

Retrieval Augmented Generation (RAG)に基づく知識ベースアプリケーションを構築する際、ドキュメントの前処理とスライシング(チャンキング)は、最終的な検索結果を決定する重要なステップとなる。オープンソース RAG エンジン RAGFlow 様々なスライス戦略を提供するが、その公式ドキュメントにはメソッドの詳細や具体的なケースに関する明確な説明がないため、開発者に多くの混乱をもたらす。
この記事では、一連のベンチマークテストを通じて、以下の点を明らかにすることを目的とする。 RAGFlow の異なるスライシングメソッド間の動作メカニズムとコアの違い。テストは以下のような共通の質問を中心に行われる:
- 文書の章立て目次は、スライス時にどのように扱われますか?独立したブロックとして扱われるのでしょうか、それとも本文と統合されるのでしょうか?
- 本文中に埋め込まれた画像は、スライスされたときにどのように帰属されますか?
MANUAL、BOOK、LAWS等スライス法におけるスライスの具体的な根拠は?TABLE行単位でスライスする際に、テーブルのヘッダー情報が各行のデータに保持されるようにする方法は?QAスライス方法は可能か?TABLE代替の方法?
RAGFlow スライスの方法は、大きく以下のカテゴリーに分類される:
- 一般的なアプローチ
General)長さ+区切り文字」によるスライスは、広く適用可能だが、正確性に欠ける。 - 文書構造化メソッド (
MANUAL,BOOK,LAWS): 明確な階層構造を持つ文書(DOCXやPDFなど)を、目次や特定のタグに基づいてスライスします。 - テーブル構造化メソッド (
TABLE,QA): 表形式データ(XLSXなど)の場合、行単位または特定の列単位で処理。 - シーン別メソッド (
ONE,RESUME,PAPER,PRESENTATION)単一文書、履歴書、エッセイ、プレゼンテーションなどの特別な目的のために設計されています。
この分析では、最も一般的で混乱しやすい文書構造と表構造の方法に焦点を当てる。
文書構造によるスライス:MANUAL、BOOK、LAWS
3つの方法はいずれも構造化文書の処理に適しているが、そのスライス・ロジックと粒度は異なっている。視覚的に比較するため、明確な章立てを持つ「中華人民共和国徴税管理法.docx」をサンプルとして選んだ。
オリジナルの文書構造を以下に引用する:

手動方式:「タイトル」スタイルに基づく。
MANUAL このメソッドは、WordやPDFで定義された「見出し」スタイル(例:見出し1、見出し2)に従って文書を厳密に分割します。これは見出しレベルの最も細かい粒度までスライスします。注目すべきは、"スタイル "だけがテキストのタイトルとして認識され、通常の太字や拡大フォントのテキスト(例えば、"第15条"、"第16条")は本文として扱われます。
テスト・ドキュメントの使用法 MANUAL この方法によるスライス結果を以下に示す:

解析の結果、文書は合計6つの塊(チャンク)にスライスされていることがわかった。各チャンクは、文書のルートタイトルまでの親ディレクトリのタイトルをすべて継承します。例えば、「第2章:税務管理」のコンテンツブロックには、「中華人民共和国徴税管理法」と「第2章:税務管理」という見出しが含まれます。
トップレベル・ヘッダーの下に直接ボディ・コンテンツがある場合、これも別のブロックに切り分けられる。

BOOK手法:「カタログ+パラグラフ」に基づく
BOOK この方法は、より深いセマンティック・スライス戦略を採用している。まず章ごとの目次で分割し、さらに各章内の本文を意味論(サブトピックや段落)でスライスする。これにより BOOK この方法のスライス粒度は3つの中で最も細かい。
利用する BOOK メソッドは同じ文書を処理し、次のような結果を得る:
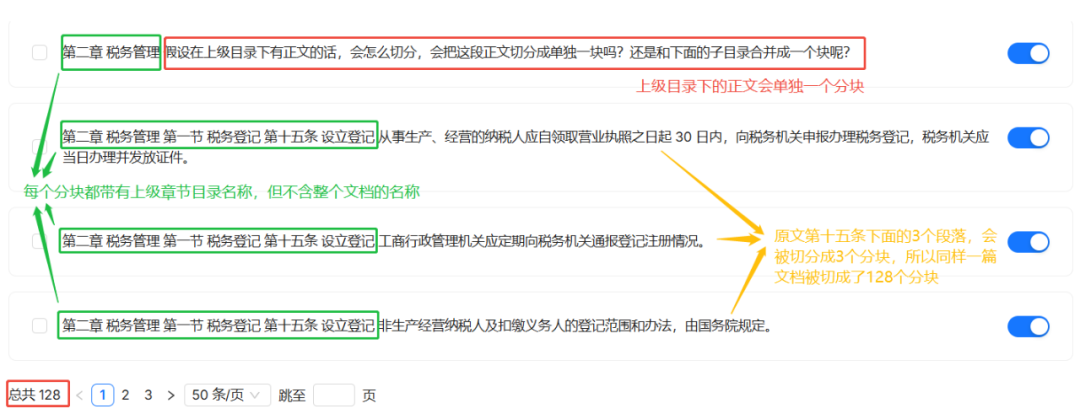
与 MANUAL 方法の違いの核心は、「第15条」以下の3つのパラグラフを3つの別々の塊に細かくスライスしていることだ。最終的には文書全体が128の塊に切り分けられた。
文脈継承の文脈ではBOOK メソッドの各ブロックも同様に、親ディレクトリのタイトルを含むが、これは MANUAL これとは異なり、文書のトップレベルの見出しは含まれていない。このデザインは、文書全体の文脈よりも、特定のセクションの内容に焦点を当てた検索に適しているかもしれません。
LAWSの方法論:「セクション条項」のラベリングに基づく
LAWS メソッドは法律や規制の文書用に設計されており、正規表現を使って「第X章」「第X条」などの特定のトークンを識別し、テキストの「タイトル」スタイルや目次レベルを無視してスライスします。やテキストの目次レベルは無視されます。
利用する LAWS メソッドはドキュメントを処理し、結果を87のチャンクにスライスする。

LAWS 方法論の特徴は以下の通りである:
- 識別子:: "Article 15 "と "Article 16 "は文書の中では通常のボディ・スタイルであるにもかかわらず、"Article "のマークアップと一致するため、うまくカットされる。
- パラグラフィを持つ。
BOOK違う。LAWS記事の下にある複数の段落の再スライスはなく、同じブロックにまとめられる。 - 文脈化:
LAWSコンテキストの扱いが非常にユニークだ。親カタログの見出しを各記事ブロックに直接埋め込むのではなく、各レベルのカタログ見出しを別のブロックに集約し(上図の緑色のワイヤーフレームで示すように)、カタログインデックスとコンテンツの分離を実現している。
3つの文書スライス方法の比較概要
以上のテストに基づき、3つの方法の特徴をまとめると以下のようになる:
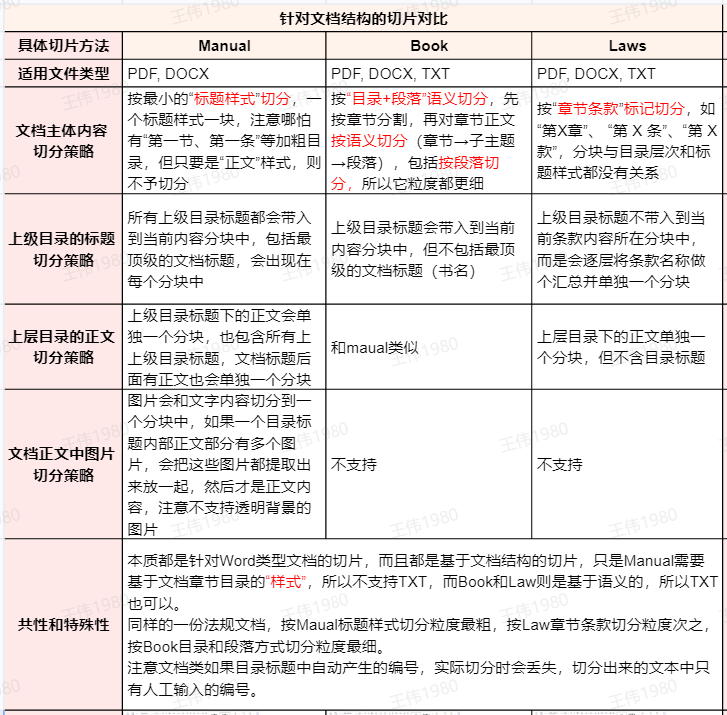
さらに付け加えておきたいことがある。MANUAL つまり、製品マニュアルや技術文書など、標準的な「タイトル」スタイルの階層を持つ文書である。そして LAWS 法律、規制、政策文書を専門とする。BOOK 一方、段落レベルでのきめ細かなセグメンテーションが可能なため、深い意味理解やQ&Aが必要な長いレポートや書籍に適している。
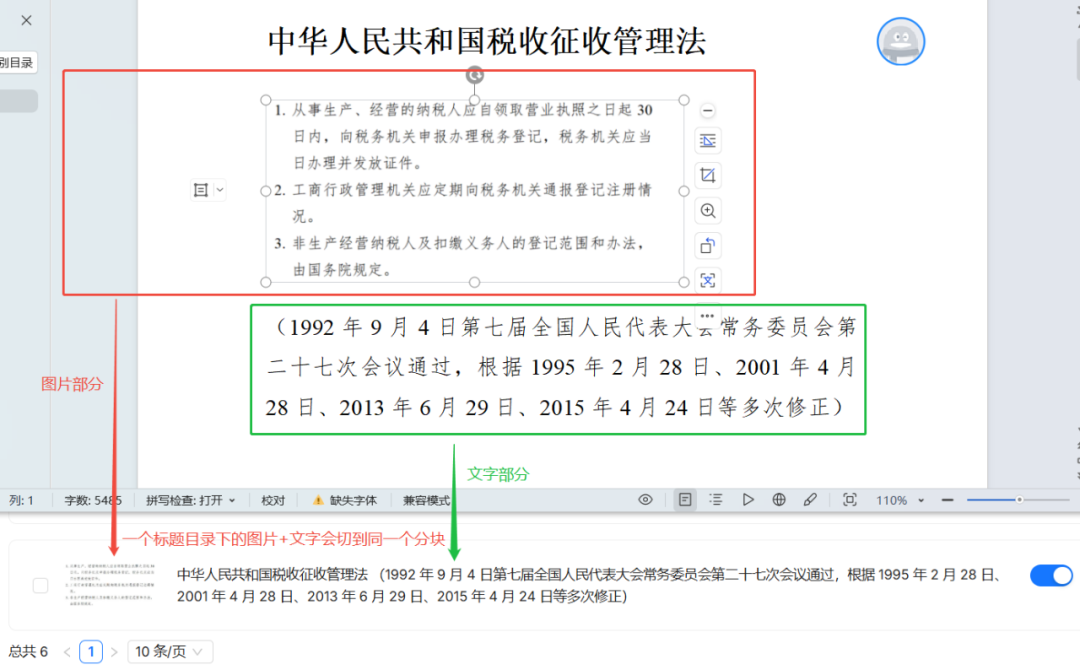
さらに、このテストでは以下のことが判明した。 MANUAL メソッドは、画像とそれに隣接するテキストコンテンツを同じブロックにカットして文書化することができ、グラフィック文書処理に非常に便利である。
テーブル構造によるスライス:TABLE、QA
次に、Excelファイルのような表のようなデータでスライス方法を検証する。
テーブル方式
このテストでは、製品、地域、ビジネス・ドメイン、問題の説明、原因、解決策のフィールドを含むO&M知識フォームを使用する。
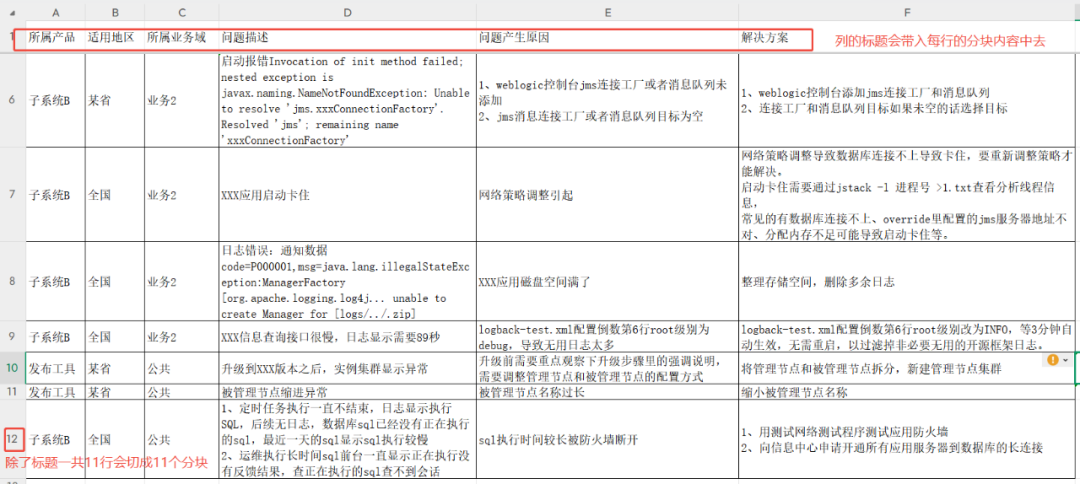
利用する TABLE メソッドでスライスする場合RAGFlow テーブルの最初の行はカラムヘッダとして認識される。処理されると、行をスライスし(ヘッダー行を除く)、各行のコンテンツ・ブロックにカラム・ヘッダーの情報全体を追加し、"Key: Value "形式を形成する。
スライシングの結果は以下のようになり、各行が完全な文脈情報を持つ独立した知識の塊となる:

QA手法
QA このメソッドは、フォームの最初の2列をデフォルトで「質問」と「回答」として認識する特別な目的のフォームスライスです。以前のO&M知識フォームがテストに直接使用される場合。RAGFlow 製品」と「地域」の列のみが抽出され、それ以外の情報は無視されます。
正確なテストを行うために、私たちは「問題の説明」と「解決策」の2つの欄だけを設けた標準的なQAフォーマットのフォームを用意する。
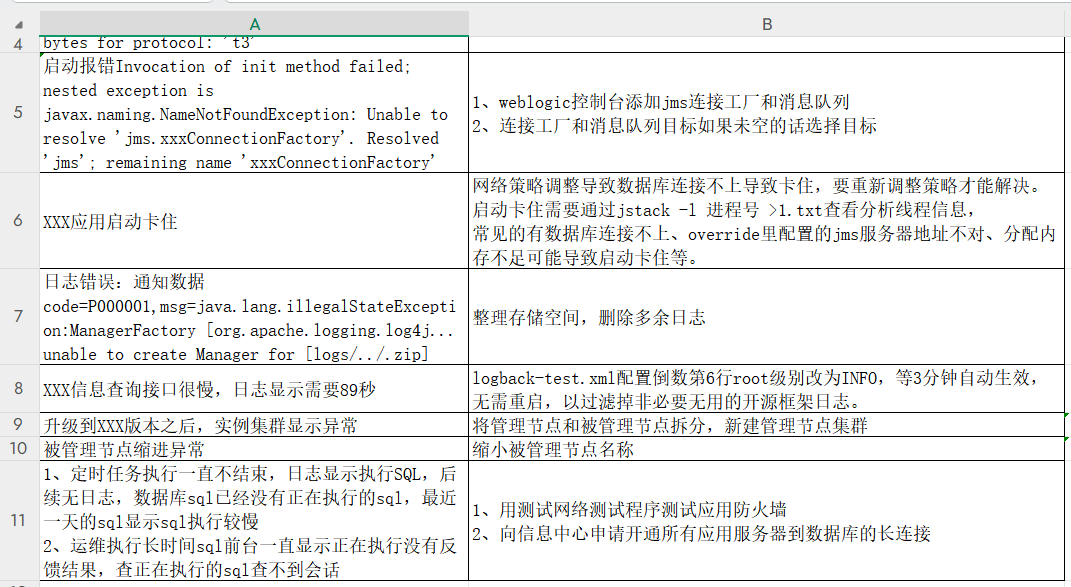
通る QA メソッドがスライスされた後、各行もブロックにスライスされ、自動的に "Question: "と "Answer: "が先頭に付く。
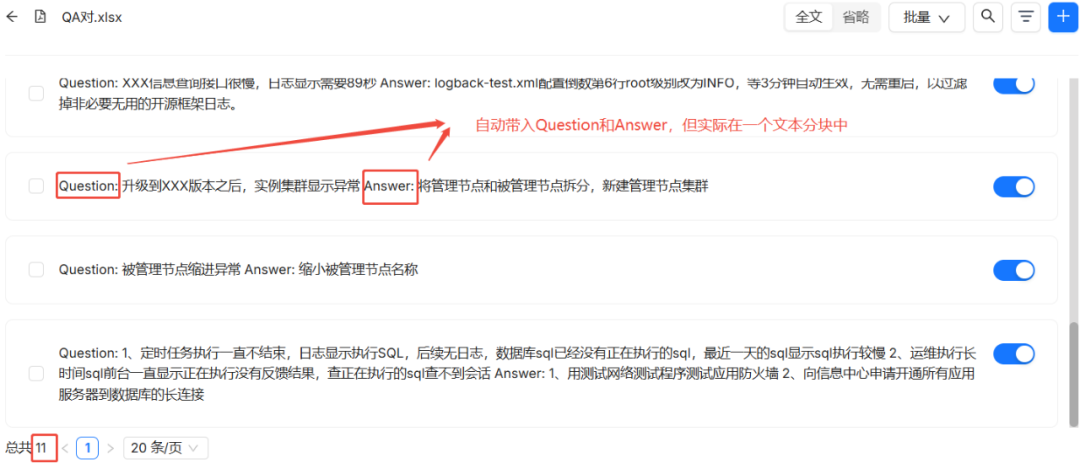
2つのテーブル・スライス法の比較まとめ
さらに詳しく分析するとQA 方法は基本的に TABLE このメソッドの簡略化された特殊ケース。ユーザーは TABLE メソッドの実装 QA この表の効果は、単に2つの列に「質問」と「回答」という名前をつけただけである。
実用的なアプリケーションでは、知識ベースが問題の説明、原因、解決策などの多次元情報に基づく意味検索を必要とする場合。TABLE このアプローチが望ましい。検索シナリオが厳密に「質問と答え」のペアに限定され、正確なフィルタリングのために製品、地域などの情報を使用したい場合、より良いアーキテクチャは QA この方法は、Q&Aコンテンツをスライスし、また商品、地域などの情報をブロックのメタデータ(Metadata)に保存する。
しかし RAGFlow 我々のテストでは、このシステムはメタデータをDocumentレベルでのみサポートし、より細かいChunkレベルではサポートしないように設計されていることがわかった。また、その検索APIにはメタデータベースのフィルタリングのための直接的なパラメータが欠けているようだ。これは、複雑なRAGシステムを構築する際の重要な制限であり、チームを独自の知識ベースの構築を検討させた理由の一つである。
その他の特殊なスライス方法
RAGFlow シナリオに特化したスライス方法も数多く提供されている:
- Oneスライスは行わず、文書全体を一つのブロックとして扱う。
- Resume履歴書を構造的に解析し、重要な情報を抽出する。
- Paper抄録、著者、章などを抽出し、論文形式にする。
- PresentationPPTまたはPPTから変換されたPDFの場合、各ページをページのスクリーンショットと抽出されたテキストコンテンツを含む個別のブロックに変換します。
PRESENTATION 試験結果は以下の通り:
スライシングを超えて:RAGエンジニアリングのための詳細な考察
(躊躇なく RAGFlow 豊富なスライスツールは提供されるが、プロダクショングレードのRAGシステムはそれ以上のものである。社内ナレッジ・ベース・ソリューションの選択は、通常、より深いエンジニアリングのニーズに基づいています:
- カスタム・スライス・ロジックビジネス・シナリオでは、コード・リポジトリ、データ辞書、特定フォーマットの内部知識など、高度にカスタマイズされたスライシング・ルールが必要になることが多く、オンプレミスのアプローチでは対応することが困難です。
- きめ細かなメタデータ管理前述したように、豊富なメタデータ(バージョン、ソース、担当者、ビジネスタグなど)を各知識ブロックに付加し、効率的なフィルタリングをサポートすることは、正確な検索を可能にし、範囲を絞り込み、効率を向上させる中核となる。
- ナレッジベースのバージョン管理とライフサイクル管理本番環境のナレッジベースには、確立されたワークフローが必要です。ナレッジが追加または更新された場合、最終的に安全にリリースされる前に、それがオンラインサービスの安定性と正確性に影響を与えないことを確認するために、テストと検証が行われなければなりません。
- 知識の洗練と強化RAGシステムはまた、元の知識を処理する必要がある。例えば、要約の生成、知識グラフの関係の構築、同義語の拡張の追加など。
これらの複雑な工学的課題は、基本的なRAGプロトタイプから、信頼性が高く保守可能なエンタープライズクラスのナレッジサービスへの道筋を形成している。


































