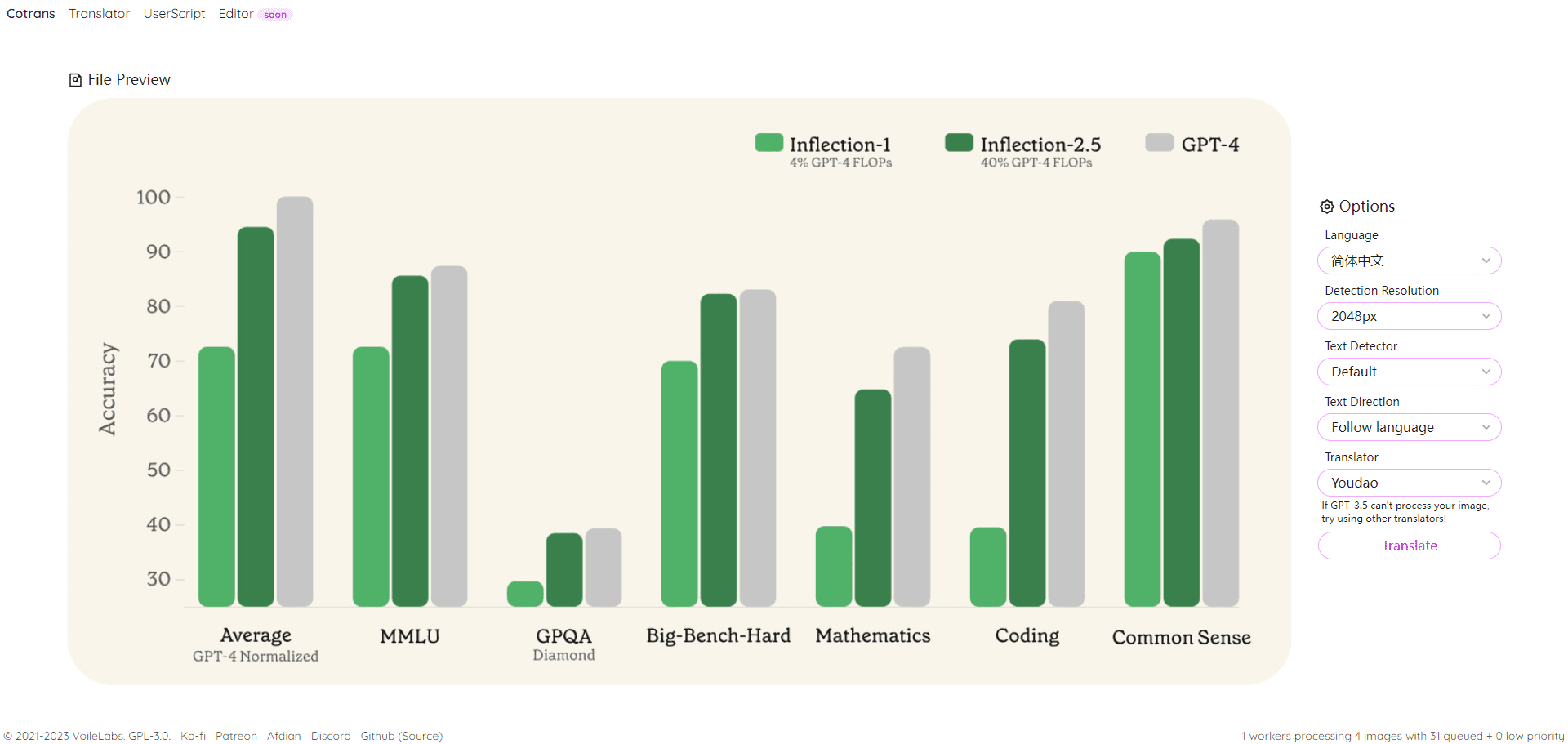
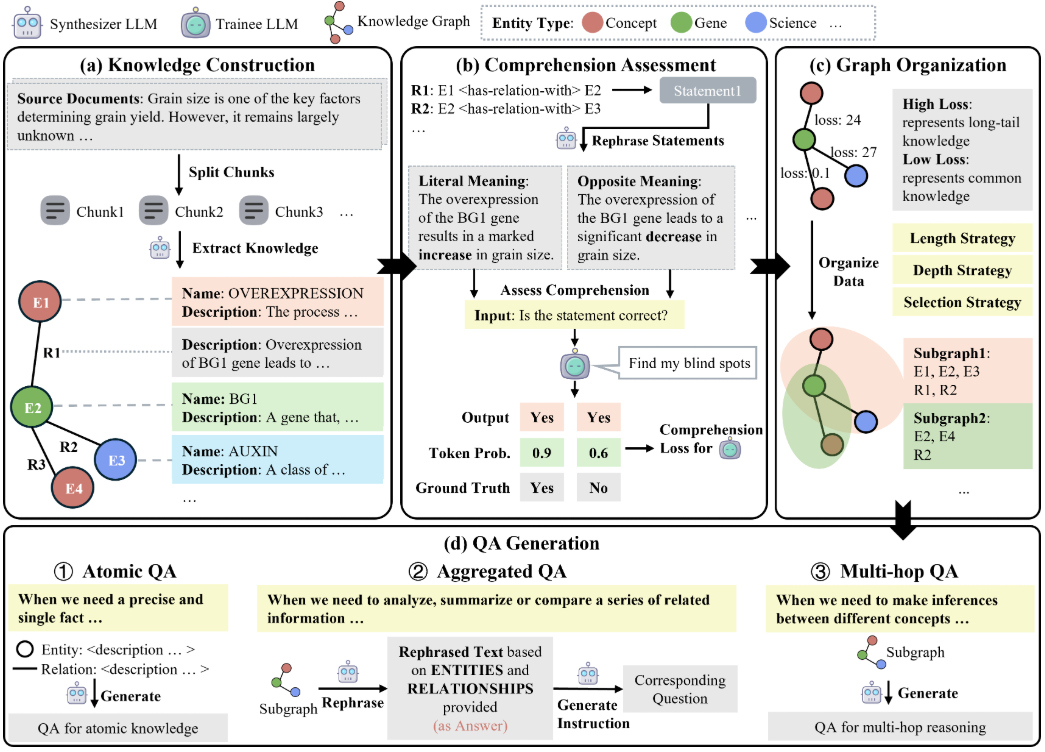
ImBD (Imitate Before Detect) 是一个开创性的机器生成文本检测项目,该项目发表于AAAI 2025会议。随着ChatGPT等大语言模型(LLMs)的广泛应用,识别AI生成的文本内容变得越来越具有挑战性。ImBD项目提出了一种新颖的”先模仿后检测”方法,通过深入理解和模仿机器文本的风格特征来提升检测效果。该方法首次提出对齐机器文本的风格偏好,建立了一个全面的文本检测框架,能够有效识别经过人工修改的机器生成文本。项目采用Apache 2.0开源许可证,提供了完整的代码实现、预训练模型和详细文档,方便研究人员和开发者在此基础上进行进一步的研究和应用开发。

デモアドレス:https://ai-detector.fenz.ai/ai-detector
機能一覧
- 機械生成テキストの高精度検出をサポート
- 訓練済みのモデルを提供し、直接配備して使用できるようにする。
- 新しいテキストスタイル特徴アライメントアルゴリズムの実装
- 詳細な実験データセットと評価ベンチマークを含む
- 完全なトレーニングと推論コードを提供する
- モデルの微調整のためのカスタムトレーニングデータをサポート
- 詳細なAPIドキュメントと使用例が含まれています。
- 迅速なテストと評価のためのコマンドラインツールを提供
- テキスト一括処理に対応
- テスト結果を表示する視覚化ツールを含む
ヘルプの使用
1.環境構成
まずPythonの環境を設定し、必要な依存関係をインストールする必要がある:
git clone https://github.com/Jiaqi-Chen-00/ImBD
cd ImBD
pip install -r requirements.txt
2.データの準備
ImBDを使い始める前に、トレーニングデータとテストデータを準備する必要がある。データは以下の2つのカテゴリーを含む必要がある:
- 手作業で作成された原文
- 機械生成または機械修正されたテキスト
データフォーマットの要件:
- テキストファイルはUTF-8でエンコードする必要があります。
- 各サンプルは1行を占める
- データセットを訓練セット、検証セット、テストセットに8:1:1の割合で分割することが提案されている。
3.モデルトレーニング
以下のコマンドを実行してトレーニングを開始する:
python train.py \
--train_data path/to/train.txt \
--val_data path/to/val.txt \
--model_output_dir path/to/save/model \
--batch_size 32 \
--learning_rate 2e-5 \
--num_epochs 5
4.モデル評価
テストセットを使ってモデルの性能を評価する:
python evaluate.py \
--model_path path/to/saved/model \
--test_data path/to/test.txt \
--output_file evaluation_results.txt
5.テキスト検出
個々のテキストの検出:
python detect.py \
--model_path path/to/saved/model \
--input_text "要检测的文本内容" \
--output_format json
テキストの一括検出:
python batch_detect.py \
--model_path path/to/saved/model \
--input_file input.txt \
--output_file results.json
6.高度な機能
6.1 モデルの微調整
ドメイン固有のテキストに最適化する必要がある場合は、独自のデータセットを使ってモデルを微調整できる:
python finetune.py \
--pretrained_model_path path/to/pretrained/model \
--train_data path/to/domain/data \
--output_dir path/to/finetuned/model
6.2 視覚化分析
内蔵の可視化ツールを使って試験結果を分析:
python visualize.py \
--results_file path/to/results.json \
--output_dir path/to/visualizations
6.3 APIサービスの配置
モデルをREST APIサービスとしてデプロイする:
python serve.py \
--model_path path/to/saved/model \
--host 0.0.0.0 \
--port 8000
7.注意事項
- GPUはモデルトレーニングの効率化のために推奨される
- トレーニングデータの質はモデルの性能に大きな影響を与える
- 定期的にモデルを更新し、AIが生成した新しいテキストの特徴に対応する。
- 本番環境にデプロイする際のモデルのバージョン管理への注意
- テスト結果は、その後の分析やモデルの最適化のために保存しておくことを推奨する。
8.よくある質問
Q: どの言語に対応していますか?
A: 現在、主に英語をサポートしています。他の言語は対応するデータセットでトレーニングする必要があります。
Q: 検査の精度を上げるにはどうしたらいいですか?
A: パフォーマンスは、トレーニングデータの追加、モデルパラメータの調整、ドメイン固有のデータを使用した微調整によって向上させることができます。
Q: 検出速度はどのように最適化できますか?
A: 検出速度は、バッチ処理、モデルの定量化、GPUアクセラレーションの使用によって向上させることができます。