Going Small: Wie man ein 0,6B-Modell durch Modelldestillation wie ein 235B-Modell aussehen lässt
Große Sprachmodelle (Large Language Models, LLMs) sind hervorragend, aber ihre hohen Rechenkosten und langsame Inferenzgeschwindigkeit sind große Hindernisse für die praktische Anwendung. Eine wirksame Lösung ist die Modell-Destillation: Zunächst werden mit einem leistungsstarken Lehrermodell (Modell mit großen Parametern) qualitativ hochwertige annotierte Daten erzeugt, die dann zum "Lehren" eines kleineren, kostengünstigeren Schülermodells (Modell mit kleinen Parametern) verwendet werden. Die Daten werden dann verwendet, um ein kleineres, kostengünstigeres "Studentenmodell" (Modell mit kleinen Parametern) zu "lehren". Auf diese Weise kann das kleine Modell bei einer bestimmten Aufgabe eine Leistung erzielen, die der des großen Modells nahe kommt.
In diesem Beitrag werden wir das Beispiel der Extraktion von Logistikinformationen (Empfänger, Adresse, Telefonnummer) aus einem Text nehmen und im Detail demonstrieren, wie man eine parametrisierte 0.6B Qwen3-0.6B Modell verbessert sich die Genauigkeit bei der Informationsextraktion von 14% auf 98%, was mit den Ergebnissen des größeren Modells vergleichbar ist.
Der Vergleich der Ergebnisse vor und nach der Optimierung ist sehr anschaulich:

Kernprozesse des Programms
Der gesamte Prozess gliedert sich in drei wesentliche Schritte:
- Vorbereitung der DatenEin großes Modell von 235B wird als Lehrermodell verwendet, um einen Stapel virtueller Adressbeschreibungen zu verarbeiten und strukturierte JSON-Daten als hochwertigen Trainingssatz zu erzeugen. In der Praxis sollten reale Szenendaten verwendet werden, um die besten Ergebnisse zu erzielen.
- Feinabstimmung der Modelle: Anhand der im vorherigen Schritt generierten Daten wird die
Qwen3-0.6BDas Modell wird feinabgestimmt. Bei diesem Prozess werden diems-swiftFramework, das komplexe Feinabstimmungsoperationen auf einzeilige Befehle reduziert. - Überprüfung der EffektivitätBewertung der Modellleistung vor und nach der Feinabstimmung anhand eines unabhängigen Testsatzes, um Leistungsgewinne zu quantifizieren und die Stabilität und Genauigkeit des Modells in Produktionsumgebungen sicherzustellen.
I. Vorbereiten der Computerumgebung
Große Modelle für die Feinabstimmung müssen ausgestattet sein mit GPU Computerumgebung und die korrekte Installation der GPU Antrieb,CUDA 和 cuDNN. Das manuelle Konfigurieren dieser Abhängigkeiten ist nicht nur mühsam, sondern auch fehleranfällig. Um die Bereitstellung zu vereinfachen, empfiehlt es sich, die GPU Wenn Sie eine Cloud-Server-Instanz mit vorinstallierten GPU Fahrerbild, um die Feinabstimmung schnell zu starten.
Dieses Programm kann durch kostenlose Testressourcen ausprobiert werden. Ressourcen und Daten, die während des Testzeitraums erstellt wurden, werden am Ende des Testzeitraums gelöscht. Wenn Sie das Programm über einen längeren Zeitraum hinweg nutzen möchten, können Sie sich auf die Richtlinien für die manuelle Erstellung in der offiziellen Dokumentation beziehen.
- Erstellen Sie die Ressourcen gemäß der Seitenanleitung. Auf der rechten Seite wird der Fortschritt der Erstellung in Echtzeit angezeigt.
- Nach der Erstellung melden Sie sich über die Funktion Fernverbindung bei der
GPUCloud-Server.
Klicken Sie auf die Schaltfläche "Remote Connect" und melden Sie sich mit den angegebenen Anmeldedaten an.
II. das Herunterladen und die Feinabstimmung des Modells
Verfügbar über die Magic Match Community (ModelScope) ms-swift Rahmen, der den komplexen Prozess der Modellfeinabstimmung drastisch vereinfachen kann.
1. die Installation von Abhängigkeiten
Dieses Programm stützt sich auf zwei Kernkomponenten:
ms-swiftEin hochleistungsfähiger Trainingsrahmen, der von der Magic Hitch-Gemeinschaft zur Verfügung gestellt wird und das Herunterladen von Modellen, die Feinabstimmung und die Zusammenführung von Gewichten integriert.vllm:: Ein Rahmenwerk für den Einsatz von und die Schlussfolgerungen über Dienste, das hochleistungsfähige Schlussfolgerungen unterstützt, die Validierung von Modelleffekten erleichtert undAPIFür geschäftliche Anrufe.
Führen Sie den folgenden Befehl im Terminal aus, um die Abhängigkeiten zu installieren (dauert etwa 5 Minuten):
pip3 install vllm==0.9.0.1 ms-swift==3.5.0
2. die Feinabstimmung des Umsetzungsmodells
Führen Sie das folgende Skript aus, um den gesamten Prozess des Modelldownloads, der Datenaufbereitung, der Feinabstimmung des Modells und der Zusammenführung der Gewichte zu automatisieren.
# 进入 /root 目录
cd /root && \
# 下载微调脚本 sft.sh
curl -f -o sft.sh "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250623/cggwpz/sft.sh" && \
# 执行微调脚本
bash sft.sh
Der Feinabstimmungsprozess dauert etwa 10 Minuten.sft.sh Die wichtigsten Befehle des Skripts lauten wie folgt:
swift sft \
--model Qwen/Qwen3-0.6B \
--train_type lora \
--dataset 'train.jsonl' \
--torch_dtype bfloat16 \
--num_train_epochs 10 \
--per_device_train_batch_size 20 \
--per_device_eval_batch_size 20 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--save_steps 1 \
--save_total_limit 2 \
--logging_steps 2 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Einige der wichtigsten Parameter werden hier beschrieben:
--train_type loraLoRA: Spezifizieren Sie die Verwendung der LoRA-Methode (Low-Rank Adaptation) für die Feinabstimmung. Dabei handelt es sich um eine parametereffiziente Feinabstimmungsmethode, bei der im Vergleich zur vollständigen Feinabstimmung nur eine geringe Anzahl zusätzlicher Gewichte trainiert wird, was die Anforderungen an die Rechenressourcen erheblich reduziert.--lora_rank:: Der Rang der LoRA-Matrix. Je größer der Rang, desto besser passt das Modell zu komplexen Aufgaben, aber ein zu großer Wert kann zu einer Überanpassung führen.--lora_alpha: der Skalierungsfaktor von LoRA, mitlearning_rateÄhnlich verhält es sich mit der Anpassung des Umfangs der Gewichtsaktualisierungen.--num_train_epochs: Trainingsrunden. Bestimmt, wie tief das Modell die Daten erlernt.
Während des Trainingsprozesses gibt das Terminal die Veränderung des Verlusts des Modells auf den Trainings- und Validierungssätzen in Echtzeit aus.

Wenn die folgende Ausgabe zu sehen ist, bedeutet dies, dass die Feinabstimmung des Modells und die Zusammenführung der Gewichte erfolgreich abgeschlossen wurden:
✓ swift export 命令执行成功
检查合并结果...
✓ 合并目录创建成功: output/v0-xxx-xxx/checkpoint-50-merged
✓ LoRA权重合并完成!
合并后的模型路径: output/v0-xxx-xxx/checkpoint-50-merged
Sobald die Feinabstimmung abgeschlossen ist, wird die output/v0-xxx-xxx/images Verzeichnis zu finden, um die train_loss.png 和 eval_loss.png Zwei Diagramme, die den Trainingszustand des Modells veranschaulichen.
| train_loss (Verlust des Trainingssatzes) | eval_loss (Verlust des Validierungssatzes) |
|---|---|
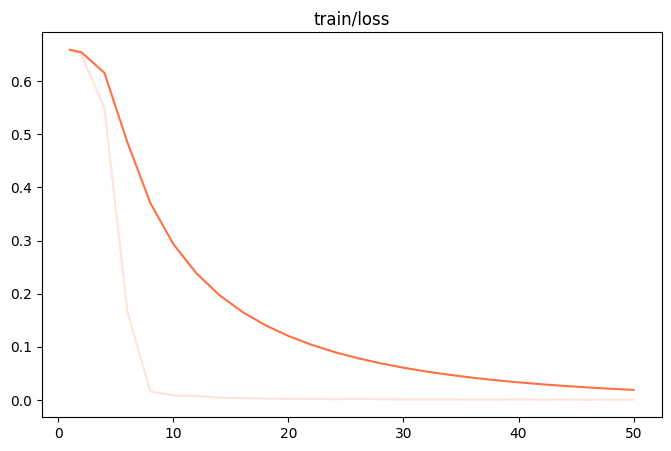 |
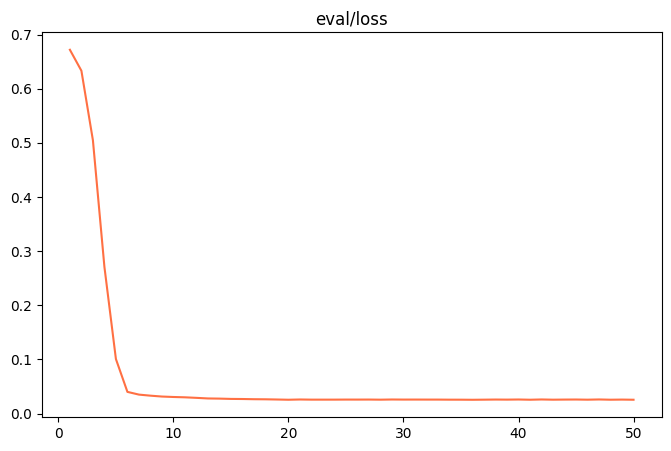 |
- schlechte PassformWenn
train_loss和eval_lossWenn am Ende der Ausbildung immer noch ein deutlicher Abwärtstrend zu verzeichnen ist, versuchen Sie, dienum_train_epochs或lora_rank。 - ÜberanpassungWenn
train_lossFortgesetzter Rückgang, abereval_lossStattdessen beginnt sie zu steigen, was darauf hinweist, dass das Modell die Trainingsdaten überlernt hat und reduziert werden sollte.num_train_epochs或lora_rank。 - gute PassformWenn sich beide Kurven abflachen, bedeutet dies, dass das Modelltraining einen idealen Zustand erreicht hat.
III. die Validierung der Modelleffekte
Eine systematische Überprüfung ist ein wesentlicher Bestandteil des Prozesses vor dem Einsatz in einer Produktionsumgebung.
1. die Vorbereitung der Testdaten
Die Testdaten sollten das gleiche Format wie die Trainingsdaten haben und müssen völlig neu und für das Modell unbekannt sein, um seine Generalisierungsfähigkeit zu beurteilen.
cd /root && \
# 下载测试数据 test.jsonl
curl -o test.jsonl "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250610/mhxmdw/test_with_system.jsonl"
Nachstehend finden Sie ein Beispiel für die Testdaten:
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "电话:23204753945:大理市大理市人民路25号 大理古城国际酒店 3号楼:收件者:段丽娟"}, {"role": "assistant", "content": "{\"province\": \"云南省\", \"city\": \"大理市\", ...}"}]}
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "天津市河西区珠江道21号金泰大厦3层 , 接收人慕容修远 , MOBILE:22323185576"}, {"role": "assistant", "content": "{\"province\": \"天津市\", \"city\": \"天津市\", ...}"}]}
2. die Gestaltung der Bewertungsindikatoren
Die Bewertungskriterien müssen sich eng an den Unternehmenszielen orientieren. In diesem Beispiel ist es nicht nur wichtig, festzustellen, ob der Output ein legitimer JSONIch werde sie einzeln vergleichen müssen. JSON Jedes Schlüssel-Werte-Paar in der
3. die Bewertung der Wirksamkeit des ursprünglichen Modells
Erstens, in der nicht fein abgestimmten Qwen3-0.6B Modell getestet wurde. Selbst mit einer gut konzipierten und detaillierten Aufforderung ist die Genauigkeit bei den 400 getesteten Proben nur 14%。
所有预测完成! 结果已保存到 predicted_labels_without_sft.jsonl
样本数: 400 条
响应正确: 56 条
响应错误: 344 条
评估脚本运行完成
4. die Validierung von fein abgestimmten Modellen
Anschließend wurde das feinabgestimmte Modell mit demselben Testsatz bewertet. Eine wesentliche Änderung besteht darin, dass es nun möglich ist, mit einem sehr knappen Stichwort eine hervorragende Leistung zu erzielen, da aufgabenspezifisches Wissen in die Modellparameter "eingebacken" ist und keine komplexen Anweisungen mehr benötigt werden.
Die Kurzfassung des Stichworts:
你是一个专业的信息抽取助手,专门负责从中文文本中提取收件人的JSON信息,包含的Key有province(省份)、city(城市名称)、district(区县名称)、specific_location(街道、门牌号、小区、楼栋等详细信息)、name(收件人姓名)、phone(联系电话)
Nach der Ausführung des Bewertungsskripts zeigen die Ergebnisse, dass die Genauigkeit des fein abgestimmten Modells die 98%wurde ein Qualitätssprung gemacht.
所有预测完成! 结果已保存到 predicted_labels.jsonl
样本数: 400 条
响应正确: 392 条
响应错误: 8 条
评估脚本运行完成
Dieses Ergebnis beweist, dass die Modelldestillation und LoRA Die Feinabstimmung ist eine äußerst kosteneffiziente Lösung, die es ermöglicht, kleine Modelle auf bestimmte Bereiche anzuwenden und die Kosten- und Effizienzhürden für die Skalierung der KI-Technologie zu überwinden.