



ARC-Hunyuan-Video-7B ist ein quelloffenes multimodales Modell, das vom ARC Lab von Tencent entwickelt wurde und sich auf das Verständnis von nutzergenerierten kurzen Videoinhalten konzentriert. Es bietet eine tiefgreifende strukturierte Analyse durch die Integration von visuellen, Audio- und Textinformationen aus Videos. Das Modell kann mit komplexen visuellen Elementen, dichten Audioinformationen und schnellen Kurzvideos umgehen und eignet sich für Szenarien wie Videosuche, Inhaltsempfehlungen und Videozusammenfassung. Das Modell ist mit 7B-Parametern skaliert und wird in mehreren Stufen trainiert, darunter Pre-Training, Feinabstimmung der Anweisungen und Reinforcement Learning, um eine effiziente Inferenz und eine hohe Qualität der Ergebnisse zu gewährleisten. Benutzer können über GitHub auf den Code und die Modellgewichte zugreifen, um eine einfache Bereitstellung in Produktionsumgebungen zu ermöglichen.
Funktionsliste
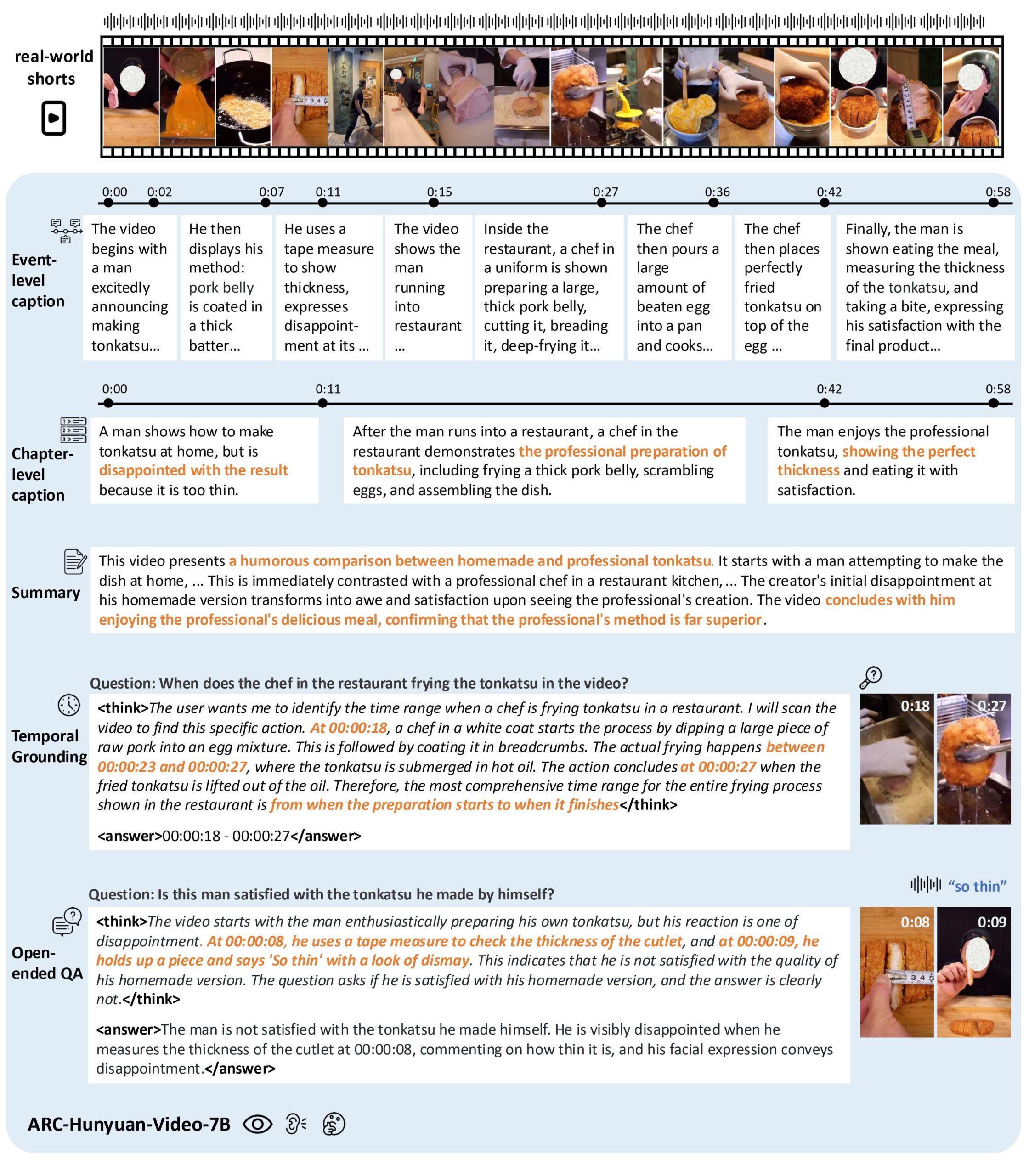
- Verstehen von Videoinhalten: Analyse von Bild, Ton und Text von kurzen Videos, um Kerninformationen und emotionale Ausdrücke zu extrahieren.
- Zeitstempel-Anmerkung: Unterstützung von Multi-Granularität Zeitstempel Video-Beschreibung, genaue Kommentierung der Zeit des Ereignisses.
- Video-Quiz: Beantworten Sie offene Fragen zum Inhalt des Videos und verstehen Sie die komplexen Szenarien im Video.
- Zeitliche Verortung: Finden Sie bestimmte Ereignisse oder Clips in einem Video, unterstützen Sie die Videosuche und -bearbeitung.
- Videozusammenfassung: Generieren Sie eine prägnante Zusammenfassung des Videoinhalts, die die wichtigsten Informationen hervorhebt.
- Mehrsprachige Unterstützung: Unterstützung für die Analyse chinesischer und englischer Videoinhalte, speziell optimiert für die Verarbeitung chinesischer Videos.
- Effiziente Argumentation: Unterstützung vLLM Beschleunigte, 1-minütige Videoüberlegungen in 10 Sekunden.
Hilfe verwenden
Einbauverfahren
Um ARC-Hunyuan-Video-7B zu verwenden, müssen die Benutzer das GitHub-Repository klonen und die Umgebung konfigurieren. Nachfolgend finden Sie die detaillierten Schritte:
- Klon-Lager:
git lfs install git clone https://github.com/TencentARC/ARC-Hunyuan-Video-7B cd ARC-Hunyuan-Video-7B - Installation von Abhängigkeiten:
Stellen Sie sicher, dass Python 3.8+ und PyTorch 2.1.0+ (mit CUDA 12.1 Unterstützung) auf Ihrem System installiert sind. Führen Sie den folgenden Befehl aus, um die erforderlichen Bibliotheken zu installieren:pip install -r requirements.txt - Download Modellgewichte:
Die Modellgewichte werden bei Hugging Face gehostet. Benutzer können sie mit dem folgenden Befehl herunterladen:from huggingface_hub import hf_hub_download hf_hub_download(repo_id="TencentARC/ARC-Hunyuan-Video-7B", filename="model_weights.bin", repo_type="model")Oder laden Sie sie manuell direkt von Hugging Face herunter und platzieren Sie sie in der
experiments/pretrained_models/Katalog. - vLLM installieren (optional):
Um das Denken zu beschleunigen, wird empfohlen, vLLM zu installieren:pip install vllm - Überprüfung der Umgebung:
Führen Sie das vom Repository bereitgestellte Testskript aus, um zu prüfen, ob die Umgebung korrekt konfiguriert ist:python test_setup.py
Verwendung
ARC-Hunyuan-Video-7B unterstützt den lokalen Betrieb und den Online-API-Aufruf. Im Folgenden wird der Ablauf der Hauptfunktion beschrieben:
1. das Verstehen von Videoinhalten
Die Benutzer können eine kurze Videodatei (z. B. im MP4-Format) eingeben, und das Modell analysiert den visuellen, akustischen und textlichen Inhalt des Videos und gibt eine strukturierte Beschreibung aus. Wenn beispielsweise ein lustiges TikTok-Video eingegeben wird, kann das Modell die Aktionen, Dialoge und Hintergrundmusik im Video extrahieren und eine detaillierte Beschreibung des Ereignisses erstellen.
Verfahren:
- Bereiten Sie die Videodatei vor, indem Sie die
data/input/Katalog. - Führen Sie das Argumentationsskript aus:
python inference.py --video_path data/input/sample.mp4 --task content_understanding - Die Ausgabe wird in der Datei
output/Ein Katalog im JSON-Format, der eine detaillierte Beschreibung des Videoinhalts enthält.
2. die Kennzeichnung mit Zeitstempeln
Das Modell unterstützt die Erstellung von Beschreibungen mit Zeitstempel für Videos, die sich für Anwendungen eignen, die eine genaue Lokalisierung von Ereignissen erfordern, wie z. B. Videoclips oder Suchvorgänge.
Verfahren:
- Verwenden Sie den folgenden Befehl, um die Zeitstempel-Anmerkung auszuführen:
python inference.py --video_path data/input/sample.mp4 --task timestamp_captioning - Beispielhafte Ausgabe:
[ {"start_time": "00:01", "end_time": "00:03", "description": "人物A进入画面,微笑挥手"}, {"start_time": "00:04", "end_time": "00:06", "description": "背景音乐响起,人物A开始跳舞"} ]
3. ein Video-Quiz
Die Benutzer können offene Fragen zum Video stellen, und das Modell kombiniert visuelle und akustische Informationen, um sie zu beantworten. Zum Beispiel: "Was machen die Figuren in dem Video?" oder "Welche Emotion drückt das Video aus?"
Verfahren:
- Erstellen einer Ausgabedatei
questions.jsonDas Format ist wie folgt:[ {"video": "sample.mp4", "question": "视频中的主要活动是什么?"} ] - Führen Sie das Quiz-Skript aus:
python inference.py --question_file questions.json --task video_qa - Die Ausgabe erfolgt im JSON-Format und enthält die Antwort auf die Frage.
4. zeitliche Orientierung
Mit der Zeitsuchfunktion können Sie Clips zu bestimmten Ereignissen in einem Video finden. Suchen Sie zum Beispiel einen Clip mit "tanzenden Menschen".
Verfahren:
- Führen Sie das Positionierungsskript aus:
python inference.py --video_path data/input/sample.mp4 --task temporal_grounding --query "人物跳舞" - Die Ausgabe erfolgt in einem bestimmten Zeitraum, z. B.
00:04-00:06。
5) Video-Zusammenfassung
Das Modell erstellt eine prägnante Zusammenfassung des Videoinhalts und hebt die Kernaussage hervor.
Verfahren:
- Führen Sie das Zusammenfassungsskript aus:
python inference.py --video_path data/input/sample.mp4 --task summarization - Beispielhafte Ausgabe:
视频展示了一位人物在公园跳舞,背景音乐欢快,传递了轻松愉快的情绪。
6. online API-Nutzung
Tencent ARC bietet eine Online-API, auf die über Hugging Face oder offizielle Demos zugegriffen werden kann. Besuchen Sie die Demoseite, laden Sie ein Video hoch oder geben Sie eine Frage ein, und das Modell liefert Ergebnisse in Echtzeit.
Verfahren:
- Besuchen Sie die Demoseite ARC-Hunyuan-Video-7B von Hugging Face.
- Probleme beim Hochladen von Videodateien oder beim Tippen.
- Anzeige der Ausgabeergebnisse und Unterstützung des Herunterladens von Analysedaten im JSON-Format.
caveat
- VideoauflösungDie Online-Demo verwendet eine komprimierte Auflösung, was die Leistung beeinträchtigen kann. Es wird empfohlen, sie lokal auszuführen, um beste Ergebnisse zu erzielen.
- Hardware-VoraussetzungNVIDIA H20 GPUs oder höher werden empfohlen, um die Geschwindigkeit der Inferenzen zu gewährleisten.
- Sprachliche UnterstützungDas Modell ist besser für chinesische Videos optimiert und schneidet bei englischen Videos etwas schlechter ab.
Anwendungsszenario
- Video-Suche
Die Nutzer können mit Hilfe von Schlüsselwörtern nach bestimmten Ereignissen oder Inhalten in einem Video suchen, z. B. nach "Kochanleitungen" oder "lustigen Clips" auf einer Videoplattform. - Inhaltliche Empfehlung
Das Modell analysiert die Kernaussage und die Stimmung des Videos, um der Plattform zu helfen, Inhalte zu empfehlen, die den Interessen des Nutzers entsprechen, z. B. kurze Videos mit peppiger Musik. - Videoclip
Mithilfe der Funktionen zur Zeitstempelbeschriftung und Zeitpositionierung können Creators schnell wichtige Clips aus Videos extrahieren, um Highlight-Clips zu erstellen. - Bildung und Ausbildung
In Lehrvideos kann das Modell Zusammenfassungen erstellen oder Fragen der Schüler beantworten, um ein schnelles Verständnis des Kursinhalts zu ermöglichen. - Analyse sozialer Medien
Marken können nutzergenerierte Inhalte auf TikTok oder WeChat analysieren, um die emotionalen Reaktionen und Vorlieben ihrer Zielgruppe zu verstehen.
QA
- Welche Videoformate unterstützt das Modell?
Gängige Formate wie MP4, AVI und MOV werden unterstützt, und es wird empfohlen, die Videodauer auf 1-5 Minuten zu begrenzen, um eine optimale Leistung zu erzielen. - Wie kann die Geschwindigkeit des Denkens optimiert werden?
Verwenden Sie vLLM, um die Inferenz zu beschleunigen, und stellen Sie sicher, dass der Grafikprozessor CUDA 12.1 unterstützt. - Unterstützt es lange Videos?
Das Modell ist hauptsächlich für kurze Videos (weniger als 5 Minuten) optimiert. Längere Videos müssen in Segmenten verarbeitet werden, und es wird empfohlen, das Video mithilfe eines Vorverarbeitungsskripts aufzuteilen. - Unterstützt das Modell die Echtzeitverarbeitung?
Ja, beim Einsatz von vLLM dauert die Inferenz eines einminütigen Videos nur 10 Sekunden und ist damit für Echtzeitanwendungen geeignet.






























