

を受けて wan2.1 ローカライズド・ビデオ生成のようなビデオモデルの出現により、ローカライズド・ビデオ生成のための技術エコシステムは徐々に成熟しつつある。以前は、高性能ハードウェアがビデオワークフロー構築の主な障害だったが、クラウドコンピューティングリソースの普及とモデル最適化技術の発展により、最高級ビデオカードを持たないユーザーでもクラウドをレンタルできるようになった。 4090 グラフィックス・カードや、深く学び探求するためのその他の方法 wan2.1 ビデオワークフロー。
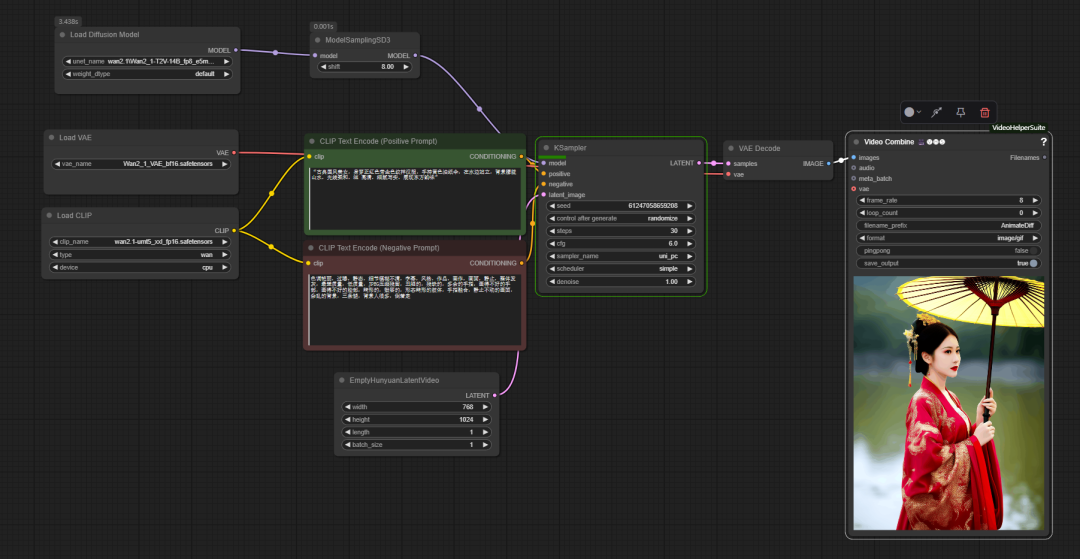
在 ComfyUI の公式ベースワークフローにある。wan2.1 は、従来のヴァンセンヌ・ダイアグラムのプロセスと同様に使用されるが、キー・ノードが追加される。 model sampling sd3.このノードは UNet このパラメータは、キューワードを理解し制御するモデルの能力に影響するため、生成される画像の細部が最適化される。
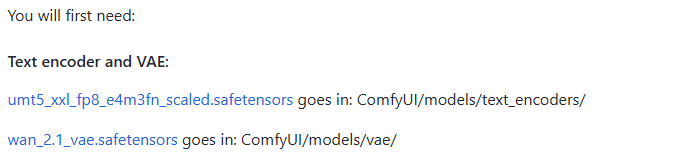
実行する wan2.1 このモデルは、対応する unmt5 テキスト・エンコーダと wan2.1 VAE(Variable Auto-Encoder): VAEは、エンコーダーとデコーダーの2つの部分から構成される。エンコーダーは入力画像を低次元のポテンシャル空間に圧縮する役割を担い、デコーダーはポテンシャル空間からサンプリングして画像に還元する。
テキストエンコーダの役割は、入力テキストの手がかりを、モデルが理解できる特徴ベクトルに変換することである。このプロセスは主に2つのステップからなる:
- テキストの意味情報の特徴を抽出する。
- 意味情報は高次元の埋め込みベクトルに変換される。
これらの埋め込みベクトルに基づいて、生成モデル(UNetなど)はテキスト記述と一致する潜在空間内の画像特徴を生成し、フレーム内のオブジェクトの種類、位置、色、姿勢を決定する。
静的なベン図ワークフローとは異なり、ビデオ生成プロセスの最終ステップは Video Combine (ビデオ合成)ノード。
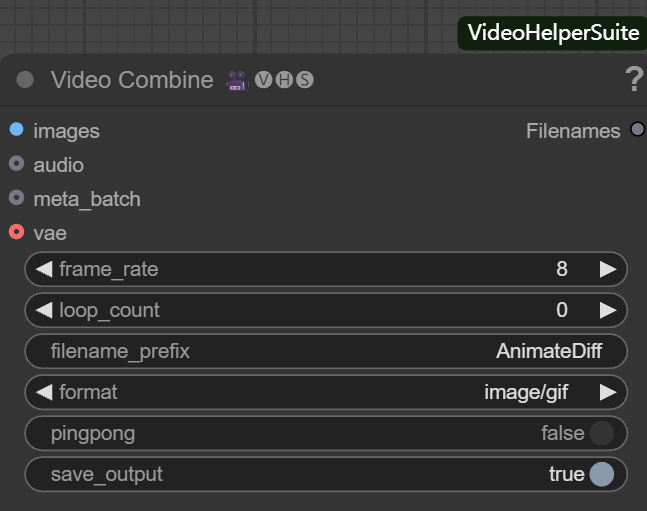
このノードは画像シーケンスをビデオまたは動画ファイルに整流する。主なパラメータは以下の通り:
- フレームレート。 ビデオ再生の滑らかさを決定する。
8つまり、1秒間に8フレームが再生される。 - loop_count.
0無限ループを表し、GIFに適用できる;1つまり、一度プレーして、それから止めるということだ。 - filename_prefix (ファイル名のプレフィックス)。 出力ファイルの接頭辞を設定する。
AnimateDiff管理は簡単だ。 - という形式をとっている。 選択可能
image/gif動画を出力するvideo/mp4およびその他のビデオフォーマット。 - ピンポン(往復)。
false通常のシーケンシャル再生trueそして、最初から最後まで、そして最初に戻る往復再生が実現する。 - save_output. に設定する。
trueノードが実行されると、ファイルはノードの実行後に自動的に保存される。
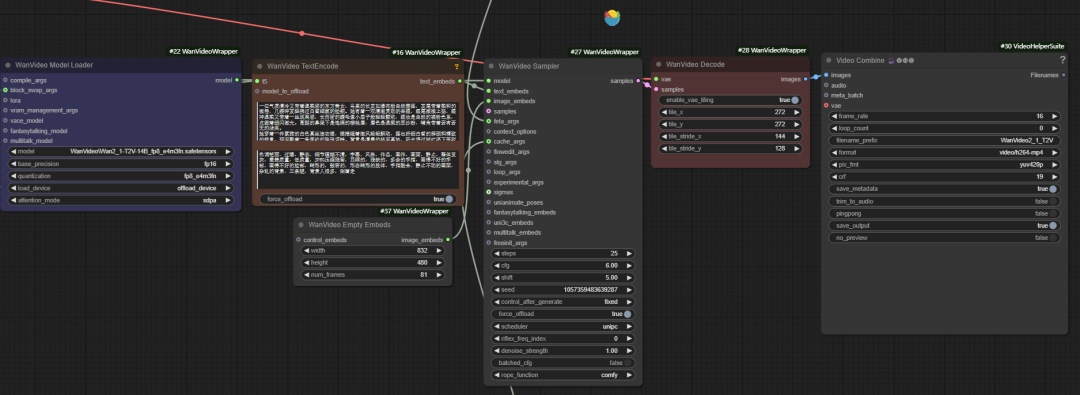
公式のワークフローは基本的な機能しか実装しておらず、メモリの最適化、ビデオの強化などの点で限界がある。そのため、開発者の "K-God "は wanvideo wrapper ツールキットは、さまざまな最適化ノードを提供する。
最適化の核心:ワンビデオ・ラッパー
wanvideo model loader
wanvideo model loader は強力なモデルローディングノードである。 wanvideo モデルで、豊富な最適化オプションも提供する。
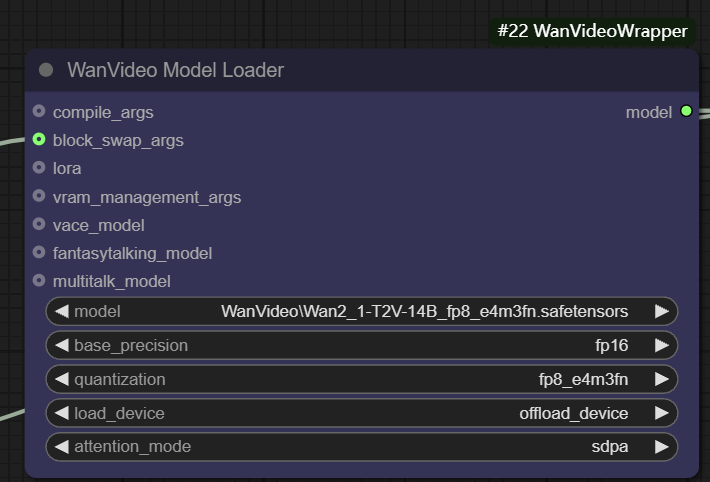
- ベースの精度。 ユーザーは、次のような異なるモデル精度を選択できます。
fp32、bf16、fp16。fp32(32ビット浮動小数点)精度は最も高いが、メモリフットプリントと計算オーバーヘッドが最も大きい;fp16(16ビット浮動小数点)は、メモリ使用量を大幅に削減し、速度を向上させることができるが、精度を犠牲にする可能性がある。 - 定量化。 とおす
quantizationオプションを使用すると、モデルを定量化してさらに圧縮することができる。例えばfp8_e4m3fnこのフォーマットは、8ビット浮動小数点表現を使用するため、メモリ要件が大幅に削減され、特にビデオメモリが限られているデバイスに適していますが、通常、モデルが事前にサポートされた量子化を必要とします。
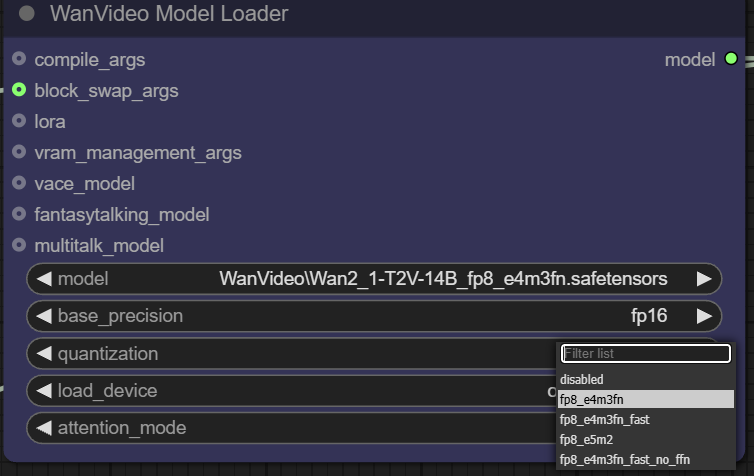
- 負荷装置。
main deviceは通常GPUを指す。offload deviceこの機能により、モデルの一部のコンポーネントをCPUにオフロードし、貴重なビデオメモリリソースを節約することができる。
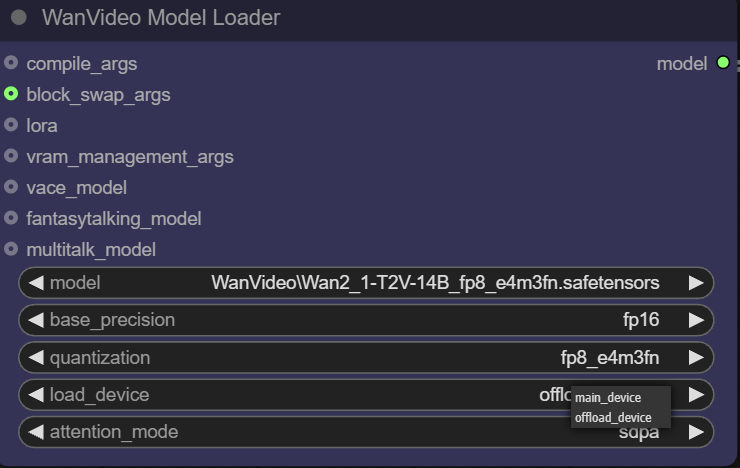
- 注意モード。 このオプションにより、ユーザーはパフォーマンスとメモリーのバランスを取るために、注意メカニズムの異なる実装を選択することができる。アテンション・メカニズムはTransformerモデルの中核であり、コンテンツ生成時にモデルが入力情報の関連部分にどのように「フォーカス」するかを決定する。
ローダーはまた、高度な最適化のためにいくつかの入力インターフェースを提供する:
- 引数をコンパイルする。 このインターフェイスは
torch.compile或xformersおよびその他のコンパイル最適化。xformersを最適化するための特別なツールである。 Transformer ライブラリとtorch.compileは PyTorch 2.0 で導入されたオンザフライコンパイラです。もしTritonコンパイラを使用した場合、約30%のスピードアップが得られる。
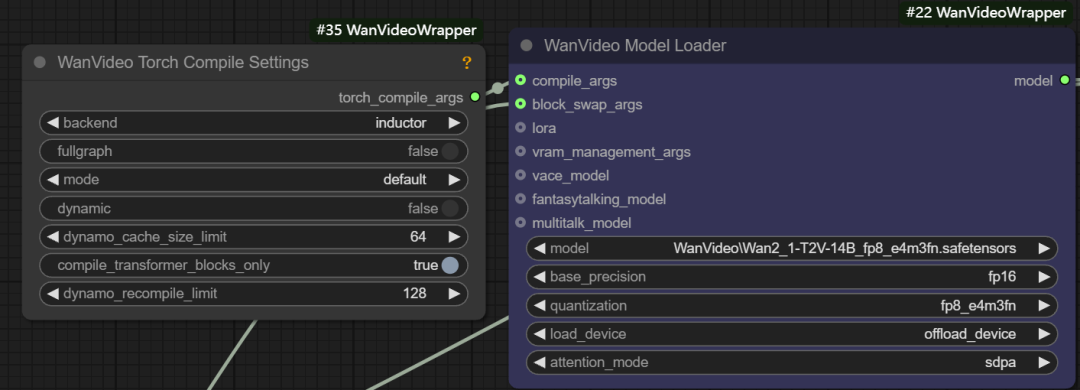
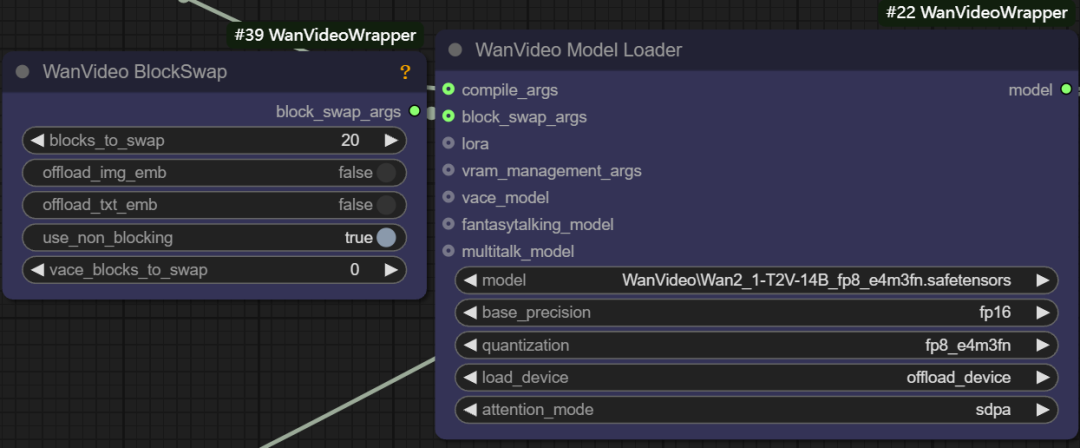
- ブロック交換の引数。 この機能は、例えば、モデル全体を保持するのに十分なメモリーがない場合に、モデルのいくつかの「ブロック」を一時的にCPUに保存することができる。
blocks to swapつまり、モデルの20ブロックがGPUから移動され、必要なときにノンブロッ キングで戻されます。移動されるブロックが多ければ多いほど、メモリ節約効果は大きくなりますが、データの往復転送により、ある程度の世代速度が犠牲になります。
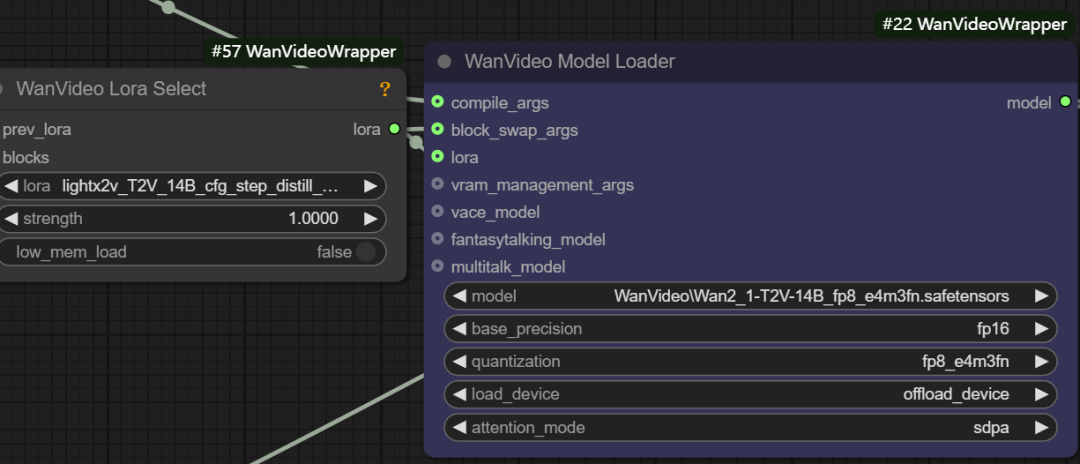
- LoRAローディング。 このインターフェースは
wanvideo lora select様々なタイプのLoRAモデルをロードするためのノード。light x2v t2vロラ
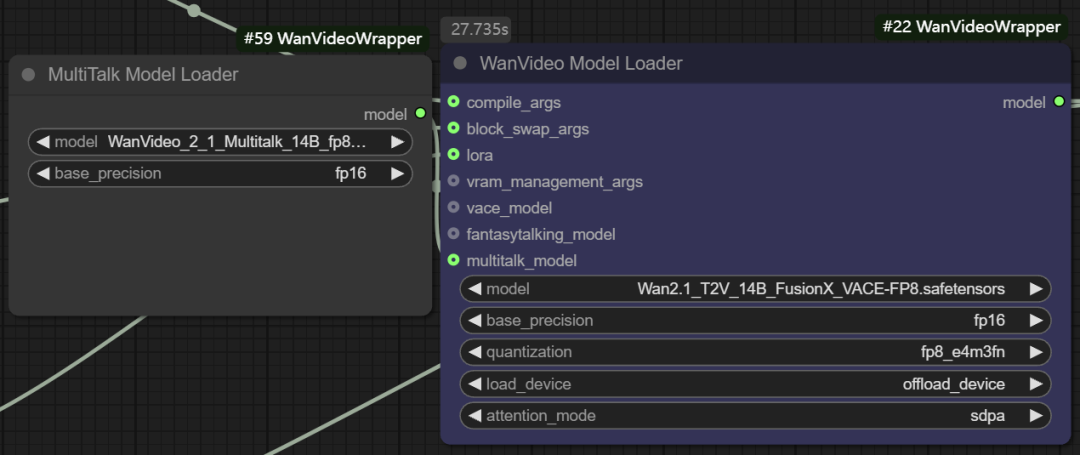
- マルチトーク機能モデリング。 また、このノードは
Multitalk、Fantasytalkingなどのデジタル人体モデルは、開発者により次のように統合される。wanvideo wrapper新興オープンソースプロジェクトの
wanvideo sampler
wanvideo sampler に基づいている。 wan2.1 ビデオシーケンスフレームの生成の中心となる、カスタマイズされたビデオサンプリングノードをモデル化する。
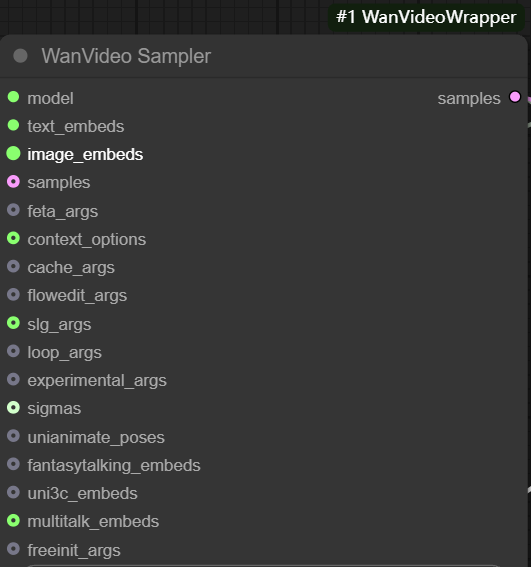
主なインプットは以下の通り:
- model: からの接続
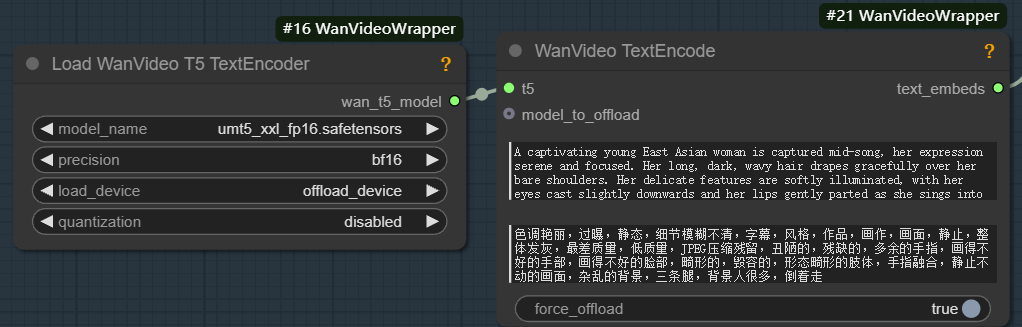
wanvideo model loaderモデルだ。 - テキストを埋め込む。 グラウト
wanvideo text encodeを使用する。unmt5エンコードされたテキスト・ベクトルが渡される。
- 画像を埋め込む。 画像からビデオへの生成を可能にするために使用される。このワークフローは通常
wanvideo clipvision encodeのリファレンス・マップを抽出する。CLIPを経てwanvideo image to video encodeノードはVAEを使用して、画像の特徴をモデルで使用可能なベクトル表現にエンコードする。
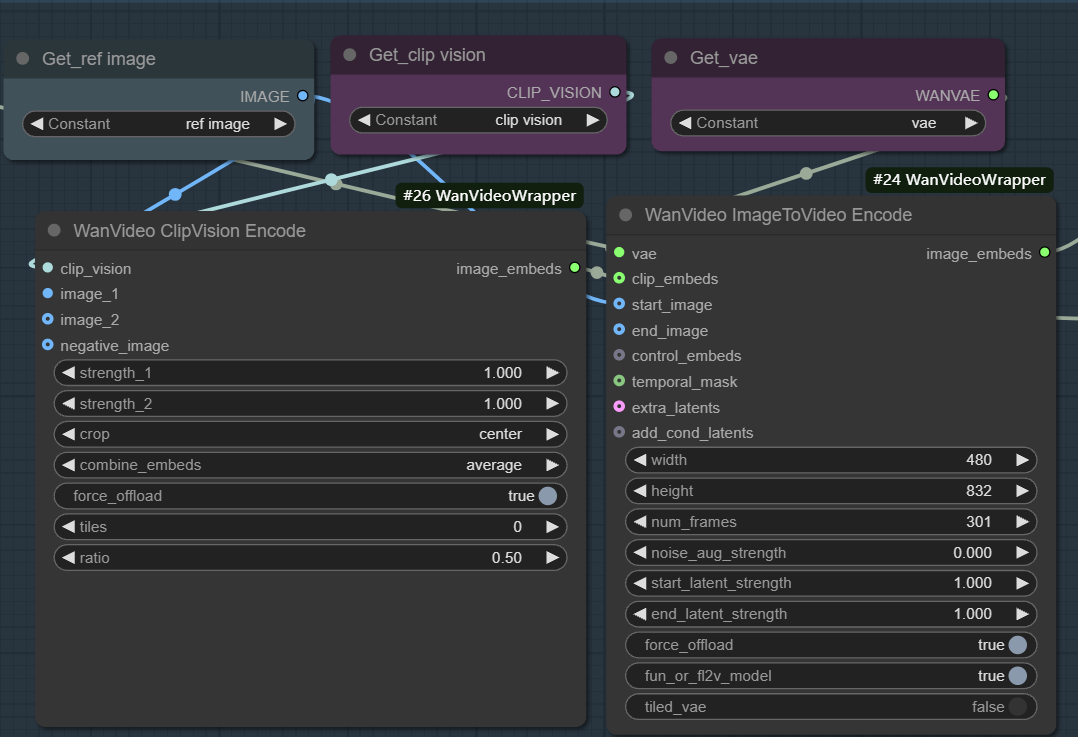
このプロセスの本質は、まず静止画像の視覚的・意味的情報を特徴ベクトルに変換し、次にサンプラーがこれらの特徴をブートストラップ条件として、ノイズから始まる反復的ノイズ除去を行い、最終的に参照マップと一致する内容とスタイルを持つ連続したビデオフレームを生成することである。重み、ノイズ、フレーム数などのパラメータを調整することで、参照マップの影響や映像の多様性を正確に制御することができる。
- samples: この入力は、理論的には、拡散反復の出発点として前ステージのサンプリング結果を受け取ることができるが、この入力は、拡散反復の出発点として前ステージのサンプリング結果を受け取ることができない。
latent書式と標準的なヴァンセンヌ・チャートlatent互換性がない。 - feta args: ビデオエンハンスメントノードの接続に使用し、ビデオのディテール、フレームアライメント、タイミングの安定性を向上させる。
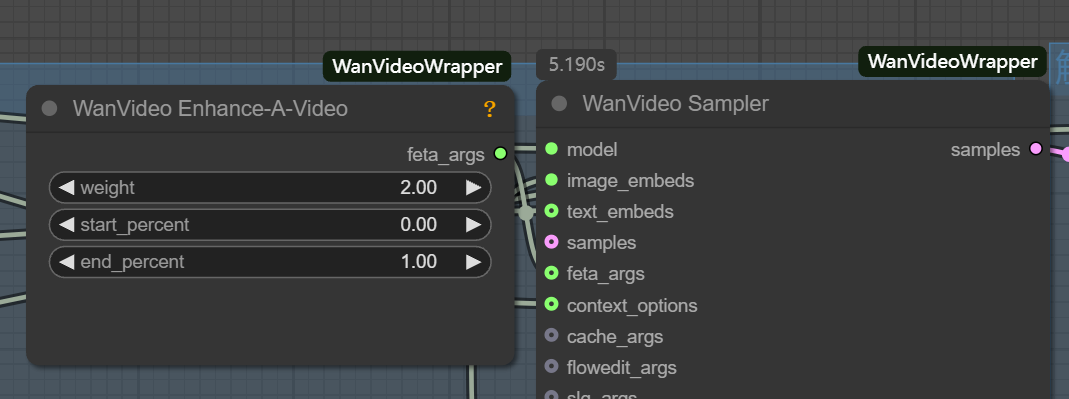
- wanvideo context options: これは、ビデオフレーム間の一貫性を確保するための重要なコントローラーである。これは、現在のフレームを生成する際にモデルが文脈情報を参照する方法を制御することで、独立したフレーム生成によって引き起こされるフレームの不連続や不自然な動きの問題を解決する。
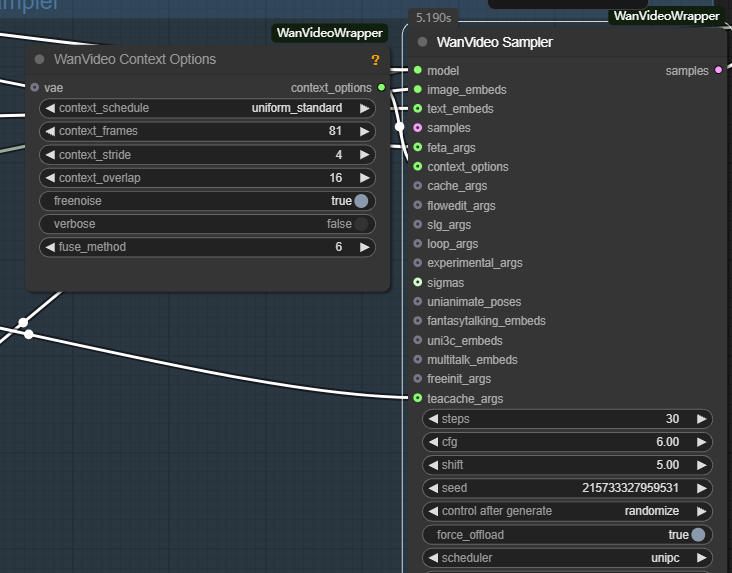
主なパラメータは以下の通り:
- context_frames。 モデルが一度に参照する隣接フレームの数を定義する。この値が大きいほど、動きとシーンの変化のコヒーレンスが良くなるが、計算量はそれに応じて増加する。
- context_stride(コンテキストのステップ)。 サンプリングされた参照フレームの間隔を制御する。ステップサイズが小さいほど、リファレンスが密になり、ディテールの遷移が滑らかになります。
- context_overlap。 隣り合う参照ウィンドウ間のオーバーラップするフレーム数を定義します。オーバーラップが大きいほど、フレーム間の遷移がスムーズになり、ウィンドウを切り替えたときの急激な変化を避けることができる。
ベン図の分野におけるビデオモデリングの可能性
特筆すべきは、次の点だ。 wan2.1 ワークフローの出力フレームレートを1に設定することで、強力なテキスト生成ツールとなる。 Flux などの特殊な画像モデルがある。動画モデルは、時間次元の追加処理により、画像の内部構造や細部について優れた理解を持つ可能性がある。このことは、動画モデルが将来、静止画生成の分野で重要な力を持つようになる可能性を示唆している。





























