

大きな言語モデリングと工学的実践のパラダイムが進化するにつれて、人間の研究プロセスを模倣するように設計されたインテリジェンスのための様々なアプリケーションが出現してきた。これらのインテリジェンスは、単なる質疑応答ツールではなく、自律的に情報を計画、実行、反映、合成できる複雑なシステムである。本稿では、以下のような様々な研究ベースの知的身体フレームワークのアーキテクチャ設計と機能実装を分解する。 OpenAI 公式リリース DeepResearch このガイドは、いくつかの主要なオープンソース・フレームワークの本質的な違いや設計思想を深く分析したアイデアの源であり、開発者やユーザーがツールを選択する際に体系的かつ戦略的なリファレンスを提供する。
オープンソースのディープリサーチ・インテリジェンス・ボディ・フレームワーク
コア・コンセプトの比較
現在、汎用のスマート・ボディ・フレームワークが数多く市場に出回っている(例えば、以下のようなもの)。 Auto-GPT、AutoGen など)は研究タスクを実行することができるが、本稿では、深い研究シナリオのために特定のアーキテクチャで最適化された6つのオープンソースプロジェクトに焦点を当てる。
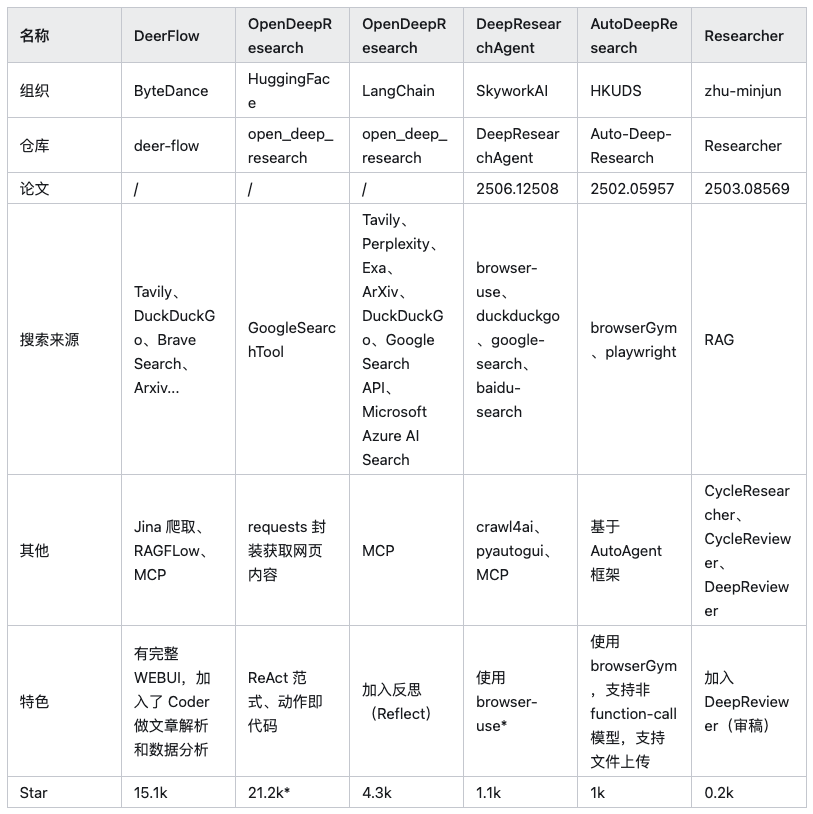
注:上記の表では HuggingFace/OpenDeepResearch 星の数の多さは、その核心的な依存関係から来ている。 SmolAgents プロジェクト
各フレームワークを深く分析する前に、ひとつはっきりさせておかなければならないことがある。そのため browser-use このようなAI主導のブラウザ自動化ツールは、このようなフレームワークの重要な補助的存在である。これらのツールは、動的なウェブページの読み込み、ページ要素との対話、データの抽出などのタスクを実行する役割を担っている。 JavaScript コンテンツをレンダリングする際のペインポイントだが、この記事の核心であるフレームワークそのものではない。
OpenAI ガイド:3段階のパラダイムを築く
OpenAI の公式文書 Deep Research をガイドに、その後のほとんどすべての研究ベースのインテリジェンスのアイデアの源となるアーキテクチャを提案している。その核となる考え方は、非常に壊れやすくデバッグが困難な、かさばるプロンプト1つで1ステップで問題を解決するという幻想を捨てることである。このガイドは、複雑なリサーチタスクを3つの別々のモジュールプロセスに分解することを提唱している:計画→実行→合成これは、長距離推論と文脈長制約という大規模言語モデルに内在する課題を克服することを目的とした典型的な「分割統治」戦略である。これは、長距離推論、事実の一貫性、文脈の長さの制約という、大規模な言語モデルに内在する課題を克服することを目的とした、典型的な「分割統治」戦略である。

- プラン高度に抽象化され、論理的な推論が可能な高次モデル(例えば
GPT-4o)では、ユーザーの主な問題を、一連の具体的で独立に研究可能な、網羅的な副問題に分解する。このステップの質によって、研究の幅と深さが決まる。 - 実行する各サブ問題を並列処理する。各サブ問題に対して、外部検索APIを呼び出して情報を取得し、モデルが単一の情報源から初期要約と事実抽出を実行できるようにする。これは高度に並列な情報収集フェーズである。
- 合成(シンセサイズ)すべてのサブクエスチョンに対する答えを集約し、最終的な統合、分析、装飾のために、論理的に首尾一貫し、明確に構成された最終報告書として高次モデルに再度渡す。
実施戦略とベストプラクティス
この核となる構造に基づいて、いくつかの重要な練習戦略を紹介しよう:
1.適切なタスクに適切なモデルを選択する
これがコストとパフォーマンスの最適化の核心である。フェーズによって、必要とされる "インテリジェンス "の種類は異なる。プランニング "と "合成 "のフェーズでは、強力な "インテリジェンス "が必要とされる。グローバルな推論力、論理的構成力、創造的生成力を使用しなければならない。 GPT-4o 或 GPT-4 Turbo これらのモデルのパフォーマンスが最終レポートの品質の上限を決定するためである。実行 "フェーズでは、個々のウェブページを要約するタスクがより重視される情報抽出とファクトリエンリッチメント用途 GPT-3.5-Turbo などの高速モデルは、品質を維持しながらコストとレイテンシーを劇的に削減することができる。1つのディープリサーチリクエストが何十ものAPIコールを引き起こす可能性があり、モデル階層がなければ、コストはすぐにエスカレートする。
2.効率を最大化する並列処理
研究のサブ問題は通常互いに独立しており、シリアル処理は非常に時間がかかる。実行」段階では、いったん部分問題のリストが生成されると、それを非同期的にプログラムする必要がある(たとえば Python 的 asyncio)を使って並行して研究依頼を開始する。これにより、数分かかる処理を1分未満に短縮することができる。しかしながら、開発者はAPIベンダーのレート制限、特に TPM (1分間に処理されるトークン数)。並列呼び出しは、瞬時に大量のリクエストを生成し、1分間に処理されるトークン数を TPM 制限があるとリクエストに失敗するので、うまく設計されたリクエストキューとリトライメカニズムが必要である。
3.関数呼び出しまたはJSONパターンを使用して、構造化された出力を保証する。
安定した信頼性の高いワークフローを保証するために、モデルは常に、不安定な自然言語テキストを解析するコードではなく、機械可読の構造化データを返すようにすべきである。OpenAI これを実現する最良の方法は、「関数呼び出し」または「JSONモード」機能である。これは、コードと LLM これにより、強固なAPI契約が確立されます。計画フェーズでは、モデルにすべてのサブ問題の文字列のJSONリストを出力させることができ、実行フェーズでは、モデルに次のような固定のJSON形式で結果を返すよう要求することもできます。 {"summary": "...", "key_points": [...]}。
4.質の高い外部検索ツールの統合
言語モデルは本質的にリアルタイムのネットワーク機能を持たず、その知識はタイムラグに悩まされる。そのため、1つ以上の高品質な検索API(たとえば Google Search API、Brave Search API、Serper など)を使って、リアルタイムの広範な情報にアクセスすることができる。これらのツールを使用できることをキューワードで明示的にモデルに伝え、ツールの出力を関数呼び出しなどを通じてモデルに返すことが、モデルに研究能力を与える基礎となる。
5.各ステージにおけるプロンプトの精緻化(プロンプト・エンジニアリング)
キュー・ワードは、各ステージの質を決定する鍵となる。各ステージのキューワードは、モデルが適切な役割を果たし、望ましい結果が得られるよう、注意深く設計されるべきである。オフィシャルガイドに掲載されている以下のサンプルインプットは非常に参考になる。
最初の質問
Research the economic impact of semaglutide on global healthcare systems.
Do:
- Include specific figures, trends, statistics, and measurable outcomes.
- Prioritize reliable, up-to-date sources: peer-reviewed research, health
organizations (e.g., WHO, CDC), regulatory agencies, or pharmaceutical
earnings reports.
- Include inline citations and return all source metadata.
Be analytical, avoid generalities, and ensure that each section supports
data-backed reasoning that could inform healthcare policy or financial modeling.
研究索马鲁肽对全球医疗保健系统的经济影响。
应做的:
- 包含具体的数字、趋势、统计数据和可衡量的成果。
- 优先考虑可靠、最新的来源:同行评审的研究、卫生组织(例如世界卫生组织、美国疾病控制与预防中心)、监管机构或制药公司
的盈利报告。
- 包含内联引用并返回所有来源元数据。
进行分析,避免泛泛而谈,并确保每个部分都支持
数据支持的推理,这些推理可以为医疗保健政策或财务模型提供参考。
質問の明確化
このステップの目的は、インテリジェント・ボディが真のアドバイザーのように振る舞い、高価な研究を始める前にユーザーの意図を完全に理解するようにすることである。
You are talking to a user who is asking for a research task to be conducted. Your job is to gather more information from the user to successfully complete the task.
GUIDELINES:
- Be concise while gathering all necessary information
- Make sure to gather all the information needed to carry out the research task in a concise, well-structured manner.
- Use bullet points or numbered lists if appropriate for clarity.
- Don't ask for unnecessary information, or information that the user has already provided.
IMPORTANT: Do NOT conduct any research yourself, just gather information that will be given to a researcher to conduct the research task.
您正在与一位请求开展研究任务的用户交谈。您的工作是从用户那里收集更多信息,以成功完成任务。
指导原则:
- 收集所有必要信息时务必简洁
- 确保以简洁、结构良好的方式收集完成研究任务所需的所有信息。
- 为清晰起见,请根据需要使用项目符号或编号列表。
- 请勿询问不必要的信息或用户已提供的信息。
重要提示:请勿自行进行任何研究,只需收集将提供给研究人员进行研究任务的信息即可。
ユーザープロンプトの書き換え。
このステップでは、ユーザーの音声による要求を、研究者インテリジェンスへの詳細かつ明確な文書による指示に変換します。
You will be given a research task by a user. Your job is to produce a set of
instructions for a researcher that will complete the task. Do NOT complete the
task yourself, just provide instructions on how to complete it.
GUIDELINES:
1. **Maximize Specificity and Detail**
- Include all known user preferences and explicitly list key attributes or
dimensions to consider.
- It is of utmost importance that all details from the user are included in
the instructions.
2. **Fill in Unstated But Necessary Dimensions as Open-Ended**
- If certain attributes are essential for a meaningful output but the user
has not provided them, explicitly state that they are open-ended or default
to no specific constraint.
3. **Avoid Unwarranted Assumptions**
- If the user has not provided a particular detail, do not invent one.
- Instead, state the lack of specification and guide the researcher to treat
it as flexible or accept all possible options.
4. **Use the First Person**
- Phrase the request from the perspective of the user.
5. **Tables**
- If you determine that including a table will help illustrate, organize, or
enhance the information in the research output, you must explicitly request
that the researcher provide them.
6. **Headers and Formatting**
- You should include the expected output format in the prompt.
- If the user is asking for content that would be best returned in a
structured format (e.g. a report, plan, etc.), ask the researcher to format
as a report with the appropriate headers and formatting that ensures clarity
and structure.
7. **Language**
- If the user input is in a language other than English, tell the researcher
to respond in this language, unless the user query explicitly asks for the
response in a different language.
8. **Sources**
- If specific sources should be prioritized, specify them in the prompt.
- For product and travel research, prefer linking directly to official or
primary websites...
- For academic or scientific queries, prefer linking directly to the original
paper or official journal publication...
- If the query is in a specific language, prioritize sources published in that
language.
6.要所要所にHIL(Human-in-the-Loop)を導入。
重大な、あるいはリスクの高い研究作業では、完全自動化されたプロセスは信頼性に欠ける。ヒューマン・イン・ザ・ループ」の導入は、単なる機能ではなく、人間とコンピュータの共同作業の哲学である。効果的なプラクティスは、「計画」フェーズの後に人間によるレビュープロセスを含めることである。このプロセスでは、ユーザーがモデルによって生成されたサブ問題のリストをレビュー、修正、検証し、研究の方向性が正しいことを確認してから、コストのかかる「実行」フェーズを開始する。これにより、「屑が入り、屑が出る」ことを避け、最終結果の説明責任を確実にすることができる。
オープンソース・アーキテクチャ分析
以下では、各フレームワークのアーキテクチャ上の特徴を順番に解剖していく。
ByteDance/DeerFlowグラフに基づく階層的多知能身体システム
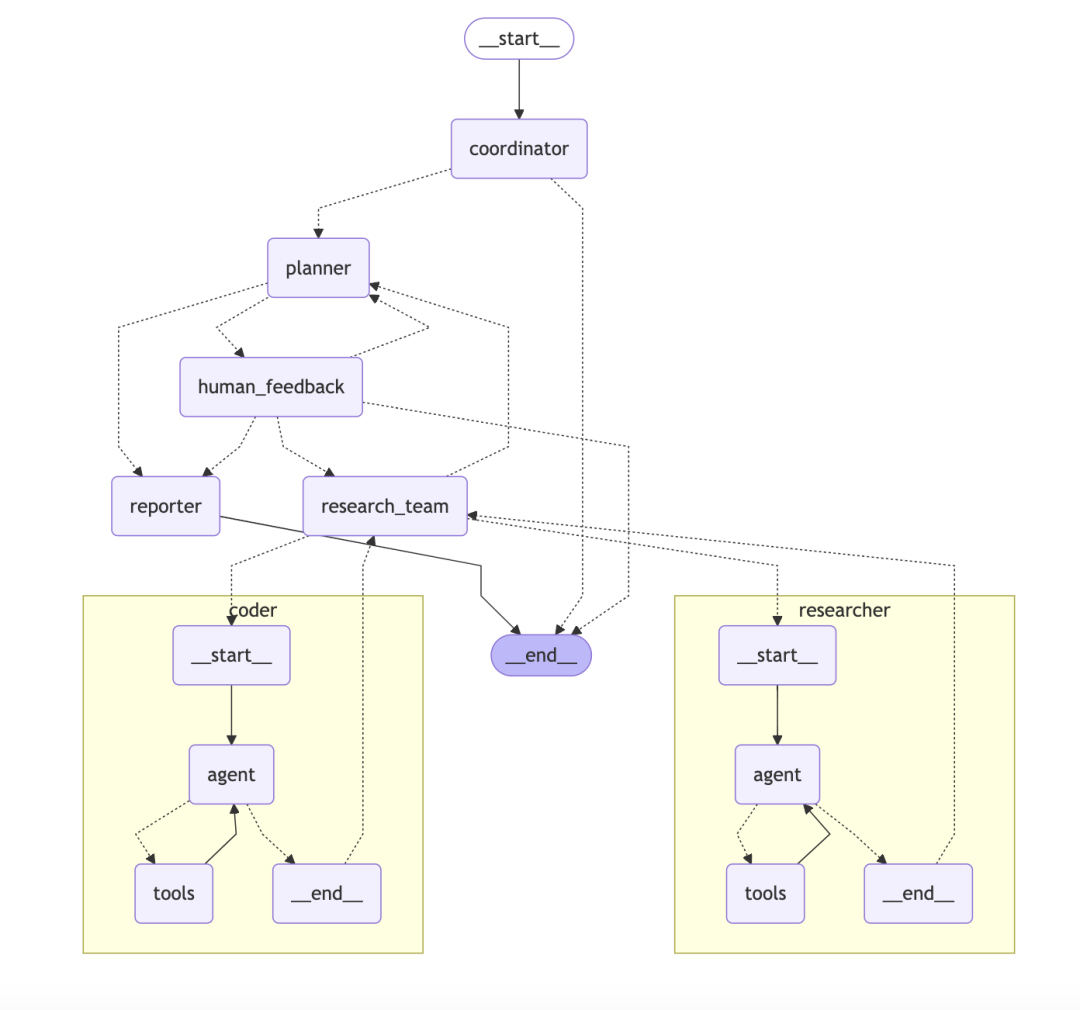
DeerFlow 明確な目標と明確な役割分担を持った自動化された研究チームのようなものだ。
- コアアーキテクチャ:: システムは複数の役割が協力し合うことで成り立っている:
- コーディネータープロジェクトマネージャーとして、ユーザーからのリクエストを受け、プロセスを開始し、管理する。
- プランナー戦略家として、複雑な問題を構造化されたステップに分解する。
- 研究チーム:: 実行者として、ウェブを検索する "研究者 "とコードを実行する "プログラマー "がいる。
- レポーター最終的なアウトプットとして、すべての情報をレポート、ポッドキャスト、さらにはPPTにまとめる。
- 技術的特徴:
DeerFlow技術的なハイライトは、その上に構築されていることである。LangChain和LangGraph以上。LangGraphは、開発者がマルチ・インテリジェンサー・ワークフローをステートフル・グラフ各インテリジェンスやツールは、グラフのノードと考えることができる。各インテリジェンスやツールはグラフのノードと考えることができ、ワークフローの方向はエッジによって定義される。このアプローチは、Reflect-Correctループのようなループを含む複雑なプロセスを自然にサポートし、研究プロセス全体を線形にするだけでなく、追跡可能でデバッグ可能なものにする。
コラムニストのコメント: DeerFlow 安定性、拡張性、複雑なワークフローをサポートする必要があるチームやエンタープライズ・アプリケーションのために、明確でよく定義された設計となっている。そのために LangGraphこれにより、インテリジェントなボディ・コラボレーションは、単純なチェーン・コールから、管理可能で周期的なグラフィカル・ネットワークへと昇華され、単なるツールというよりも「研究プロセス管理プラットフォーム」のようなものとなる。
HuggingFace/OpenDeepResearchコード・アズ・アクションのミニマリズム哲学
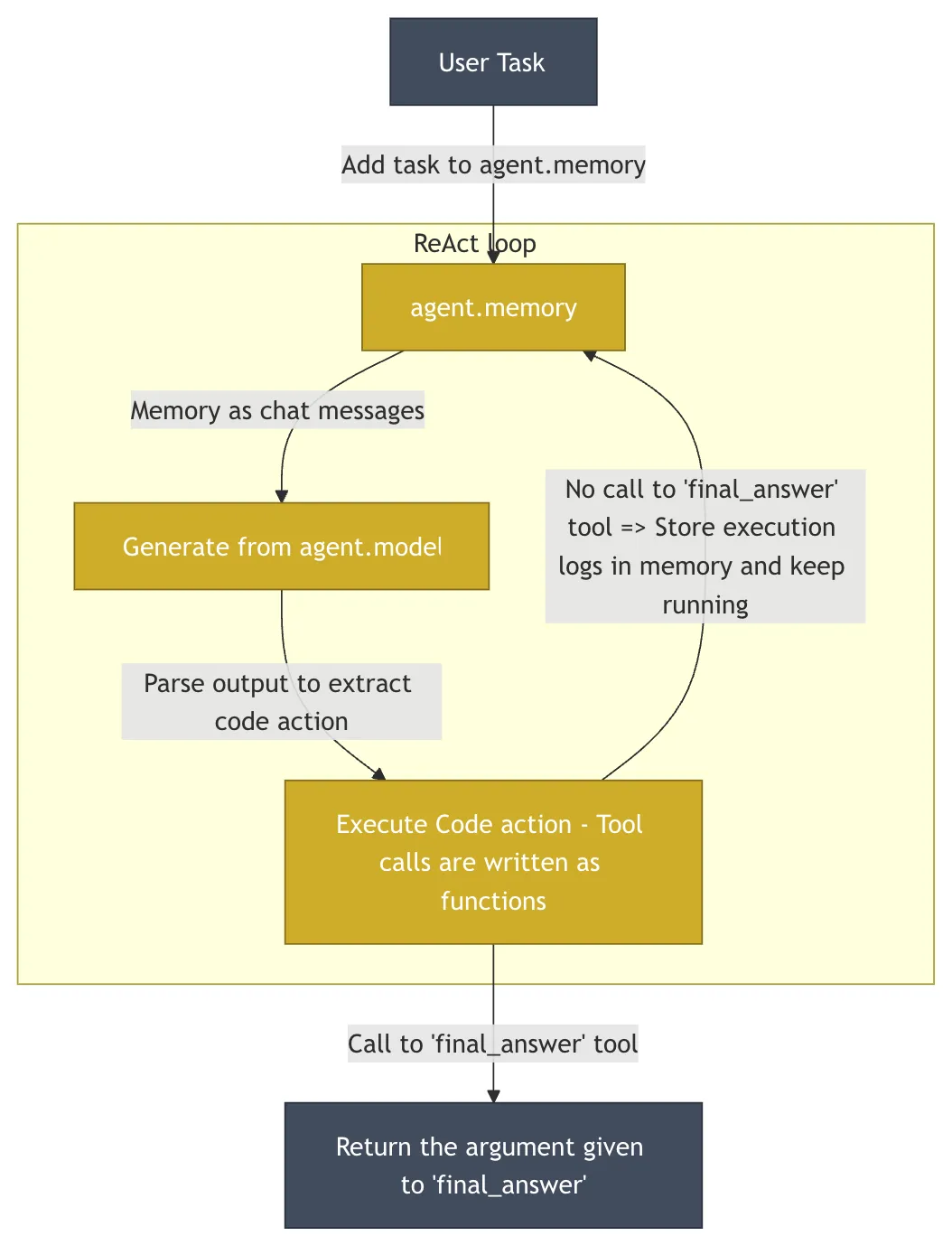
HuggingFace 的 OpenDeepResearch このプロジェクトの中核は次のようなものである。 smolagents と同じ特性を持つ。 DeerFlow まったく異なるデザイン哲学。このプロジェクトは GAIA (General AI-Assisted Agent)は、実世界のタスクを通じて一般的なAI知能の能力を測定するために設計された決定的なベンチマークである。 55% pass@1のスコア。このスコアは ChatGPT 的 67%しかし、オープンソースの実装として、その力を発揮している。
- コア・アイデア:: シンプルさと最小限の抽象化。
smolagentsのコードベースは意図的に非常に小さく(~1000行)保たれており、多くのフレームワークにありがちな過剰な抽象化を避け、開発者に非常に高い透明性と制御性を提供している。 - コアアーキテクチャコード・インテリジェンス」(
CodeAgent).知性体の作用は直接次のように表される。Pythonコード・スニペットの代わりにJSONオブジェクト。LLM小段落の作成Pythonコードで次のアクションを実行する。このアプローチはJSONなぜなら、コードはループ、条件分岐、関数定義などの複雑なロジックを自然にサポートしているからだ。しかし、AIによって生成された任意のコードを実行することは、重大なセキュリティリスクを伴う。このためsmolagents以下のような分野でのサポートE2Bそのようなサンドボックス のコードを実行する。E2B隔離されたクラウドを提供するLinuxAIが生成したコードが実行される環境では、ファイルシステムとネットワークにアクセスできるが、ホスト・システムに影響を与えることはできない。
コラムニストのコメント: smolagents コードはアクションである」というコンセプトは、プログラミングの基本に立ち返り、インテリジェンスにこれまで以上の柔軟性を与える魅力的な方法です。インテリジェンスの動作を深くカスタマイズし、完全にコントロールしたい開発者には最適な選択です。その哲学は、開発者に最大限の力を与え、安全なガードレールを提供することです。
LangChainAI/OpenDeepResearch図式化されたワークフローとメタ認知的リフレクション
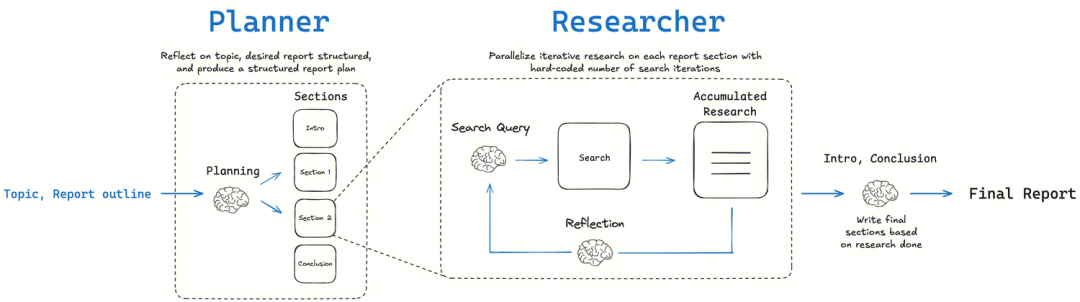
LangChain 地域密着型 open_deep_research プロジェクトの中心は、人間の専門家の研究プロセスを模倣するように設計された、多段階の反復的かつ自己反省的なワークフローである。
- コア・コンセプト: プラン-サーチ-リフレクション-ライティングこの構造の鍵は "反射 "コンポーネント。この構造の鍵は "リフレクション "コンポーネントにある。これは単にエラーをチェックするだけではなくメタ認知 これは「自分自身の思考プロセスについて考える」という表現である。最初の情報を収集した後、インテリジェンスは現在の情報の完全性、知識の矛盾やギャップがないかどうかを評価する。不足が見つかった場合、新しい、より正確な検索クエリを生成し、次の反復に進む。
- 実装方法:
- グラフベースのワークフロー:: のように
DeerFlow主に使用されるLangGraph構築。研究の各ステップはグラフのノードとしてモデル化されるため、プロセス全体が非常に視覚的で追跡可能であり、デバッグが容易である。このアプローチは、人間の介入と高精度の制御を必要とするシナリオに理想的に適している。 - マルチエージェント反復ループ再帰的な調査ループを通じて、インテリジェンスは既存の情報を評価し、新たな疑問を生み出し、ループごとにさらに調査を進める。このアプローチは2つのモードに分けられる:
简单模式 (Simple)単一の反復ループへの直接アクセスは高速で、特定の問題に適している;深度模式 (Deep)初期計画を含み、各サブトピックに並行して研究者を配置し、複雑なトピックについてはより詳細で包括的な研究を行う。
- グラフベースのワークフロー:: のように
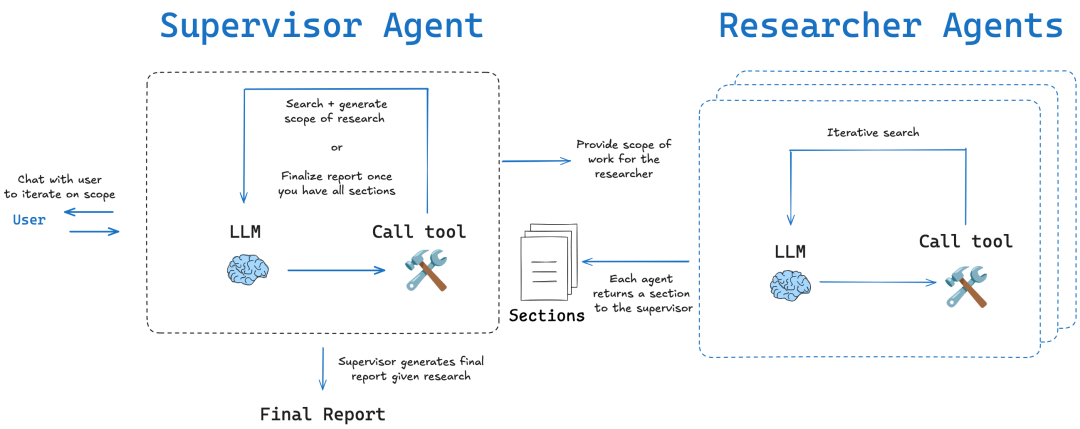
コラムニストのコメント: LangChain このバージョンは、モジュール性と柔軟性の素晴らしい例である。を使用することで、認知科学の概念である「自己反省」をうまく取り入れている。 LangGraph 複雑で非線形な研究タスクのための強力なモデリング機能を提供し、研究プロセスの製品化を必要とするチームに最適です。
SkyworkAI/DeepResearchAgent古典的なレイヤリングとコンツェルンの分離
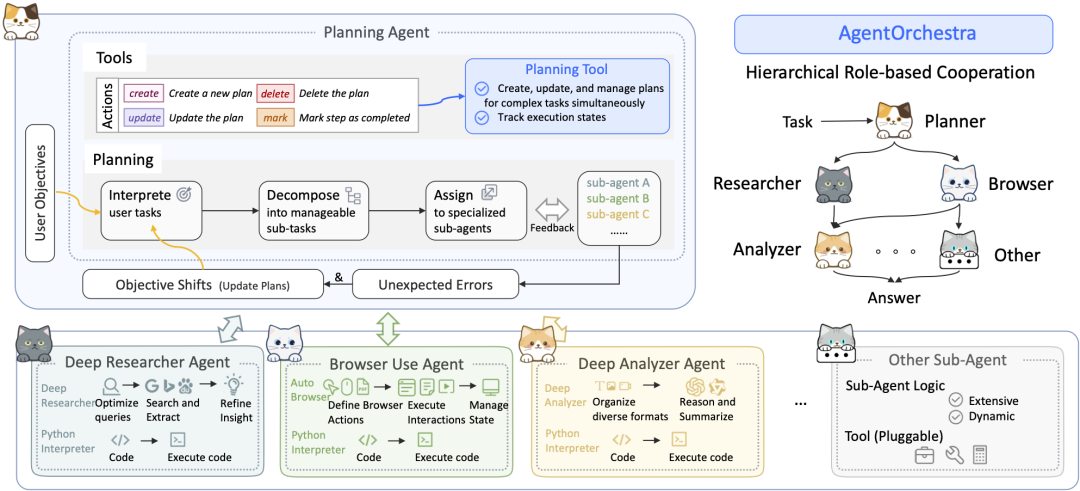
SkyworkAI 的 DeepResearchAgent 明示的な2層(Two-Layer)アーキテクチャが使用されており、これはソフトウェア工学において非常に古典的なデザインパターンであり、その中核をなすのは懸念の分離。
- コアアーキテクチャ:
- レイヤー1:トップレベルのプランニング・エージェント戦略レイヤー」または「ビジネスロジックレイヤー」として機能する。特定の調査タスクを実行する代わりに、ユーザーの意図を理解し、野心的な目標を管理可能な一連のサブタスクに分解し、ワークフロー計画を策定する役割を担う。
- 下級エージェント(専門下級エージェント):「実行層」や「サービス層」の役割を担う。情報分析の "ディープ・アナライザー"、ウェブ検索の "ディープ・リサーチャー"、ブラウザ操作の "ブラウザ・ユーザー "など、異なる専門性を持つ複数のインテリジェンスで構成される。「彼らは上位層から与えられたタスクを忠実に実行する。
- 建築インスピレーションプロジェクトは、その実施期間中に実施された。
READMEそのアーキテクチャーは、次のような制約を受けると明言している。smolagentsそれにインスパイアされ、モジュール式と非同期式の改良を加えて構築された。これはsmolagentsコンセプトのシンプルさと、より構造化されたマルチ・インテリジェント・ボディのコラボレーション・モデル。
コラムニストのコメント: DeepResearchAgent 2層のアーキテクチャは、"プランニング "と "実行 "を見事に分離している。設計はうまく構造化されており、スケーラブルである。将来的には、最上層のコア・プランニング・ロジックを変更することなく、より特殊化されたインテリジェンス(データの視覚化、コードの実行など)を第2層に追加することが容易になるだろう。これは実用的かつ工学的な実装である。
zhu-minjun/Researcher対立的自己批判メカニズム
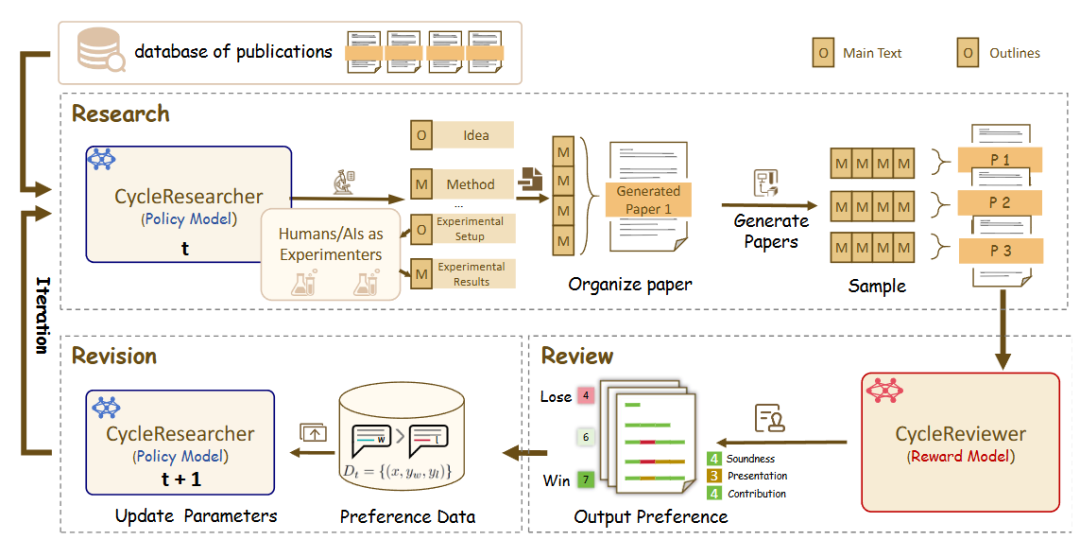
zhu-minjun/Researcher のアーキテクチャーは、同様に段階的なマルチインテリジェンス・コラボレーションであるが、その最も注目すべき特徴は、独立した、いわゆる対立的な「自己批判」セッション。
- コアアーキテクチャ:
- プランニング・インテリジェンス:: 研究プログラムとアウトラインの開発。
- 並列実行インテリジェンス:: サブテーマごとに独立した実行知能を立ち上げ、並行して情報を収集する。
- 統合と初稿作成:: すべての結果を初稿にまとめる。
- 批評と修正主義の知性: これがこの建築のハイライトだ。これは「リフレクション」を独立した「クリティカル・インテリジェンス」として可視化したものである。このインテリジェンスは厳格で懐疑的なレビュアーとして機能し、最初の草稿の品質に異議を唱え、あらかじめ定義されたルール(事実の正確さ、客観性、論理的連鎖の完全性、バイアスの有無など)に基づいて具体的かつ建設的な変更を提案する。そして、システムはこのフィードバックに基づいて修正を加え、反復最適化の閉じたループを作り出す。
- DeepReviewerその中で
Bestモードでは、プロジェクトはDeepReviewerモジュールは、この包括的な監査経験を達成するために、さらにシミュレーションすることができます。マルチ監査シミュレーションこれは、学術分野における査読(ピアレビュー)プロセスに似ている。
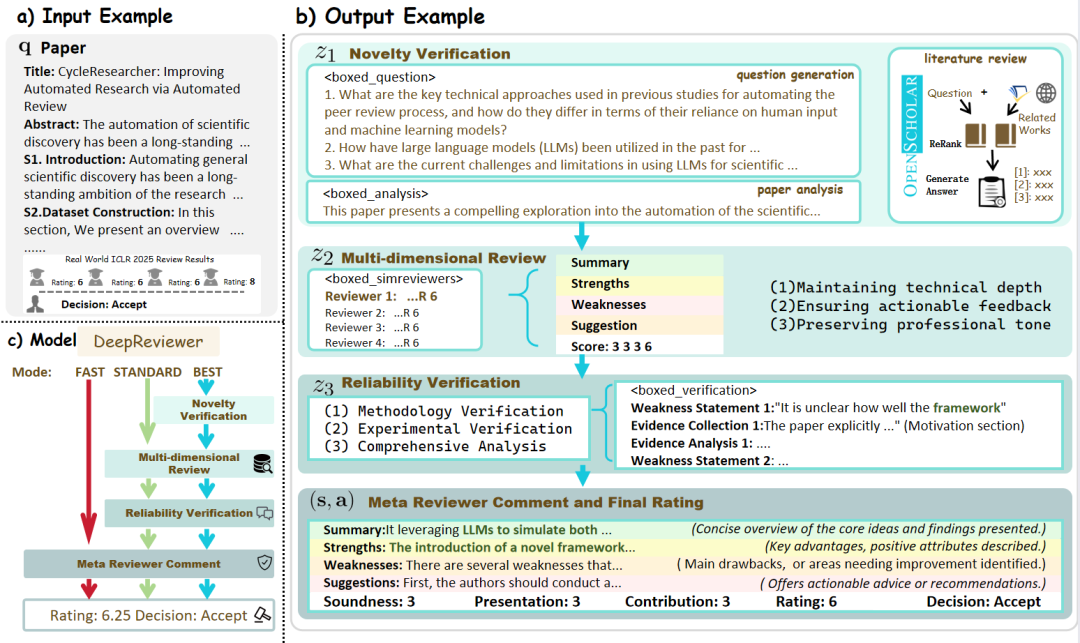
コラムニストのコメントこのプロジェクトは、"内省 "を内的な状態から、外的で構造化された対峙のプロセスへとアップグレードするものである。この "左右対称 "のデザインは、情報を集約するだけでなく、客観性と包括性を追求し、常にコンテンツの質を向上させることに挑戦する "研究者 "でもある。
商品化徹底調査 インテリジェント・ボディ・ウォッチ
開発者向けのオープンソース・フレームワークを分析した後、エンドユーザー向けの商用化されたアプリケーションは、よりシームレスで製品指向の体験を提供する。
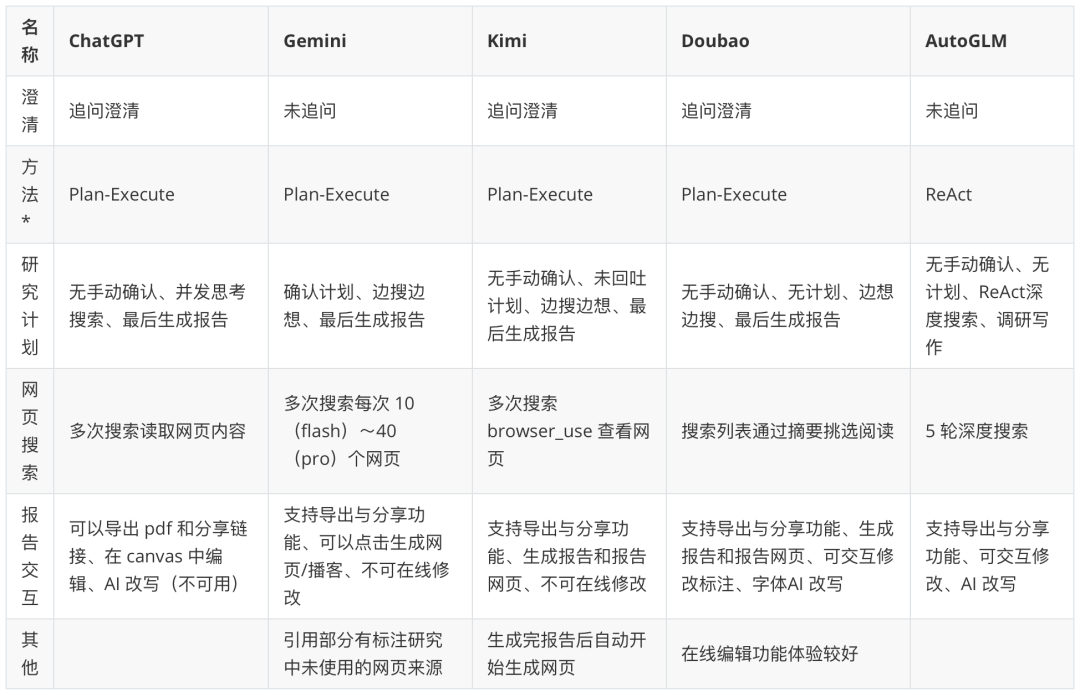
注:表中の「知的ボディ・パラダイム」は、製品行動に基づく推測である。インテリジェンスに関するより詳細な調査については、https://www.kdjingpai.com/ai-learning/research-assistant/。
オープンソースのフレームワークが「エンジン」を公開しているのに対し、商用製品は美しい「コックピット」の下に「エンジン」をエレガントに隠している。取る Kimi 一例として、ユーザーが裏側の計画、実行、合成ステップを気にすることなく、深い研究問題を扱うことができる。ユーザーは複雑な質問をしKimi 検索用語の計画、複数のウェブソースへの同時アクセス、数百万語の文脈ウィンドウを使用したリアルタイムでの情報の消化と統合、そして最終的に流動的なダイアログで引用ソースを含む包括的な回答を提示します。
その他の製品 ChatGPT、Gemini 等も通過している。 CoT (思考の連鎖)、Tree of Thoughts または内部的に統合されたマルチインテリジェンスプロセスにより、複雑なリサーチタスクを遂行する能力を継続的に向上させている。商用製品は、検索結果の正確さとリアルタイム性、情報統合の深さと洞察力、最終レポートのインタラクティブ性(クリック可能な引用、図表生成、フォローアップ提案など)で競争しています。オープンソースの世界の複雑なアーキテクチャーを、一般ユーザーの手の届く強力な機能にパッケージングしているのです。




























