Ausführliche Version: Wie wir zu diesem Punkt gekommen sind
Sie brauchen mir nicht zuzuhören.
Egal, ob Sie neu auf dem Gebiet der Intelligenzen sind oder ein mürrischer Veteran wie ich, ich werde versuchen, Sie davon zu überzeugen, die meisten Ihrer bisherigen Ansichten über KI-Intelligenzen über Bord zu werfen, einen Schritt zurückzutreten und sie von Grund auf neu zu überdenken. (Für den Fall, dass Sie die Veröffentlichung der API-Funktionen von OpenAI vor ein paar Wochen verpasst haben, hier der Spoiler: intelligentere Körperlogik hinter die API zu schieben ist nicht die richtige Richtung)
Intelligente Körper als Software und eine kurze Geschichte von ihnen
Lassen Sie uns darüber sprechen, wie wir hierher gekommen sind.
Vor 60 Jahren
Wir werden viel über gerichtete Graphen (DGs) und ihre azyklischen Freunde, gerichtete azyklische Graphen (DAGs), sprechen. Als erstes möchte ich darauf hinweisen, dass ...... gut ...... Software ein gerichteter Graph ist. Es gibt einen Grund, warum wir früher Flussdiagramme verwendet haben, um Programme darzustellen.

vor 20 Jahren
Vor etwa 20 Jahren begannen DAG-Orchestratoren populär zu werden. Wir sprechen hier von Dingen wie Airflow、Prefect Diese klassischen Werkzeuge sowie einige Vorläufer und einige neuere Werkzeuge wie (dagster、inggest、windmill). Sie folgen dem gleichen Graphenmuster mit den zusätzlichen Vorteilen der Beobachtbarkeit, Modularität, Wiederholung und Verwaltung.

vor 10-15 Jahren
Modelle des maschinellen Lernens wurden in DAGs eingefügt, als sie gut genug waren, um verwendet zu werden. Man könnte an Schritte denken wie "fasse den Text in dieser Spalte in einer neuen Spalte zusammen" oder "klassifiziere Support-Fragen nach Schweregrad oder Stimmung".

Letztendlich handelt es sich aber immer noch um die gleiche alte deterministische Software.
Zukunftsperspektiven für intelligente Körper
Ich bin nicht der Erste, aber das Wichtigste, was ich gelernt habe, als ich anfing, mich mit Intelligenzen zu beschäftigen, war, dass man die DAG weglassen kann. Software-Ingenieure müssen nicht mehr für jeden Schritt und jeden Randfall Code schreiben, man kann Intelligenzen ein Ziel und eine Reihe von Übergängen geben:

Dann lassen Sie das große Sprachmodell in Echtzeit Entscheidungen treffen, um den Weg zu finden.

Die Aussicht ist, dass Sie weniger Software schreiben und dem Graphen des großen Sprachmodells einfach "Kanten" geben und es selbständig "Knoten" finden lassen. Man kann sich von Fehlern erholen, man kann weniger Code schreiben, und man kann feststellen, dass das große Sprachmodell neue Lösungen für Probleme findet.
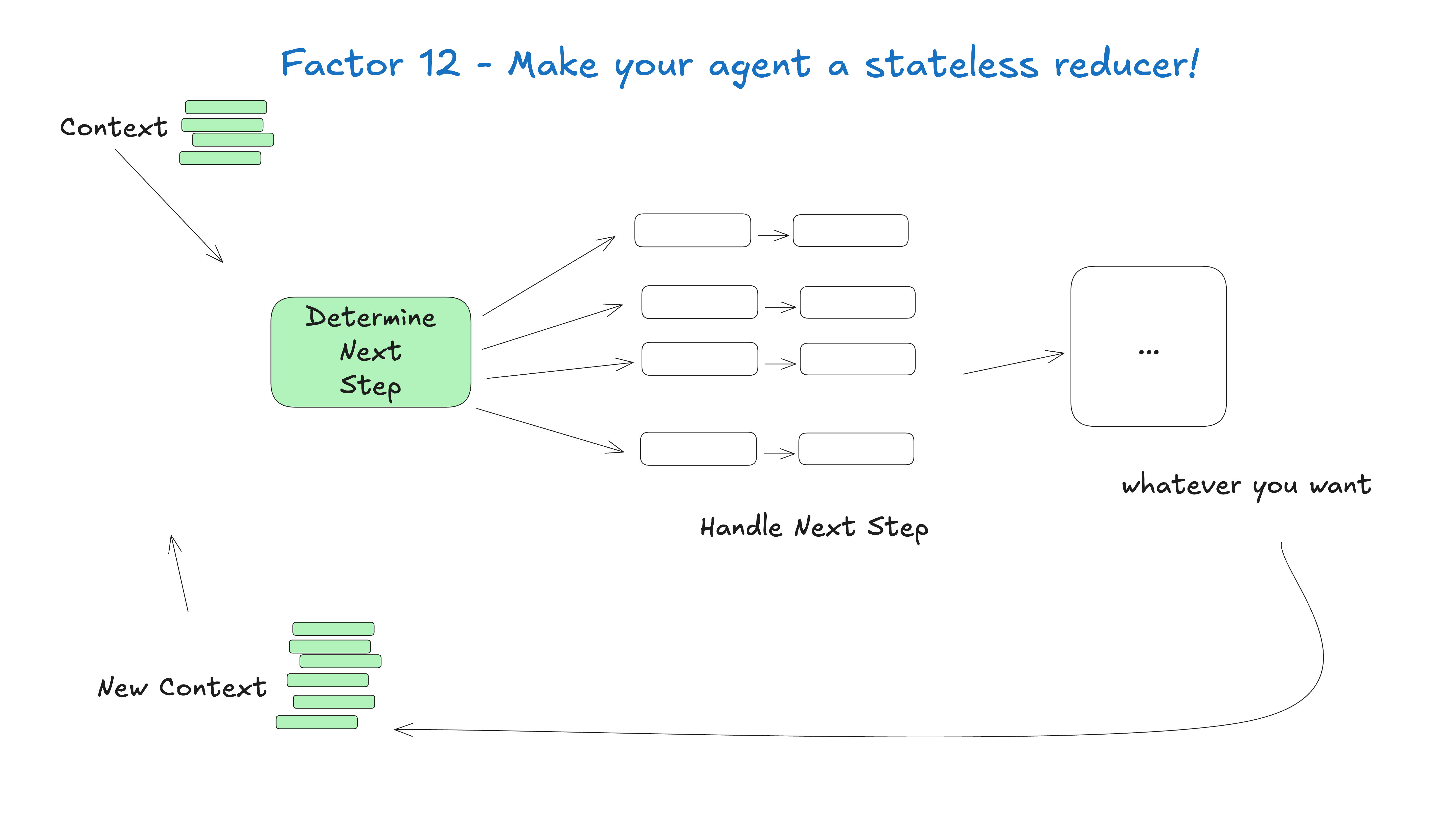
Intelligenz als Kreislauf
Mit anderen Worten: Sie haben einen Zyklus von 3 Schritten:
- Das Big Language Model bestimmt den nächsten Schritt im Arbeitsablauf und gibt strukturiertes JSON aus ("Tool Calls")
- Werkzeugaufrufe zur deterministischen Codeausführung
- Das Ergebnis wird an das Kontextfenster angehängt
- Wiederholen Sie diesen Vorgang, bis der nächste Schritt mit "Fertigstellen" gekennzeichnet ist.
initial_event = {"message": "..."}
context = [initial_event]
while True:
next_step = await llm.determine_next_step(context)
context.append(next_step)
if (next_step.intent === "done"):
return next_step.final_answer
result = await execute_step(next_step)
context.append(result)
Unser anfänglicher Kontext ist nur das Startereignis (vielleicht eine Benutzernachricht, ein Cron-Task-Trigger, ein Webhook usw.), und dann überlassen wir dem großen Sprachmodell die Wahl des nächsten Schritts (des Tools) oder die Feststellung, ob die Aufgabe abgeschlossen ist.
Dies ist ein mehrstufiges Beispiel:
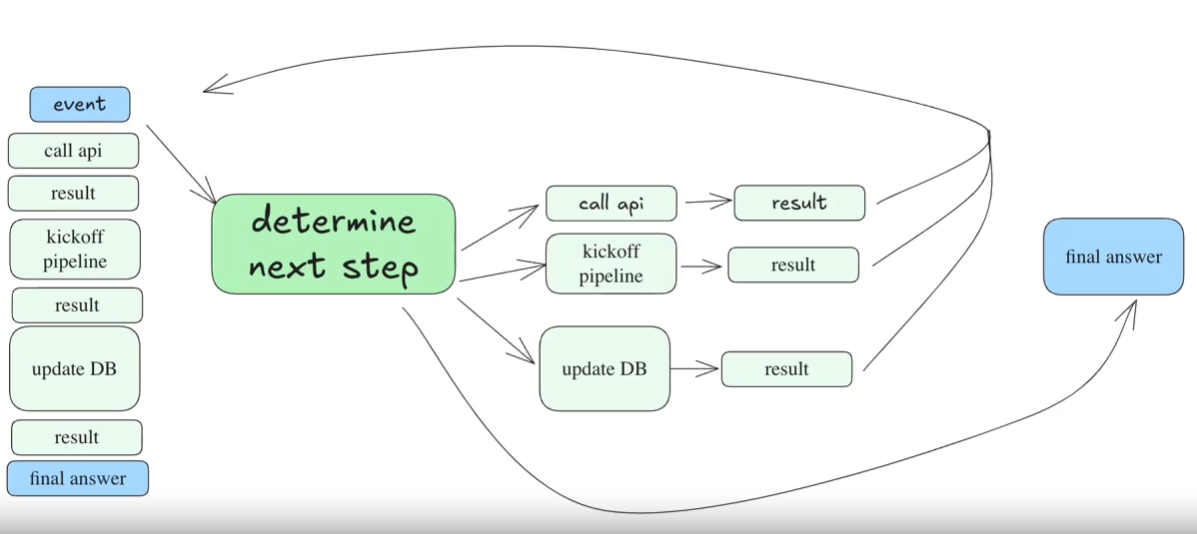
Die resultierende "materialisierte" DAG würde etwa so aussehen:

Probleme mit diesem "Rund-um-die-Uhr"-Modell
Das größte Problem bei diesem Modell ist:
- Wenn das Kontextfenster zu lang wird, gehen die Intelligenzen verloren - sie versuchen es immer wieder mit denselben fehlgeschlagenen Methoden.
- Es ist wirklich nur dieses eine Problem, aber es reicht aus, um diese Methode voranzutreiben.
Selbst wenn Sie Intelligenzen nicht manuell erstellt haben, kennen Sie wahrscheinlich das Problem mit dem langen Kontext, wenn Sie ein Tool zur Codierung intelligenter Körper verwenden. Sie gehen bei der Verwendung verloren und Sie müssen einen neuen Chat öffnen.
Ich möchte sogar einen Punkt ansprechen, den ich schon oft gehört habe und den Sie vielleicht auch schon intuitiv verstanden haben:
Auch wenn das Modell längere und längere Kontextfenster unterstützt, erzielen Sie mit kurzen, fokussierten Aufforderungen und Kontexten immer bessere Ergebnisse
Die meisten Entwickler, mit denen ich gesprochen habe, stellten fest, dass die Dinge nach mehr als 10-20 Dialogrunden unübersichtlich wurden und das große Sprachmodell sich davon nicht mehr erholen konnte.Die Idee der "Werkzeuganrufschleife" wird auf Eis gelegt.Selbst wenn die Zeit der intelligenten Stelle 90% richtig ist, ist das noch lange nicht "gut genug für den Kunden". Selbst wenn ein intelligenter Körper in 90% der Fälle richtig liegt, ist das noch lange nicht "gut genug für den Kunden". Können Sie sich vorstellen, dass eine Webanwendung mit 10% Seiten beim Laden abstürzt?
2025-06-09 Aktualisierung - Mir gefällt das sehr gut. @swyx dieser Aussage:

Was wirklich funktioniert - Mikro-Intelligenz
Ein Ansatz, den ich in der Praxis häufig sehe, ist die Übernahme und Einbindung des intelligenten Körpermodells in eine breitere, stärker deterministische DAG.

Sie fragen sich vielleicht: "Warum sollte man in diesem Fall Intelligenz einsetzen? -- Dazu kommen wir später, aber im Grunde genommen macht es ein Sprachmodell, das eine Reihe von gut eingegrenzten Aufgaben verwaltet, einfach, Echtzeit-Feedback von echten Menschen zu integrieren und es in Workflow-Schritte zu übersetzen, ohne in eine kontextbezogene Fehlerschleife zu geraten. (Element 1、Element 3、Elemente 7) 。
Sprachmodelle können explizit definierte Aufgabensätze verwalten, was die Integration von Echtzeit-Feedback von echten Menschen erleichtert ......, ohne sich in kontextbezogenen Fehlerschleifen zu verfangen.
Ein reales Beispiel für eine Mikro-Intelligenz
Dies ist ein Beispiel dafür, wie deterministischer Code eine Mikrointelligenz ausführen kann, die den "Man in the Loop"-Schritt des Bereitstellungsprozesses übernimmt.

- die Menschheit PR in den Hauptzweig von GitHub einbringen
- Deterministischer Code Bereitstellen in einer Staging-Umgebung
- Deterministischer Code Durchführung von End-to-End-Tests (e2e) in Umgebungen vor der Veröffentlichung
- Deterministischer Code Geben Sie der Intelligence die Aufgabe für die Bereitstellung in der Produktionsumgebung mit dem ursprünglichen Kontext "SHA 4af9ec0 in der Produktionsumgebung bereitstellen".
- intelligenter Körper Aufforderungen
deploy_frontend_to_prod(4af9ec0) - Deterministischer Code Antrag auf Genehmigung dieses Vorgangs durch Menschen
- die Menschheit Lehnen Sie den Vorgang mit der Rückmeldung ab: "Kann ich zuerst das Backend bereitstellen?"
- intelligenter Körper Aufforderungen
deploy_backend_to_prod(4af9ec0) - Deterministischer Code Antrag auf Genehmigung dieses Vorgangs durch Menschen
- die Menschheit Genehmigen Sie die Operation
- Deterministischer Code Back-End-Bereitstellung durchführen
- intelligenter Körper Aufforderungen
deploy_frontend_to_prod(4af9ec0) - Deterministischer Code Antrag auf Genehmigung dieses Vorgangs durch Menschen
- die Menschheit Genehmigen Sie die Operation
- Deterministischer Code Front-End-Bereitstellung durchführen
- intelligenter Körper Beurteilen Sie den erfolgreichen Abschluss der Aufgabe und beenden Sie sie!
- Deterministischer Code Durchführung von End-to-End-Tests in Produktionsumgebungen
- Deterministischer Code Abschluss der Aufgabe oder Übergabe der Aufgabe an die Rollback-Intelligenz, um den Fehler zu überprüfen und möglicherweise ein Rollback durchzuführen

Dieses Beispiel basiert auf einem Beispiel, das wir bei Humanlayer veröffentlicht haben, um unsere Einsätze zu verwalten. Echte Open-Source-Intelligenz -- Hier ist ein echter Dialog, den ich letzte Woche mit ihm geführt habe:

Wir haben diese Intelligenz nicht mit einer Vielzahl von Werkzeugen oder Aufgaben ausgestattet. Der Hauptwert des Big Language Model liegt in der Analyse von Klartext-Feedback von Menschen und dem Vorschlagen von aktualisierten Handlungsoptionen. Wir isolieren Aufgaben und Kontext so weit wie möglich, damit sich das Big Language Model auf einen kleinen Arbeitsablauf mit 5-10 Schritten konzentrieren kann.
Hier ist eine weitere. Eine eher klassische Support/Chatbot-Demo。
Was genau ist also ein intelligenter Körper?
- Prompt (Eingabeaufforderung) - Sagt dem großen Sprachmodell, wie es handeln soll und welche "Werkzeuge" ihm zur Verfügung stehen. Die Ausgabe des Hinweises ist ein JSON-Objekt, das den nächsten Schritt im Arbeitsablauf beschreibt ("Werkzeugaufruf" oder "Funktionsaufruf"). (Element 2)
- Switch-Anweisung - Entscheiden Sie auf der Grundlage des vom Big Language Model zurückgegebenen JSON, was damit geschehen soll. ( Teil von Element 8)
- Kumulativer Kontext - Speichert eine Liste der erfolgten Schritte und ihrer Ergebnisse. (Element 3)
- for-Schleife - Bevor das Big Language Model einen "terminate"-Aufruf (oder eine einfache Textantwort) ausgibt, fügen Sie das Ergebnis der switch-Anweisung in das Kontextfenster ein und bitten das Big Language Model zu entscheiden, was als Nächstes geschehen soll. (Element 8)

Im Beispiel "deploybot" haben wir durch die Beherrschung des Kontrollflusses und der Kontextakkumulation mehrere Vorteile erzielt:
- in unserem Switch-Anweisung 和 for-Schleife in denen wir den Kontrollfluss unterbrechen können, um auf menschliche Eingaben oder den Abschluss einer langlaufenden Aufgabe zu warten.
- Wir können leicht serialisieren (inhaltlicher) Kontext Fenster zum Anhalten und Fortsetzen.
- in unserem Prompt (Eingabeaufforderung) In diesem Fall können wir versuchen, die Art und Weise zu optimieren, in der Anweisungen und "was bisher geschah" an das große Sprachmodell geliefert werden.
Teil II 将 Formalisierung dieser MusterSie können in jedem Softwareprojekt verwendet werden, um beeindruckende KI-Funktionen hinzuzufügen, ohne die traditionelle Implementierung/Definition eines "KI-Intelligenzkörpers" in seiner Gesamtheit übernehmen zu müssen.