
CosyVoice ist ein quelloffenes, mehrsprachiges Spracherzeugungsmodell, das sich auf hochwertige Text-to-Speech-Technologie (TTS) konzentriert. Es unterstützt die Sprachsynthese in mehreren Sprachen und bietet Funktionen wie Zero-Sample-Sprachgenerierung, sprachübergreifendes Sprachklonen und feinkörnige Sentiment-Kontrolle.Cos- yVoice 2.0 vergleicht sich mit der Vorgängerversion und reduziert die 30% auf...

MiniMax Audio ist ein KI-Spracherzeugungstool von MiniMax, dessen Hauptfunktion die schnelle Umwandlung von Text in sehr ähnliche natürliche Sprache ist. Es basiert auf dem Modell Speech-02, mit einer Sprachsynthese Ähnlichkeit von bis zu 99%, Studio-Qualität, und Unterstützung für mehr als 30 Sprachen und eine breite Palette von Mund...
MegaTTS3 ist ein Open-Source-Sprachsynthese-Tool, das von ByteDance in Zusammenarbeit mit der Zhejiang University entwickelt wurde und sich auf die Erzeugung hochwertiger chinesischer und englischer Sprache konzentriert. Sein Kernmodell ist nur 0,45B Parameter, leicht und effizient, Unterstützung für gemischte chinesische und englische Sprache Generation und Sprache Klonen. Das Projekt wird auf GitHub gehostet und bietet Code und vortrainierte Modelle zum kostenlosen Download...

Seed-VC ist ein Open-Source-Projekt auf GitHub, entwickelt von Plachtaa. Es kann eine 1 bis 30 Sekunden Referenz-Audio, schnelle Sprache oder Song-Konvertierung, keine zusätzliche Ausbildung verwenden. Das Projekt unterstützt Echtzeit-Sprachkonvertierung, Latenz so niedrig wie 400 ms oder so, geeignet für Online-Meetings, Spiele oder live ...

CSM Voice Cloning ist ein Open-Source-Projekt, das von Isaiah Bjork entwickelt und auf GitHub gehostet wird. Es basiert auf dem Sesame CSM-1B-Modell, das es Benutzern ermöglicht, ihre eigene Stimme zu klonen und eine Stimme mit ihren eigenen persönlichen Eigenschaften zu erzeugen, indem sie einfach ein Audio-Sample bereitstellen. Dieses Tool unterstützt dies...

PlayHT ist eine effiziente Online-Plattform, die sich auf die Erzeugung von KI-Sprache konzentriert und Nutzern hilft, Text schnell in natürliche, realistische Sprache umzuwandeln. Es bietet mehr als 600 KI-Stimmen, unterstützt mehr als 60 Sprachen und verschiedene Akzente und ist für eine Vielzahl von Szenarien wie Podcast-Produktion, Bildungsinhalte, Marketing und Werbung geeignet. Benutzer müssen nur Text eingeben, den passenden Sprachstil auswählen,...
Spark-TTS ist ein Open-Source-Tool für Text-to-Speech (TTS), das vom SparkAudio-Team entwickelt wurde und auf GitHub gehostet wird. Es wurde entwickelt, um Benutzern zu helfen, Text effizient in natürliche und flüssige Sprache umzuwandeln. Es basiert auf fortschrittlicher Deep-Learning-Technologie und unterstützt mehrere Sprachen und Sprachstile...
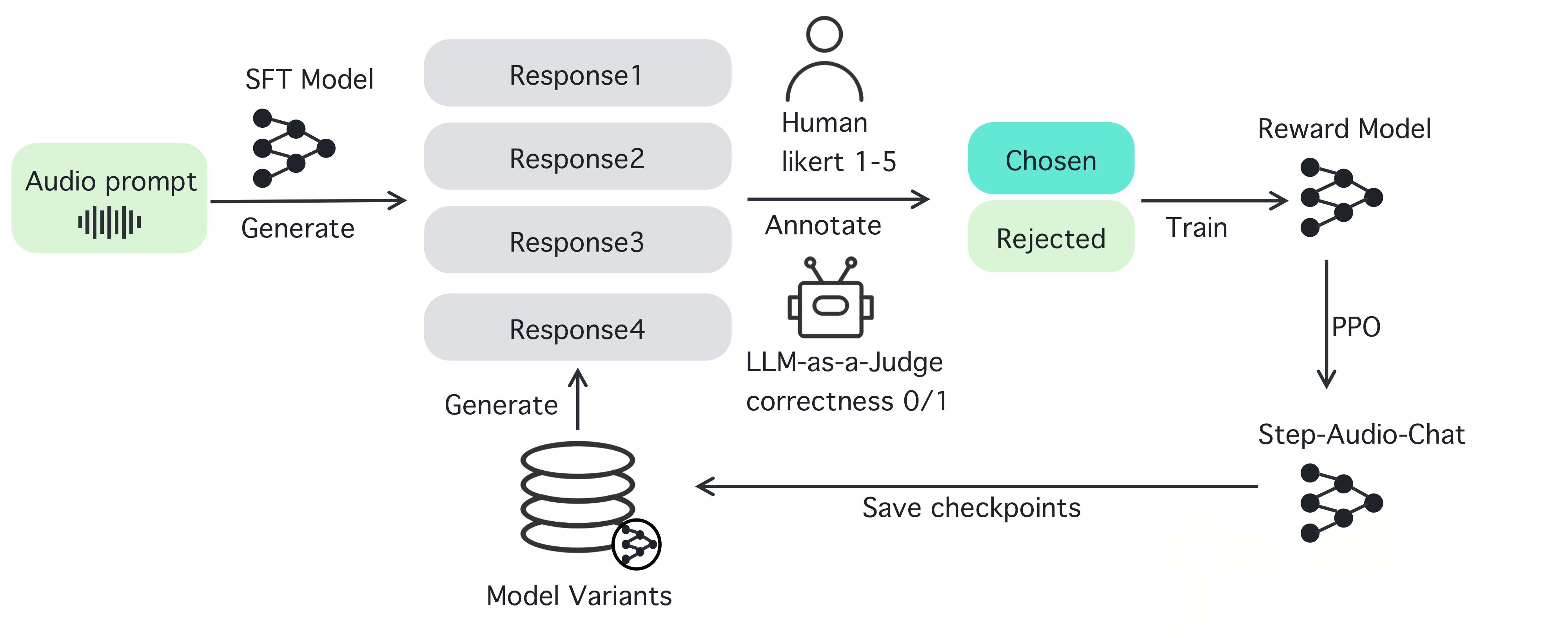
Step-Audio ist ein Open-Source-Framework für intelligente Sprachinteraktion, das entwickelt wurde, um sofort einsetzbare Sprachverstehens- und -erzeugungsfunktionen für Produktionsumgebungen bereitzustellen. Das Framework unterstützt mehrsprachige Dialoge (z.B. Chinesisch, Englisch, Japanisch), emotionale Sprache (z.B. fröhlich, traurig), regionale Dialekte (z.B. Kantonesisch, Sichuan), einstellbare Sprechgeschwindigkeit und rhythmischen Stil (z.B. Rap).Step-...

Zonos ist ein von Zyphra entwickeltes Open-Source-Sprachsynthese- und Sprachklonierungswerkzeug. Die Version Zonos-v0.1 verwendet ein fortschrittliches Transformator- und Überblendungsmodell, um qualitativ hochwertige Sprachausgabe zu erzeugen. Das Tool unterstützt mehrere Sprachen, darunter Englisch, Japanisch, Chinesisch, Französisch und Deutsch, und bietet detaillierte...

Weights ist eine soziale Plattform für Kreativität mit KI, die es Nutzern ermöglicht, mit einfachen Aktionen Sprachcover, Text-to-Speech, Bilder, Musik und Videos zu erstellen. Die Plattform bietet eine Fülle von Tools und Vorlagen, die den Nutzern helfen, schnell loszulegen und ihre Arbeit mit der Community zu teilen. weights unterstützt auch mehrere Geräte, einschließlich i...

AnyVoice ist eine hochmoderne KI-Spracherzeugungsplattform, die ultrarealistische Spracherzeugung und das Klonen von Stimmen anbietet. Die Plattform ermöglicht es Nutzern, Text in natürliche Sprache umzuwandeln und aus Hunderten von voreingestellten Stimmen zu wählen. Wenn Sie nicht die richtige Stimme finden, können Sie jede Stimme in nur 3 Sekunden Aufnahmezeit kostenlos klonen.AnyVoice ...

Llasa-3B ist ein Open-Source-Text-to-Speech-Modell (TTS), das vom Audio Lab der Hong Kong University of Science and Technology (HKUST Audio) entwickelt wurde. Das Modell basiert auf der Llama-3.2B-Architektur, die sorgfältig abgestimmt wurde, um eine qualitativ hochwertige Spracherzeugung zu ermöglichen, die nicht nur mehrere Sprachen unterstützt, sondern auch emotionalen Ausdruck und personalisiertes Sprachklonen ermöglicht.Llasa-3B...
Fish Speech Derivative Project Fish Agent ist ein revolutionäres End-to-End-KI-Sprachklon-System, das auf der Grundlage der 3B-Modellarchitektur V0.1 entwickelt wurde. Das wichtigste Merkmal dieses Systems ist, dass es ein innovatives semantisches tagloses Architekturdesign verwendet, das nicht auf traditionelle semantische Compiler wie Whisper angewiesen ist...

ViiTor AI ist eine leistungsstarke Plattform für künstliche Intelligenz, die hochwertige Videoübersetzung, Stimmenklonen, KI-generierte Avatar-Videos und Sprachsynthesedienste anbietet. Die Plattform unterstützt mehrere Sprachen und wurde entwickelt, um Nutzern die Erstellung mehrsprachiger Inhalte zu erleichtern.Die Videoübersetzungsfunktion von ViiTor AI generiert automatisch Untertitel und...
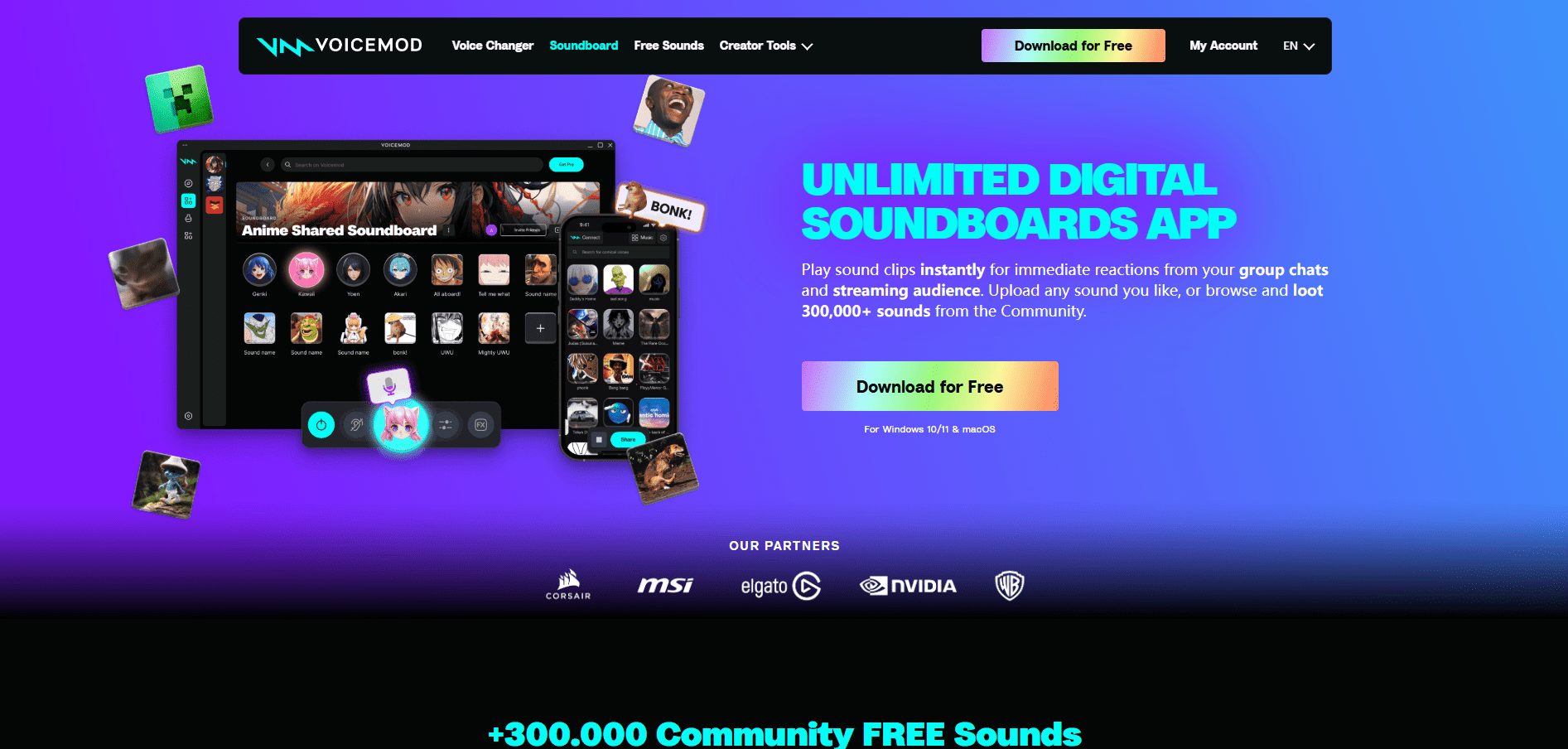
Voicemod ist ein führender Echtzeit-Stimmenveränderer und eine Software für Soundeffekte für Windows und macOS. Ob Sie ein Rollenspiel spielen, mit Freunden chatten oder live streamen, Voicemod bietet Ihnen eine Fülle von Stimmveränderungseffekten. Mit AI-Technologie ist Voicemod in der Lage, Ihre Echtzeit-Stimme zu ändern...
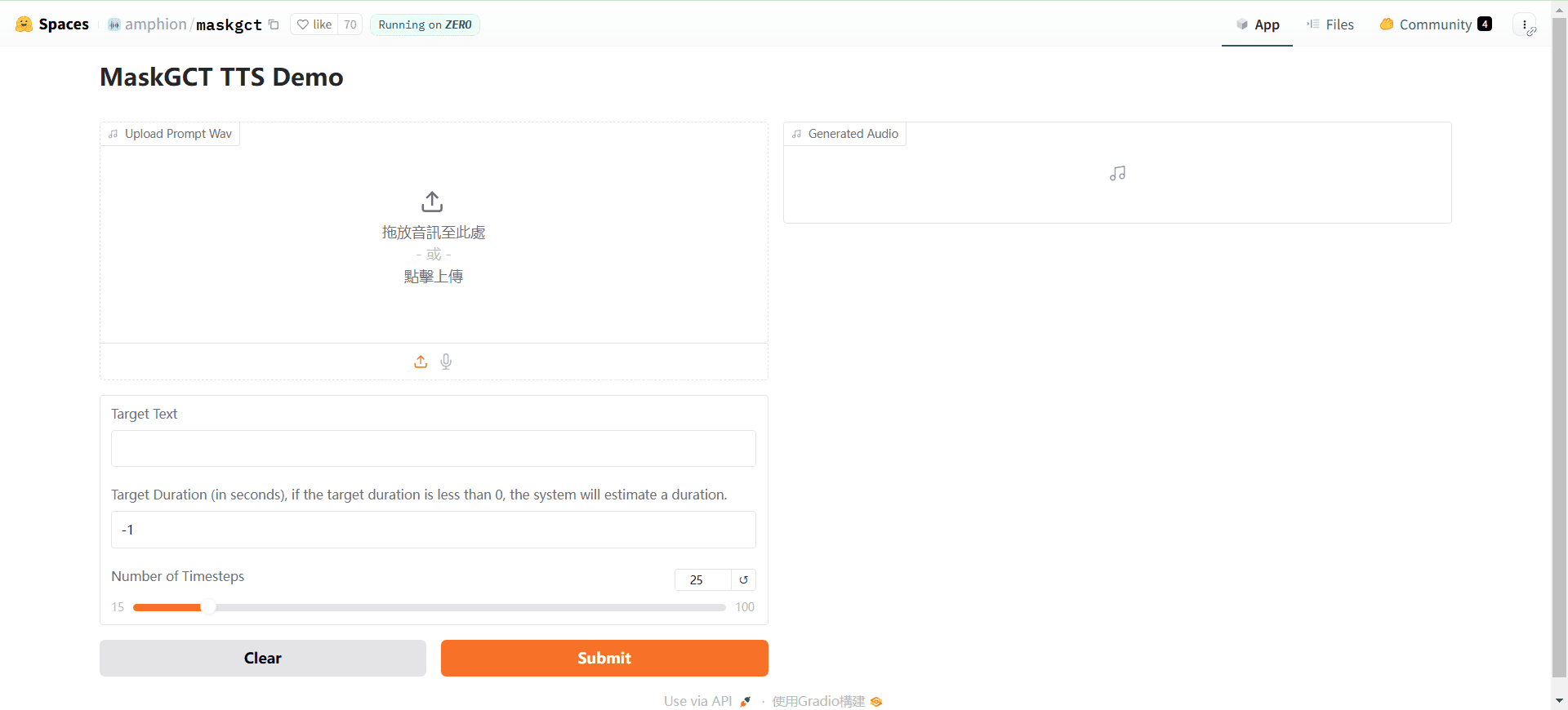
MaskGCT (Masked Generative Codec Transformer) ist ein vollständig nicht-autoregressives Text-to-Speech (TTS) Modell, das gemeinsam von Funky Maru Technology und der Chinese University of Hong Kong entwickelt wurde. Das Modell erfordert keine explizite Text-zu-Sprache-Ausrichtung Informationen und nimmt eine zweistufige Generation Ansatz, zunächst durch Text vor...

Funmaru Thousand Voices ist eine mehrsprachige KI-Stimmensyntheseplattform, die realistische und natürliche Stimmerzeugungslösungen bietet. Benutzer können Textinhalte einfach in professionelle Audiodateien umwandeln und die Erstellung exklusiver KI-Stimmen (Stimmklone) aus Null-Samples unterstützen, um individuelle Bedürfnisse zu erfüllen. Die Plattform bietet auch Videoübersetzungsfunktionen, die den Benutzern eine schnelle Konvertierung mehrsprachiger Inhalte ermöglichen. Merkmale...
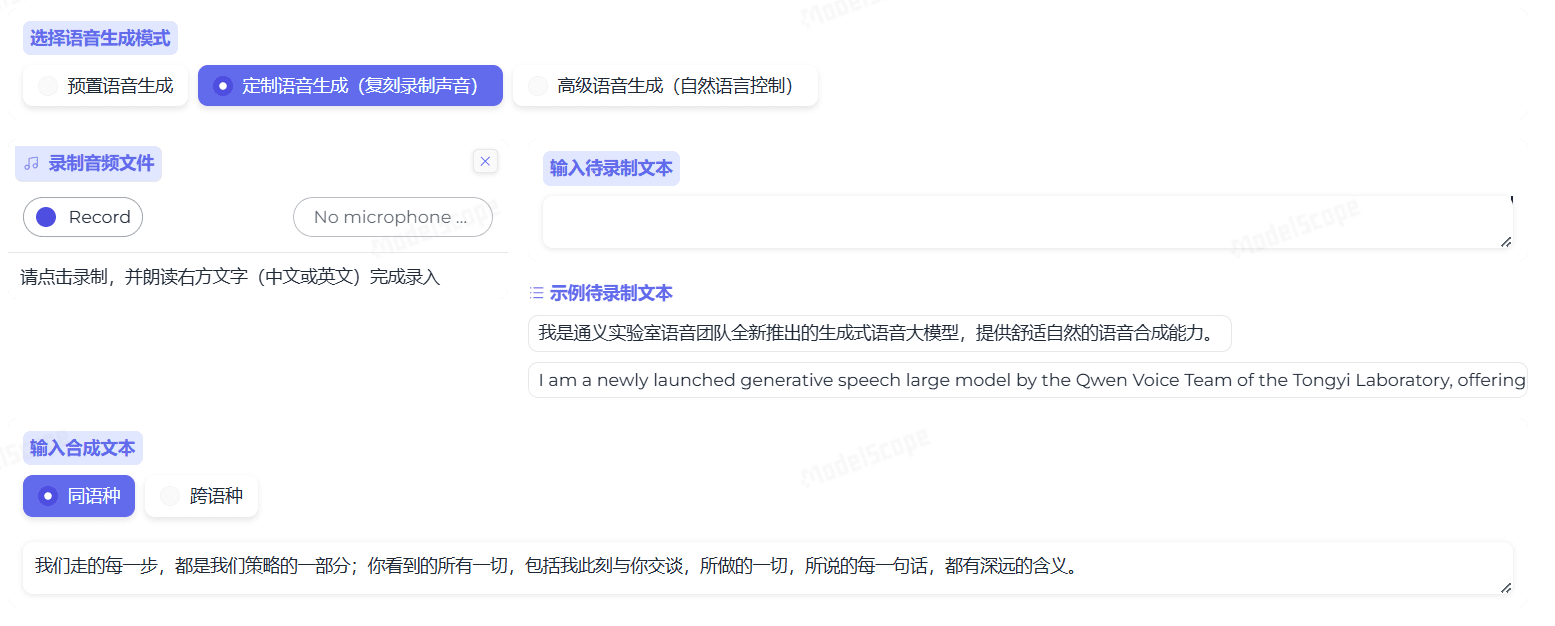
CosyVoice ist ein mehrsprachiges, groß angelegtes Spracherzeugungsmodell, das von der Inferenz über das Training bis hin zur Bereitstellung umfassende Funktionen bietet. Es wurde vom FunAudioLLM-Team entwickelt und zielt darauf ab, eine qualitativ hochwertige Sprachsynthese durch fortschrittliche autoregressive Transformatoren und ODE-basierte Diffusionsmodelle zu erreichen.CosyVoice unterstützt nicht nur die mehrsprachige Spracherzeugung, sondern auch...
Conch AI Video Generator ist ein von MiniMax entwickeltes, fortschrittliches Tool zur Erzeugung von KI-Videos. Benutzer müssen nur eine einfache Textbeschreibung eingeben oder Bilder hochladen, und Conch AI kann schnell hochwertige Videoinhalte erzeugen. Das Tool wird häufig von Kreativen, Vermarktern und Geschichtenerzählern genutzt, um ihre Ideen in anschauliche Videos zu verwandeln. Conch AI...
zurück zum Anfang

