



Any LLM in Claude Code ist ein auf GitHub gehostetes Open-Source-Proxy-Tool, das von chachako entwickelt und von CogAgent/claude-code-proxy abgekupfert wurde. es ermöglicht Benutzern Claude Code LiteLLM kann jedes von LiteLLM unterstützte Sprachmodell (z. B. Modelle von OpenAI, Vertex AI, xAI) ohne Pro-Abonnement verwenden. Mit einer einfachen Konfiguration von Umgebungsvariablen können Benutzer komplexen Aufgaben (Sonett) und Hilfsaufgaben (Haiku) unterschiedliche Modelle zuweisen, um Leistung und Kosten zu optimieren. Das Projekt basiert auf Python und LiteLLM, verwendet uv zur Verwaltung von Abhängigkeiten und ist für KI-Entwickler, Claude-Code-Nutzer und Open-Source-Enthusiasten leicht zu installieren. Die Dokumentation ist übersichtlich, die Community ist aktiv, und es sind detaillierte Anleitungen zur Konfiguration und Fehlersuche verfügbar.
Funktionsliste
- Unterstützung für die Verwendung jedes LiteLLM-kompatiblen Sprachmodells (z.B. OpenAI, Vertex AI, xAI) in Claude Code.
- Bietet unabhängige Routing-Konfigurationen für große (Sonett) und kleine (Haiku) Modelle zur Optimierung der Aufgabenzuweisung.
- Unterstützt benutzerdefinierte API-Schlüssel und Endpunkte und ist mit mehreren Modellanbietern kompatibel.
- Verwenden Sie LiteLLM, um API-Anfragen und -Antworten automatisch umzuwandeln, um sicherzustellen, dass sie mit dem System kompatibel sind. Anthropic API-Format kompatibel.
- Integrierte uv-Tools automatisieren die Verwaltung von Projektabhängigkeiten und vereinfachen den Bereitstellungsprozess.
- Detaillierte Protokollierungsfunktionen zur Aufzeichnung des Inhalts von Anfragen und Antworten zur einfachen Fehlersuche und schnellen technischen Analyse.
- Unterstützt lokale Modellserver und ermöglicht die Konfiguration von benutzerdefinierten API-Endpunkten.
- Open-Source-Projekt, bei dem Benutzer den Code ändern oder Funktionen beisteuern können.
Hilfe verwenden
Einbauverfahren
Die folgenden Installations- und Konfigurationsschritte sind für die Verwendung von Any LLM in Claude Code erforderlich und basieren auf der offiziellen Dokumentation, um Klarheit und Bedienbarkeit zu gewährleisten:
- Klonprojekt
Führen Sie den folgenden Befehl im Terminal aus, um das Projekt lokal zu klonen:git clone https://github.com/chachako/freecc.git cd freecc
2. **安装 uv 工具**
项目使用 uv 管理 Python 依赖。若未安装 uv,运行以下命令:
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
Die uv wird auf der Grundlage der pyproject.toml Installiert Abhängigkeiten automatisch, ohne dass Sie dies manuell tun müssen.
3. Umgebungsvariablen konfigurieren
Annahme des Projekts .env Datei, um das Modell-Routing und die API-Schlüssel zu konfigurieren. Kopieren Sie die Beispieldatei:
cp .env.example .env
Verwenden Sie einen Texteditor (z. B. nano), um die Datei .envkonfigurieren Sie die folgenden Variablen:
- Modell Routing-Konfiguration:
BIG_MODEL_PROVIDERGroße Modellanbieter (z. B.openai、vertex、xai)。BIG_MODEL_NAME: Großer Modellname (z.B.gpt-4.1、gemini-1.5-pro)。BIG_MODEL_API_KEYAPI-Schlüssel für das große Modell.BIG_MODEL_API_BASE(Optional) Benutzerdefinierte API-Endpunkte für große Modelle.SMALL_MODEL_PROVIDER: Anbieter von Miniaturen.SMALL_MODEL_NAME: Der Name der Miniatur (z.B.gpt-4o-mini)。SMALL_MODEL_API_KEY: API-Schlüssel für Miniaturen.SMALL_MODEL_API_BASE(Optional) Benutzerdefinierte API-Endpunkte für kleine Modelle.
- Globale Anbieterkonfiguration(zur Unterstützung oder als direkte Anfrage):
OPENAI_API_KEY、XAI_API_KEY、GEMINI_API_KEY、ANTHROPIC_API_KEY: API-Schlüssel für jeden Anbieter.OPENAI_API_BASE、XAI_API_BASEusw.: Benutzerdefinierte API-Endpunkte.
- Vertex AI-spezifische Konfigurationen:
VERTEX_PROJECT_IDGoogle Cloud Projekt-ID.VERTEX_LOCATIONVertex AI-Regionen (z. B.us-central1)。- Konfigurieren Sie die Google Apps-Standardanmeldeinformationen (ADC):
gcloud auth application-default loginoder eine Umgebungsvariable setzen
GOOGLE_APPLICATION_CREDENTIALSZeigen Sie auf die Datei mit den Anmeldeinformationen.
- Konfiguration protokollieren:
FILE_LOG_LEVELProtokolldateien (claude-proxy.log) Ebene (Standard)DEBUG)。CONSOLE_LOG_LEVELKonsolenprotokollebene (Standard)INFO)。LOG_REQUEST_BODY: Eingestellt auftrueZeichnen Sie den Inhalt der Anfrage auf, um die Analyse des Prompting-Projekts zu erleichtern.LOG_RESPONSE_BODY: Eingestellt auftrueHalten Sie den Inhalt der Modellantwort fest.
typisches Beispiel .env Konfiguration:
BIG_MODEL_PROVIDER="vertex"
BIG_MODEL_NAME="gemini-1.5-pro-preview-0514"
BIG_MODEL_API_KEY="your-vertex-key"
VERTEX_PROJECT_ID="your-gcp-project-id"
VERTEX_LOCATION="us-central1"
SMALL_MODEL_PROVIDER="openai"
SMALL_MODEL_NAME="gpt-4o-mini"
SMALL_MODEL_API_KEY="sk-xxx"
SMALL_MODEL_API_BASE="https://xyz.llm.com/v1"
FILE_LOG_LEVEL="DEBUG"
LOG_REQUEST_BODY="true"
- Operationsserver
Sobald die Konfiguration abgeschlossen ist, starten Sie den Proxyserver:uv run uvicorn server:app --host 127.0.0.1 --port 8082 --reloadParameter
--reloadOptional, zum automatischen Nachladen während der Entwicklung. - Verbindung Claude Code
Installieren Sie Claude Code (falls nicht bereits installiert):npm install -g @anthropic-ai/claude-codeSetzen von Umgebungsvariablen und Verbinden mit dem Agenten:
export ANTHROPIC_BASE_URL=http://localhost:8082 && claude
Funktion Betrieb
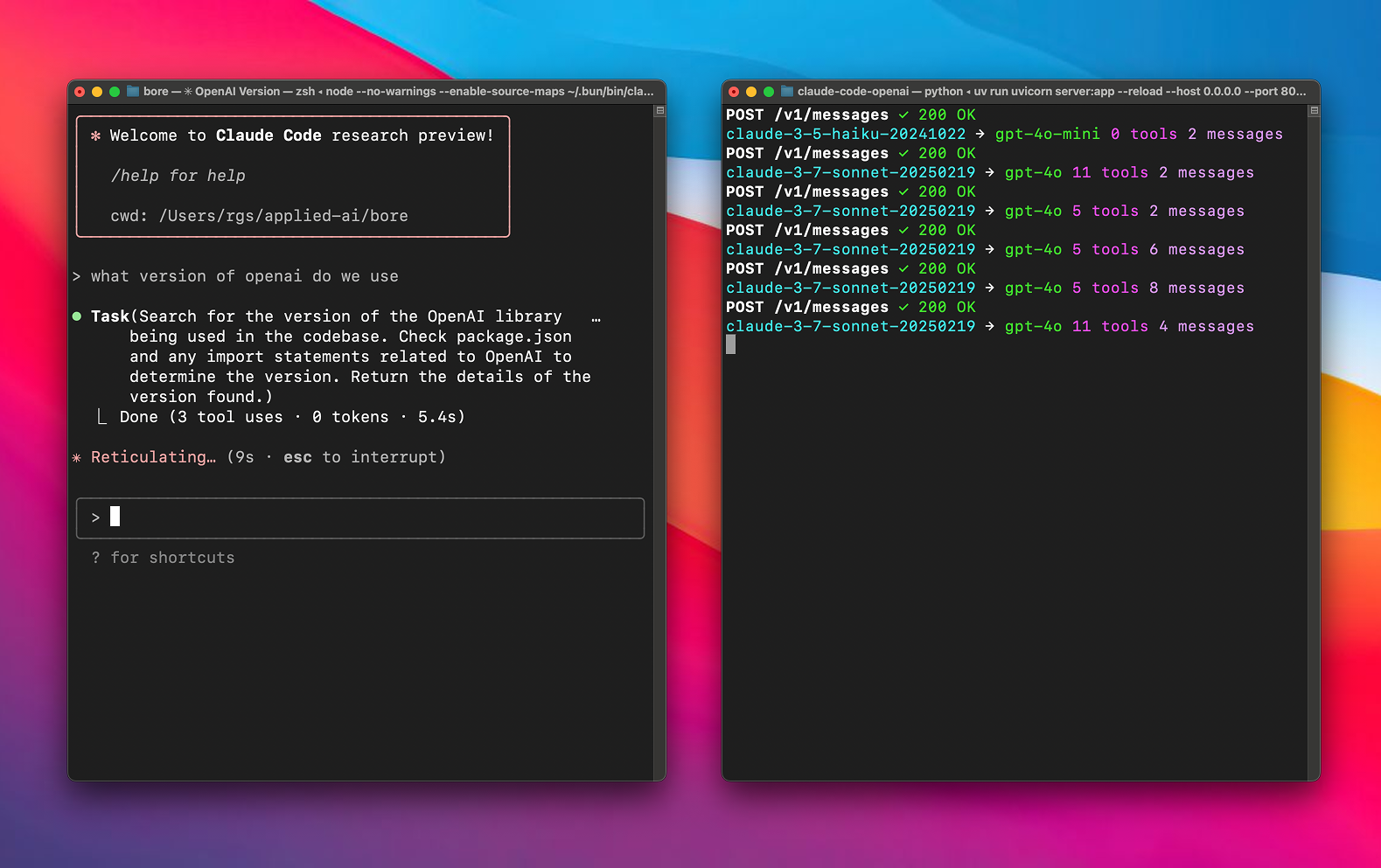
Der Kern von Any LLM in Claude Code ist die Weiterleitung von Claude-Code-Anfragen an benutzerkonfigurierte Modelle über einen Proxy. Im Folgenden wird detailliert beschrieben, wie dies funktioniert:
- Modell-Routing
Das Projekt unterstützt Claude Codessonnet(Hauptaufgaben wie komplexe Codegenerierung) undhaiku(Hilfsaufgaben wie die schnelle Grammatikprüfung) verschiedene Modelle konfigurieren. Zum Beispiel:- konfigurieren.
BIG_MODEL_PROVIDER="vertex"和BIG_MODEL_NAME="gemini-1.5-pro"wirdsonnetRouting zu Hochleistungsmodellen. - konfigurieren.
SMALL_MODEL_PROVIDER="openai"和SMALL_MODEL_NAME="gpt-4o-mini"wirdhaikuUm Kosten zu sparen, sollten Sie auf leichte Modelle umsteigen.
Die Benutzer können auf die.envFlexibler Wechsel von Modellen und Anbietern für Dokumente.
- konfigurieren.
- Konvertierung von API-Anfragen
Das Projekt implementiert die API-Formatkonvertierung durch LiteLLM mit dem folgenden Ablauf:- Claude Code sendet Anthropic-formatierte Anfragen (z. B. Aufrufe an die
claude-3-sonnet-20240229)。 - Der Agent handelt auf der Grundlage von
.envKonfiguration, die die Anfrage in das Zielmodellformat konvertiert (z. B. OpenAIsgpt-4.1)。 - Injizieren Sie den konfigurierten API-Schlüssel und Endpunkt, um die Anfrage zu senden.
- Konvertiert die Modellantwort zurück in das Anthropic-Format und gibt sie an Claude Code zurück.
Ein manuelles Eingreifen des Benutzers ist nicht erforderlich, der Konvertierungsprozess ist vollständig automatisiert.
- Claude Code sendet Anthropic-formatierte Anfragen (z. B. Aufrufe an die
- Protokollierung und Fehlersuche
Das Projekt bietet eine detaillierte Protokollierungsfunktion:- aufstellen
LOG_REQUEST_BODY="true"Der Inhalt der Anfrage von Claude Code wird aufgezeichnet, um die Analyse des Prompting-Projekts zu erleichtern. - aufstellen
LOG_RESPONSE_BODY="true"Zeichnen Sie die Antwort des Modells auf und überprüfen Sie, ob die Ausgabe korrekt ist. - Die Protokolle werden in der Datei
claude-proxy.logMit Hilfe desFILE_LOG_LEVEL和CONSOLE_LOG_LEVELKontrolle der Protokollebene.
Wenn Probleme auftreten, prüfen Sie die Protokolle oder überprüfen Sie.envDer Schlüssel und die Endpunkte in der
- aufstellen
- Lokale Modellunterstützung
Unterstützung für lokale Modellserver. Konfigurieren Sie zum Beispiel dieSMALL_MODEL_API_BASE="http://localhost:8000/v1"Sie kann in derhaikuWeiterleitung an lokale Modelle (z. B. LM Studio). Lokale Modelle erfordern keine API-Schlüssel und eignen sich für datenschutzsensible Szenarien.
caveat
- Stellen Sie sicher, dass die Netzwerkverbindung stabil ist und der API-Schlüssel gültig ist.
- Vertex AI-Benutzer müssen richtig konfiguriert sein
VERTEX_PROJECT_ID、VERTEX_LOCATIONund ADCs. - Besuchen Sie die GitHub-Projektseite (https://github.com/chachako/freecc) regelmäßig für Aktualisierungen oder Unterstützung durch die Gemeinschaft.
- Da die Protokolle sensible Informationen enthalten können, wird empfohlen, sie nach der Fehlersuche zu deaktivieren.
LOG_REQUEST_BODY和LOG_RESPONSE_BODY。
Anwendungsszenario
- Verbesserung der Flexibilität von Claude Code
Die Nutzer benötigen kein Claude Pro-Abonnement, um Hochleistungsmodelle wie die Gemini 1.5 Pro) oder kostengünstige Modelle (z. B. gpt-4o-mini), die das Kontextfenster erweitern oder die Kosten senken. - Leistungsvergleich der Modelle
Entwickler können über den Agenten schnell zwischen verschiedenen Modellen (z. B. OpenAI, Vertex AI) wechseln, die Leistung der verschiedenen Modelle in Claude Code testen und den Entwicklungsprozess optimieren. - Einsatz des lokalen Modells
Unternehmen oder Forscher können lokale Modellserver konfigurieren, um den Datenschutz zu gewährleisten, was sich für lokalisierte KI-Anwendungsszenarien eignet. - Engagement der Open-Source-Gemeinschaft
Da es sich um ein Open-Source-Projekt handelt, können Entwickler ihren Code über GitHub einreichen, um die Funktionalität zu optimieren oder Probleme zu beheben, die Anfängern das Erlernen von Python und KI-Entwicklung erleichtern.
QA
- Welche Modelle werden von Any LLM in Claude Code unterstützt?
Unterstützung für alle LiteLLM-kompatiblen Modelle, einschließlich OpenAI, Vertex AI, xAI, Anthropic usw., durch die.envKonfigurationsmodelle und Anbieter. - Wie gehe ich mit Konfigurationsfehlern um?
auscheckenclaude-proxy.logProtokolle, überprüfen Sie API-Schlüssel, Endpunkte und Modellnamen. Stellen Sie sicher, dass dieFILE_LOG_LEVEL="DEBUG"Detaillierte Protokolle erhalten. - Benötigen Sie ein Claude Pro-Abonnement?
Nicht erforderlich. Das Projekt unterstützt kostenlose Nutzer, um andere Modelle über einen Proxy zu verwenden und so die Abonnementbeschränkungen zu umgehen. - Kann es auf einem entfernten Server eingesetzt werden?
Dose. Wird--hosteingestellt auf0.0.0.0Stellen Sie sicher, dass der Anschluss (z. B.8082) Offen. - Wie kann ich Code beisteuern?
Besuchen Sie https://github.com/chachako/freecc, um einen Pull Request einzureichen. Es wird empfohlen, dass Sie zuerst die Richtlinien für Beiträge lesen.































