
</question>
</websearch>
`
4. Follow up question: Can you tell me what is X from https://example.com
Rephrased question: `
<websearch>
<question>
What is X
</question>
<links>
https://example.com
</links>
</websearch>
`
5. Follow up question: Summarize the content from https://example1.com and https://example2.com
Rephrased question: `
<websearch>
<question>
summarize
</question>
<links>
https://example1.com
</links>
<links>
https://example2.com
</links>
</websearch>
`
6. Follow up question: Based on websearch, Which company had higher revenue in 2022, "Apple" or "Microsoft"?
Rephrased question: `
<websearch>
<question>
Apple's revenue in 2022
</question>
<question>
Microsoft's revenue in 2022
</question>
</websearch>
`
7. Follow up question: Based on knowledge, Fomula of Scaled Dot-Product Attention and Multi-Head Attention?
Rephrased question: `
<websearch>
<question>
not_needed
</question>
</websearch>
`
</examples>
Anything below is part of the actual conversation. Use the conversation history and the follow-up question to rephrase the follow-up question as a standalone question based on the guidelines shared above.
<conversation>
{chat_history}
</conversation>
**Use user's language to rephrase the question.**
Follow up question: {question}
Rephrased question:
Phase 2: Integration von Informationen und Erarbeitung von Antworten
Das System "komprimiert" die in der ersten Phase gewonnenen Webinhalte, integriert sie mit der ursprünglichen Frage des Nutzers und sendet sie erneut an das Modell, das auf der Grundlage dieser Echtzeitinformationen die endgültige Antwort erstellt.

Dieser zweistufige Prozess erklärt den Anstieg des Token-Verbrauchs: ein API-Aufruf für die Schlagwortextraktion und ein API-Aufruf für die endgültige Antwortgenerierung. Die Gesamtkosten entsprechen in etwa den Kosten für zwei separate Dialoge, und die Eingabe des zweiten Dialogs enthält ebenfalls eine große Anzahl von Websuchergebnissen.
Deshalb ist "Komprimierungsverfahren" Die Einstellungen sind entscheidend. Wählen Sie "Abgeschnitten". 或 "RAG" Sie soll dieses Problem angehen.

In der Praxis hat sich gezeigt, dass die Wahl des Suchdienstanbieters die Fehlerquote erheblich beeinflusst. Die Verwendung von Google、Baidu Wenn herkömmliche Suchmaschinen wie diese vollständige, unbearbeitete HTML-Seiten zurückgeben, neigen sie zu Überläufen, selbst wenn das Modellkontextfenster groß ist. Statt der Verwendung von Tavily 或 Exa Diese Art von Dienstleistern, die für KI konzipiert sind, haben eine viel geringere Fehlerquote, da sie vorverarbeitete Daten zurückliefern, die sauberer und übersichtlicher sind und sich natürlich für die Modellverarbeitung eignen.
Wenn beispielsweise die Suchergebnisse auf 20 festgelegt sind, die Komprimierungsmethode "keine Komprimierung" ist und ein Modell mit einem kleinen Kontextfenster (z. B. 8.000 Token) verwendet wird, steigt die Wahrscheinlichkeit des Scheiterns einer vernetzten Suche erheblich.

Empfehlungen für die Verwendung
Getestet.OpenRouter und Googles Gemini Bietet eine gute Erfahrung mit eingebauten vernetzten Suchen. Wenn Sie einen Suchdienst eines Drittanbieters verwenden müssen, beachten Sie diese Empfehlungen, um Stabilität und Effizienz zu gewährleisten:
- Vorrangige Nutzung der integrierten Suchfunktion des ModellsWenn das Modell selbst dies unterstützt, ist dies der einfachste und unkomplizierteste Weg, dies zu tun.
- Wählen Sie einen für KI konzipierten Suchdienst: Verwendung
Tavily、Exaund anderen Dienstleistern, anstattGoogle或Baidu. Sie liefern sauberere, relevantere Ergebnisse und verringern den Token-Verbrauch und das Risiko von Verarbeitungsfehlern. - Rationalisierung der Suchparameter: sorgfältig auf die Größe des Kontextfensters des verwendeten Modells abgestimmt Anzahl der Ergebnisse 和 Komprimierungsverfahren(Sehr empfehlenswert, wenn Qualität wichtig ist)
RAG), um Suchabbrüche aufgrund von Überschreitungen des Inhalts zu vermeiden.

































