



ウェブクローラーは、コマンドラインインターフェイス(CLI)として動作し、インターネット上の情報を検索するための簡潔でリアルタイムなチャネルをユーザーに提供するオープンソースのウェブクローラーツールです。このツールは、ユーザーによって入力されたクエリーキーワードに基づいてウェブを検索し、その結果をJSON形式(タイトル、URL、リリース日を含む)で、リリース時間の近いものから遠いものへと順にターミナルに直接出力するように特別に設計されている。このプロジェクトは "financial-datasets "という組織の一部であり、大規模言語モデル(LLM)や人工知能エージェント(AIエージェント)のために、使いやすい金融データのAPIやツールを提供することに専念している。このウェブ・クローラーは、そのツール群の一員として、インターネットから最新の情報を迅速かつ効率的にクロールし、その後のデータ分析やAIアプリケーションのための生データ入力を提供するように設計されている。
機能一覧
- リアルタイムのウェブ検索ユーザがコマンドラインインターフェイスから入力したクエリータームを受信し、即座に検索を実行する。
- JSON形式の出力検索結果は、構造化されたJSONフォーマットで返されます。
title(タイトル)、url(ウェブサイト)とpublished_date(発売日)の3つのフィールド。 - 適時性でソート検索結果は公開日順にソートされ、最新の情報が表示されます。
- インタラクティブ・クエリこのツールは連続検索をサポートしています。検索終了後、プログラムを再起動することなく、すぐに次の検索のために新しいキーワードを入力することができます。
- クロスプラットフォームの互換性Python 3.12以上をサポートする環境であれば、どのような環境でも動作します。
- シンプルな出口メカニズムをタイプして名前を入力することができます。
q、quit、exitまたはショートカットキーCtrl+Cをクリックすると、簡単にプログラムを終了できます。
ヘルプの使用
このツールは軽量なコマンドライン・プログラムで、複雑なインストールや設定を必要とせず、すぐに使い始めることができる。以下は、インストールと使用方法の詳細です。
環境準備
作業を始める前に、以下の2つの重要なソフトウェアがコンピュータにインストールされていることを確認してください:
- Pythonバージョン要件は
3.12あるいはそれ以上だ。 - uv高速な Python パッケージのインストールと管理ツール。
インストール手順
- クローン・コード・リポジトリ
ターミナル(コマンドラインツール)を開いてgitコマンドは、プロジェクトのソースコードをGitHubからあなたのローカルコンピューターにクローンします。git clone https://github.com/financial-datasets/web-crawler.git - プロジェクト・ディレクトリに移動する
クローニングが完了したらcdコマンドを、先ほど作成したプロジェクト・フォルダーに追加する。cd web-crawler
ランニングプログラム
プロジェクトのルート・ディレクトリ(web-crawlerフォルダ)にある以下のコマンドを直接実行することで、このウェブ・クローラー・ツールを起動することができる:
uv run web-crawler
uv run コマンドは、プロジェクトが必要とする依存関係のインストールと仮想環境の設定を自動的に処理し、続いてメイン・アプリケーションを起動する。
ワークフロー
- クエリーを入力する
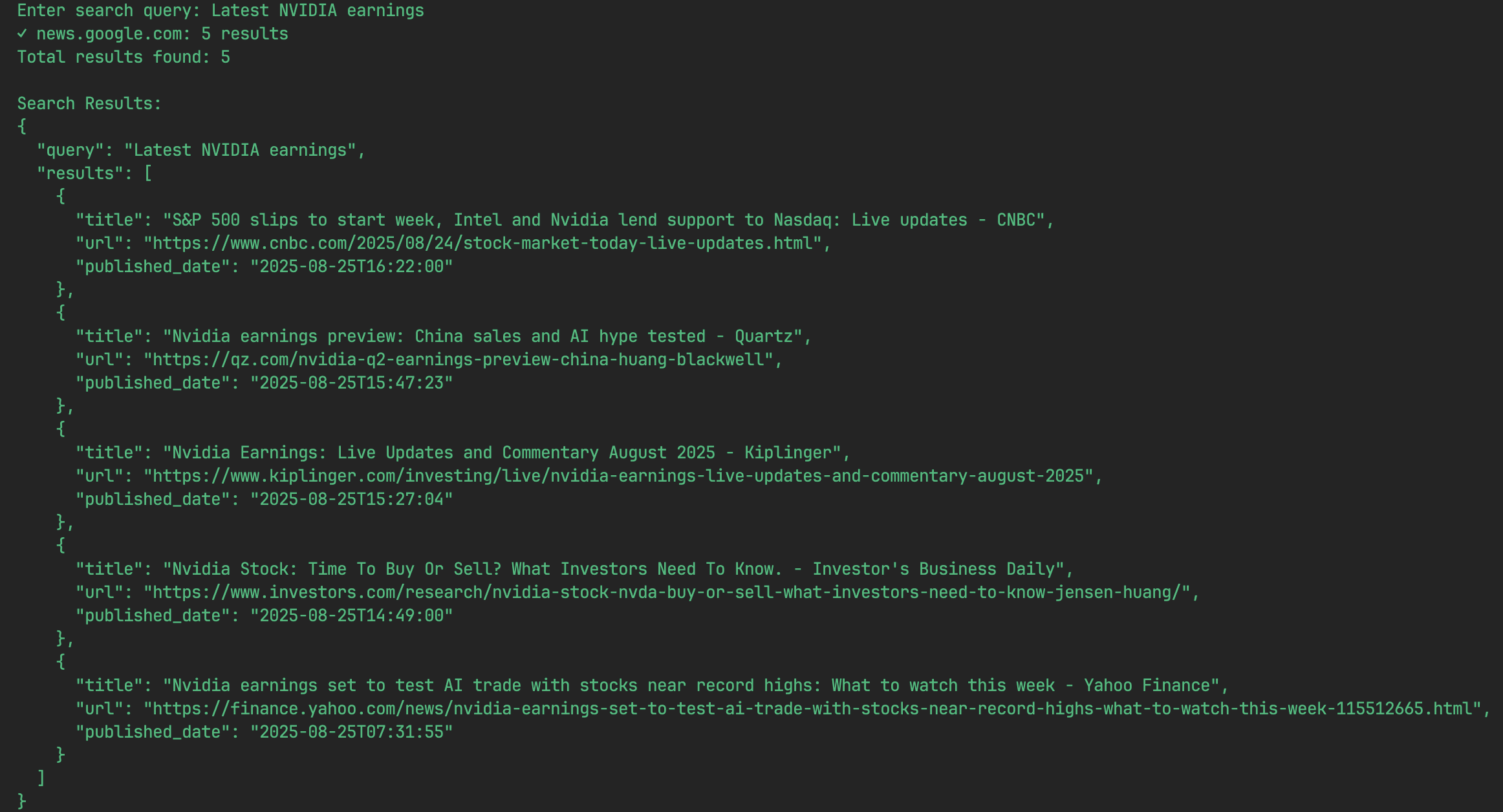
プログラムが始まると、端末が検索したい内容を入力するよう促す。例えば、アップルの最新の決算説明会の議事録を調べたい場合など、興味のあるキーワードを入力することができる:Enter your search (e.g., "AAPL latest earnings transcript"):ここにクエリを入力してエンターキーを押してください。
- 結果を見る
プログラムはすぐに検索を開始し、数秒以内に結果をJSONオブジェクトのリストとして画面に表示する。各JSONオブジェクトは、タイトル、URL、公開日を含む検索結果を表します。たとえば、検索結果は次のようになる:
[ { "title": "Apple Inc. (AAPL) Q3 2025 Earnings Call Transcript", "url": "https://example.com/aapl-q3-2025-transcript", "published_date": "2025-07-30" }, { "title": "Analysis of Apple's Latest Financial Report", "url": "https://example-news.com/aapl-q3-analysis", "published_date": "2025-07-29" } ] - 続行または撤退
- 検索を続けるクエリが終了すると、プログラムは再び入力プロンプトを表示し、次の検索のために新しいキーワードを直接入力することができます。
- オプトアウト手順使用を終了したい場合は、入力プロンプトの後に次のように入力します。
q、quit或exitと入力してエンターキーを押す。または、キーボードショートカットのCtrl+Cで強制的に割り込みをかけ、プログラムを終了する。
アプリケーションシナリオ
- 金融アナリストおよび研究者
アナリストはこのツールを使って、特定の企業の最新決算報告書、プレスリリース、市場分析、経営陣インタビューなどを素早く取得することができます。例えば、企業コードと「決算短信」を入力すると、最新の決算説明会のテキストへのリンクが素早く表示され、財務モデルや投資判断をサポートするタイムリーなデータを得ることができます。 - AIエージェントと大規模言語モデルのためのデータ入力
このツールは、AIエージェントにリアルタイムのデータフィードを提供する自動化ワークフローの一部として使用することができる。 例えば、市場サマリーを作成するために使用されるAIエージェントは、特定の業界や企業に関する最新ニュースへのリンクのためにこのクローラーを呼び出し、要約してレポートを作成するためにそれらのリンクにアクセスすることができる。 - ソフトウェア開発者&データサイエンティスト
開発者は、このクローラーをアプリケーションに組み込んで、特定のトピックに関するウェブ情報を監視することができる。例えば、世論監視システムを構築し、製品に関連するキーワードを定期的にクエリーすることで、最新のユーザー・フィードバックやメディア・レポートを収集することができる。 - ジャーナリストとジャーナリスト
ジャーナリストはこのツールを使って、ニュース速報の最新動向を追跡することができる。イベントのキーワードを入力することで、さまざまなニュースソースからのレポートへのリンクを素早く取得し、タイムラインに整理することができる。
QA
- このツールはウェブ全体を検索するのですか?
このツールは現在、情報検索にDuckDuckGoの検索APIを利用しており、理論的には幅広いインターネット・コンテンツをカバーできる。しかし、今後の開発ロードマップでは、BingやRedditなど、より多くのデータソースを追加し、検索の幅と多様性をさらに拡大する予定だ。 - 検索結果がJSON形式なのはなぜですか?
JSONは軽量で読み書きが容易なデータ交換フォーマットであり、機械が解析・生成するのも容易である。開発者にとって、このフォーマットは非常に使いやすく、このツールの出力を他のプログラムの入力として使用することも簡単で、自動化された処理プロセスが容易になる。 - このプロジェクトは、ログインが必要なウェブサイトや複雑なJavaScriptの読み込みがあるウェブサイトをクロールするために使用できますか?
現在のバージョンでは、コンテンツを動的に読み込むために多くのJavaScriptを必要とするサイト(主要な金融ニュースサイトの一部など)を処理する能力に限界がある。今後のリリースでは、このような「JavaScriptを多用する」ページのコンテンツ解析を改善する予定です。 - 私は開発者ですが、このプロジェクトに貢献できますか?
もちろんです。これはオープンソースのプロジェクトであり、コミュニティの助けや貢献は大歓迎だ。公式のロードマップでは、JavaScriptのページ解析の改善、コンテンツ要約のための大規模言語モデルの統合、新しいデータソースの追加、クエリの並列化によるスピードの向上など、手助けが必要な多くの方向性について言及しているが、これらに限定されるものではない。































