


SongGenerationはTencent AI Labによって開発され、オープンソース化された音楽生成モデルで、歌詞、伴奏、ボーカルを含む高品質の楽曲生成に焦点を当てている。LeVoフレームワークをベースに、言語モデルLeLMと音楽コーデックを組み合わせ、中国語と英語の楽曲生成をサポートしている。このモデルは何百万もの楽曲データセットで学習され、優れた音質と完全な構造を持つ楽曲を生成する。SongGenerationはオープンソースであるため、開発者、音楽愛好家、コンテンツ制作者が利用しやすく、低メモリデバイスでの動作に対応しているため、利用障壁が低くなっている。
機能一覧
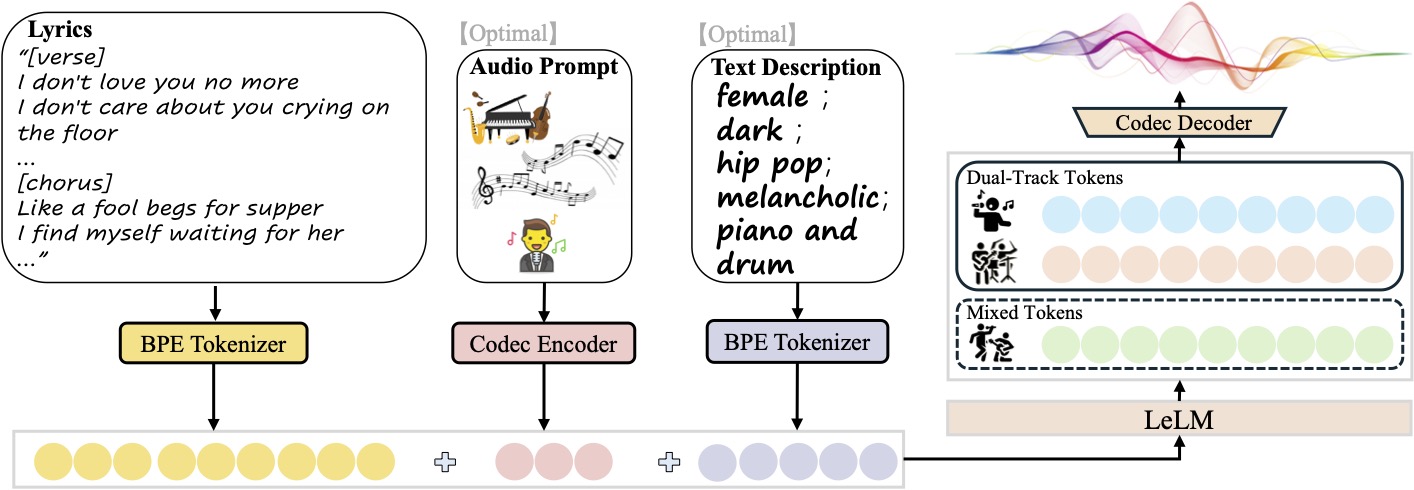
- 歌の世代入力された歌詞とテキストに基づき、ボーカルとバッキングトラックを含むフルソングを生成します。
- マルチトラック出力純粋な音楽、純粋なボーカル、またはボーカルとバッキングトラックを別々に生成し、ポスト編集を簡単に行うことができます。
- スタイル・コントロール性別、音色、ジャンル、感情、楽器、拍子など)。
- リファレンス・オーディオモデルは10秒間のオーディオクリップをアップロードすることができ、それと同じスタイルの新曲を生成することができる。
- 低メモリ最適化様々なデバイスに対応するため、最小10GBのGPUメモリで動作します。
- オープンソース・サポートモデルの重み、推論スクリプト、設定ファイルは提供され、開発者が自由に変更・最適化できる。
ヘルプの使用
設置プロセス
SongGenerationを使用するには、環境の設定とモデルのインストールが必要です。以下は、Linux用の公式GitHubリポジトリに基づく手順である(Windowsユーザーは以下を参照)。 ComfyUI (バージョン):
- Python環境の作成
Python 3.8.12以降では、conda経由で仮想環境を作成することを推奨します:conda create -n songgeneration python=3.8.12 conda activate songgeneration - 依存関係のインストール
PyTorchとFFmpegを含む必要な依存関係をインストールする:yum install ffmpeg pip install -r requirements.txt --no-deps --extra-index-url https://download.pytorch.org/whl/cu118 - フラッシュ・アテンションをインストールする(オプション)
推論を高速化するには、Flash Attentionをインストールする(CUDA 11.8以上が必要):wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl -P /home/ pip install /home/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whlGPUがフラッシュ・アテンションをサポートしていない場合は、以下の推論を追加してください。
--not_use_flash_attnパラメーター - モデルウェイトのダウンロード
Hugging Faceからモデルのウェイトとプロファイルをダウンロードし、以下のことを確認する。ckpt和third_partyフォルダはプロジェクト・ルート・ディレクトリに丸ごと保存される:git clone https://github.com/tencent-ailab/SongGeneration cd SongGenerationハギング・フェイスのリポジトリ(
https://huggingface.co/tencent/SongGeneration) ダウンロードsonggeneration_base_zhまたは他のバージョンのモデルウェイト。 - Dockerのインストール(オプション)
設定を簡単にするために、公式のDockerイメージを使用することができる:docker pull juhayna/song-generation-levo:hf0613 docker run -it --gpus all --network=host juhayna/song-generation-levo:hf0613 /bin/bash
使用方法
SongGenerationは、コマンドラインやスクリプトによる音楽生成に対応しており、主な操作は、入力ファイルを準備し、推論スクリプトを実行することです。以下は詳細な操作の流れです:
- 入力ファイルの準備
入力ファイルはJSON行(.jsonl)形式で、各行は生成されたリクエストを表し、以下のフィールドを含む:idx生成されたオーディオのファイル名(一意の識別子)。gt_lyric歌詞のフォーマット[结构] 歌词文本例[Verse] 这是第一段歌词。.サポートされる構造には以下が含まれる。[intro-short]、[verse]、[chorus]等々、具体的にはconf/vocab.yaml。descriptions(オプション): 以下のような音楽の属性を記述します。female, pop, sad, piano, the bpm is 125。prompt_audio_path(オプション):スタイル模倣のための10秒間のリファレンス・オーディオ・パス。
典型例
lyrics.jsonl:{"idx": "song1", "gt_lyric": "[intro-short]\n[verse] 这些逝去的回忆。我们无法抹去泪水。\n[chorus] 像傻瓜乞求晚餐。我在等待她的归来。", "descriptions": "female, pop, sad, piano, the bpm is 125"} - 推論スクリプトの実行
曲の生成にはデフォルトのスクリプトを使用する:sh generate.sh <ckpt_path> <lyrics.jsonl> <output_path><ckpt_path>モデルウェイトパス。<lyrics.jsonl>ファイルパスを入力してください。<output_path>出力オーディオの保存パス。
GPUメモリが不足している場合(30GB未満)、低メモリモードを使用します:
sh generate_lowmem.sh <ckpt_path> <lyrics.jsonl> <output_path> - カスタム・ジェネレーション・オプション
- 純粋な音楽の生成:追加
--pure_musicロゴ - 純粋なボーカルを生成する
--pure_vocalロゴ - ボーカルとバッキング・トラックの分離:追加
--separate_tracksフラグを使うと、ボーカルとバッキングのトラックが別々に生成される。 - フラッシュを無効にする 注意:追加
--not_use_flash_attn。
- 純粋な音楽の生成:追加
- Windowsユーザー(ComfyUI版)
Windowsユーザーは、操作を簡素化するためにComfyUIインターフェイスを使用することができます:- ComfyUIプラグインリポジトリをクローンします:
cd ComfyUI/custom_nodes git clone https://github.com/smthemex/ComfyUI_SongGeneration.git - 取り付け
fairseqライブラリ(Windowsではコンパイル済みのホイールファイルを推奨)を使用する:pip install liyaodev/fairseq - モデルの重みを
ComfyUI/models/SongGeneration/カタログ - ComfyUIインターフェイスからモデルを読み込み、歌詞と説明を入力し、生成ボタンをクリックします。
- ComfyUIプラグインリポジトリをクローンします:
取り扱い上の注意
- 入力プロンプトの同時提供は避ける。
prompt_audio_path和descriptionsそうでなければ、コンフリクトによって発電の質が低下する可能性がある。 - 歌詞フォーマット歌詞はセクションごとに構成する必要がある。
[verse]、[chorus]など)、非リリックス・セグメント[intro-short])は歌詞を含んではならない。 - リファレンス・オーディオ音楽性を最適化するために、曲のサビ(10秒以下)を使用することをお勧めします。
- ハードウェア要件GPUメモリはベースモデルで10GB、リファレンスオーディオで16GB。
アプリケーションシナリオ
- 作曲
ミュージシャンは歌詞やスタイルの説明を入力することで、曲のデモを素早く生成し、時間を節約することができます。例えば、"男声、ジャズ、ピアノ、110 BPM "と入力すると、ジャズ・スタイルの曲が生成されます。 - ビデオ・サウンドトラック
ビデオ制作者は、10秒間のリファレンス・オーディオをアップロードして、ショート・ビデオ、コマーシャル、映画音楽のための様式化されたサウンドトラックを生成することができる。 - ゲーム開発
ゲーム開発者は、バトルやストーリーなど、さまざまなゲームシナリオに合わせてボーカルとバッキングトラックを別々に調整し、マルチトラック音楽を生成することができます。 - 教育と実験
学生や研究者は、オープンソースコードを使って音楽生成アルゴリズムを研究したり、AIによる音楽制作の効果を教室でテストしたりすることができる。
QA
- SongGenerationはどの言語に対応していますか?
現在、中国語と英語の曲の生成をサポートしており、モデルは100万曲のデータセット(中国語と英語の曲を含む)で訓練されており、将来的にはさらに多くの言語をサポートする可能性がある。 - 生成された音楽の音質を保証するには?
提供されている公式モデルのウェイトと音楽コーデックを使用し、オーディオのサンプルレートが48kHzであることを確認してください。短すぎる歌詞の使用は避けてください。 - モデルの実行に必要なメモリ容量は?
GPUメモリはベースモデルで10GB、リファレンスオーディオで16GB。generate_lowmem.sh)はメモリ使用量を最適化できる。 - 商業的に制作された音楽を使用することはできますか?
モデルライセンス(CC BY-NC 4.0)を確認する必要があり、生成されたコンテンツは著作権の制限を受ける可能性があるため、商用利用の前に法律の専門家に相談することを推奨する。


























