

多くのユーザーが、重要なデータ(プレーン・イメージ・ファイルやスキャンしたPDF文書など)をLLMアプリケーション開発プラットフォームにアップロードしています。 Dify のナレッジ・ベースが、そのような問題を引き起こすことがよくある。Dify これらの非テキスト形式を直接読み込んで解析することはできない。これは主に Dify の知識ベース・ネイティブ機能は、プレーン・テキスト・データの処理と理解に重点を置いている。この制限を克服するために MinerU-API ツール Dify 知識ベースの強力な光学式文字認識(OCR)機能。次に、以下のようなワークフローを構築する方法について詳しく説明します。 Dify 知識ベースは、画像やスキャンした文書内のテキスト情報を効率的に解析することができます。このチュートリアルは Dify バージョン1.3.1。
事前準備
ワークフローの構築を開始する前に、2つの重要な準備が必要です。 MinerU-API 奉仕と創造 Dify 知識ベース。
MinerU-APIのデプロイ
MinerU-API は、複数フォーマットのドキュメント解析(OCRを含む)をサポートするツールです。その詳細な紹介とコードの取得手順については、関連記事「DifyでMinerUを使ってPDFを抽出する」と「MinerU-API|Difyの文書機能をさらに強化するためのマルチフォーマット解析のサポート」を参照してください。これは、ユーザーが MinerU-API コードとその簡単な説明 Docker 配備命令。
docker run -d --gpus all --network docker_ssrf_proxy_network --name mineru-api -v minerupaddleocr:/root/.paddleocr mineru-api:v0.3
このコマンドは、バックグラウンドで mineru-api 的 Docker コンテナを作成し、GPU リソースを割り当てます(利用可能な場合)。 PaddleOCR 関連データの
Difyナレッジベースの作成
第一に Dify プラットフォームに新しい知識ベースが作成される。この作成プロセスでは、機械による意味理解と類似度計算のためにテキストデータを高次元ベクトルに変換するEmbeddingモデルと、最終的な回答の精度と関連性を向上させるために初期検索結果の再ランク付けに使用されるRerankモデルを設定する。

図1: Dify知識ベース作成インターフェース
ナレッジベースが作成されたら、ブラウザのアドレスバーこのIDは、その後のAPIコールで重要なパラメーターとなる。

図2:ブラウザのアドレスバーから知識ベースIDを取得する
次にナレッジベース -> API 設定画面で新しいAPIキーを生成します。このキーは、ワークフローがナレッジベース上で実行する様々な操作の認証に使用されます。
図 3: Knowledge Base API キーの生成インターフェイス
MinerUナレッジベースワークフローの構築
ワークフローの概要
構築されたワークフローは、3つの主要なコード実行ノードで構成され、これらのノードが連携して画像やスキャン文書を解析し、ライブラリ化する。
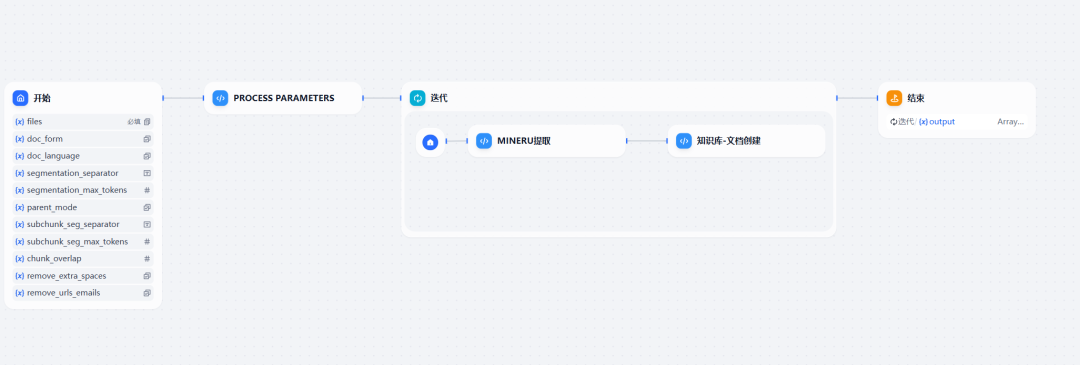
図4:MinerU知識ベースワークフローの概要
つのコードブロックのそれぞれの機能は以下の通り:
- Process Parametersこのノードは主に、次のような呼び出しを処理する。
Difyドキュメント・インターフェース (/datasets/{dataset_id}/document/create-by-text)が必要なパラメーターである。 - MinerUの抽出このノードの核となるタスクは
MinerU-API受信したPDFや画像ファイルを、OCR技術を使ってMarkdown形式のプレーンテキストコンテンツに変換するサービス。 - ナレッジベース - ドキュメント作成このノードは
Difyひらやね/datasets/{dataset_id}/document/create-by-textAPIインターフェースは、前のステップで定義されたMinerU抽出されたテキストコンテンツは、ナレッジベースに新しいドキュメントとして作成されます。以下はこのノードのサンプルPythonコードです:
import requests
def main(api_key, file_name, content, api_params, dataset_id):
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json',
}
# 更新API参数,加入文件名和提取的文本内容
api_params.update({
"name": file_name,
"text": content,
})
# 构建Dify API的请求URL
# 注意:实际部署时,'http://api:5001' 可能需要根据Dify服务的实际地址和端口进行调整
url = f'http://api:5001/v1/datasets/{dataset_id}/document/create-by-text'
response = requests.post(
url,
headers=headers,
json=api_params,
)
return {"result": response.text}
効果テスト
ワークフローの有効性を検証するために、ウェブページから直接印刷されたPDF文書を例にとって、直接アップロードされたPDF文書と比較してみましょう。 Dify 知識ベースは、新しく作成された MinerU ワークフロー処理の効果。
知識ベースを直接アップロードすることの効果:
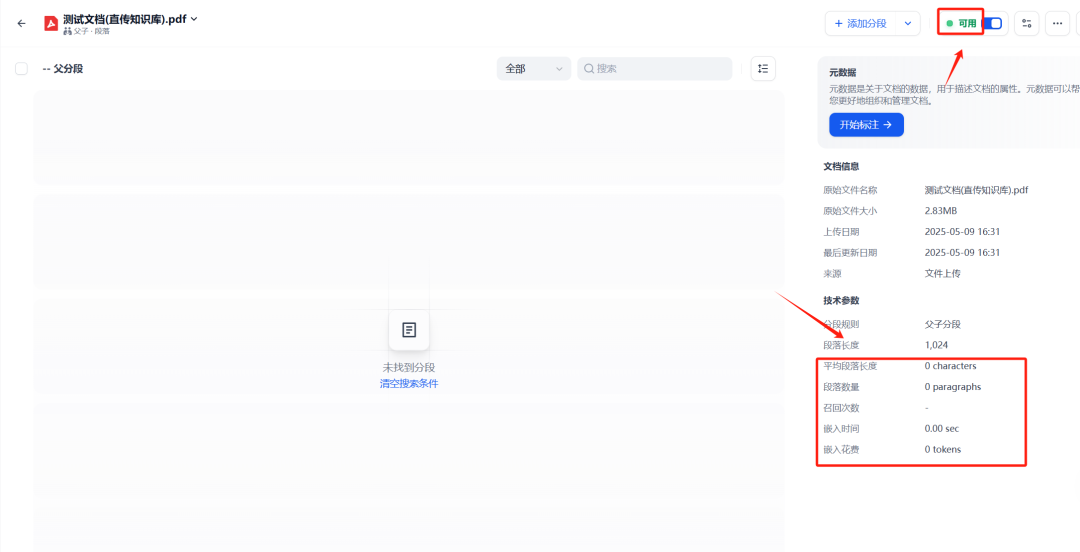
図5: DifyのナレッジベースにPDF文書を直接アップロードする。
上の画像からわかるように、ドキュメントは正常にアップロードされたにもかかわらず Dify ネイティブのナレッジベース機能では、スキャンしたPDFのテキストを解析することができず、ナレッジベースには事実上空白のドキュメントが残りました。
MinerUワークフローで文書を作成する効果:
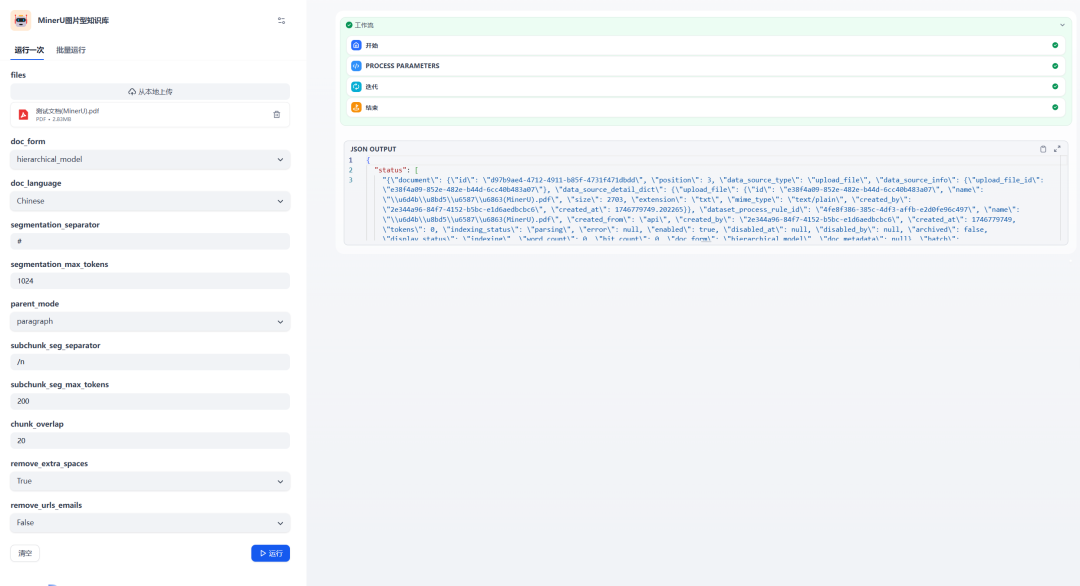
図6:MinerUワークフローによる処理と文書作成の実行結果
上のグラフは次のことを示している。MinerU ワークフローは正常に実行され、インターフェースの呼び出しは正常な結果を返しました。この時点で、Knowledge Baseにアクセスして新しく作成されたドキュメントを見ることができます。
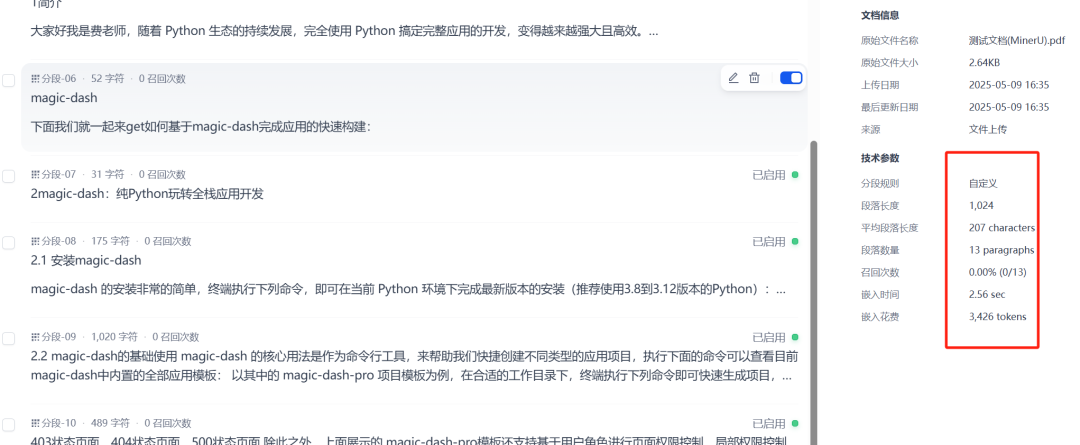
図7: MinerUワークフローによって作成されたドキュメントをDifyナレッジベースで見る
ワークフローを通してドキュメントが作成され、ナレッジベースにインポートされた後Dify インデックス作成のために自動的に処理される。索引付けが完了するのを待った後、知識ベースが画像中のテキストコンテンツに基づいて効果的なQ&Aや情報検索を実行できるかどうかをチェックするために、想起テストを実行することができる。
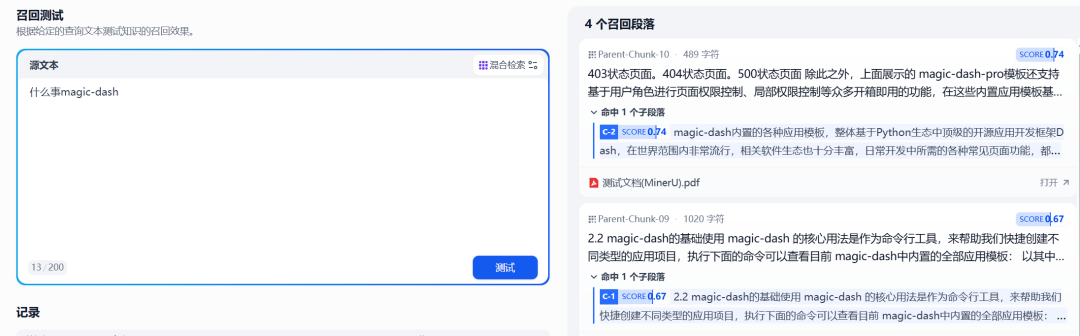
図8:MinerUによって処理され、保管された文書に対する回収テスト
テスト結果によると MinerU ワークフローで処理された文書で、抽出とインデックス作成に成功したテキストコンテンツを含むもの。 Dify 知識ベースは、元々画像フォーマット情報のために投げかけられたこれらの質問に基づいて理解し、回答することができた。これにより Dify 多様な文書タイプを扱う知識ベースの能力。

































