



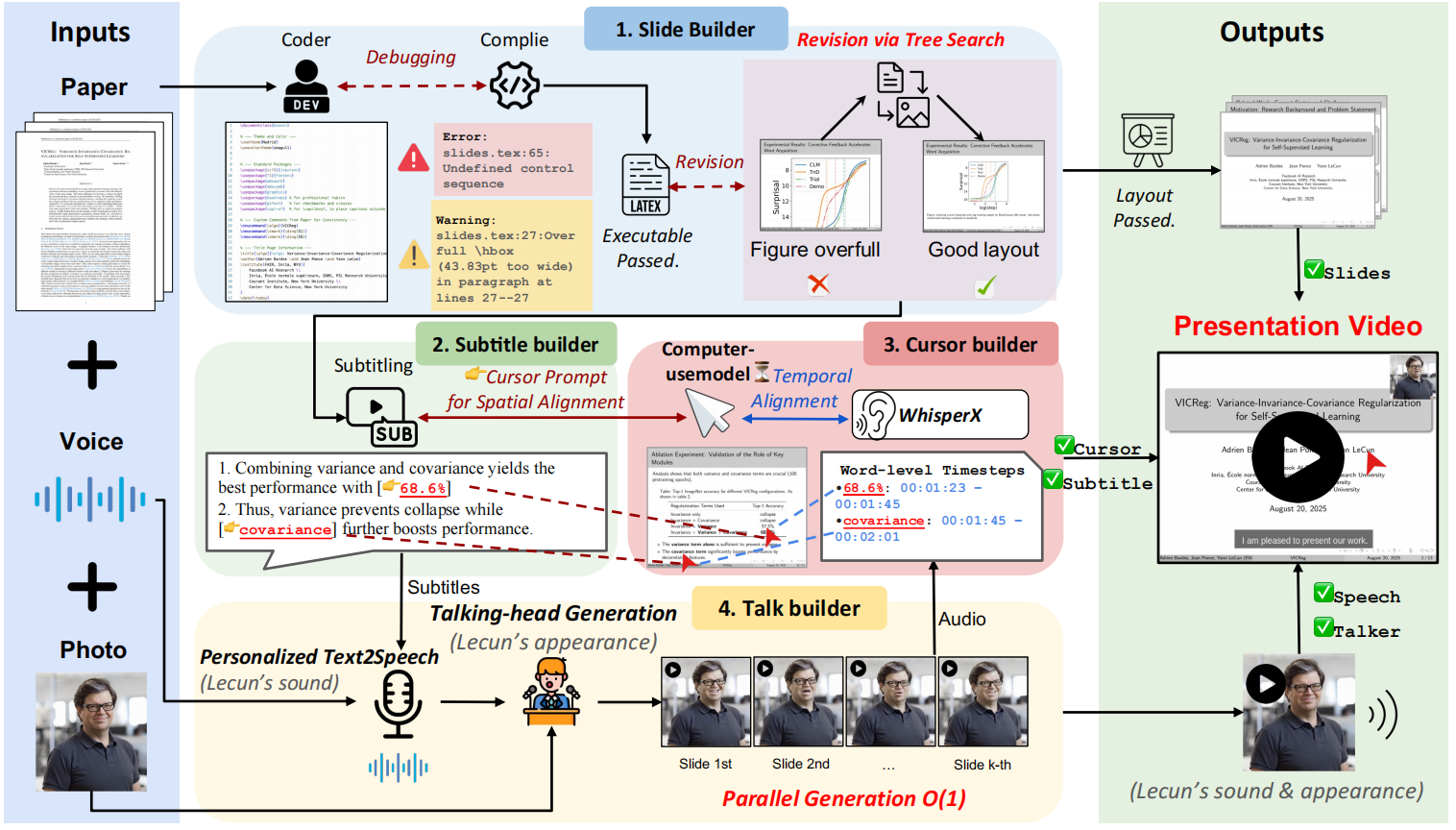
Paper2Videoは、学術プレゼンテーションのビデオを準備する煩雑さから研究者を解放することを目的としたオープンソースプロジェクトである。 PaperTalkerと呼ばれるマルチ・インテリジェンス・フレームワークは、LaTeXで書かれた論文、スピーカーの参考写真、参考音声を受け取り、完全自動でプレゼンテーションのビデオを生成する。 PaperTalkerは、コンテンツの抽出から、スライド(Slides)の作成、字幕の生成、音声合成、マウスの追跡、バーチャル・デジタル・ヒューマン・レクチャー・ビデオのレンダリングまでの全プロセスを自動化する。 また、生成されたビデオの品質を科学的に評価するために、101の論文と対応する著者の講演ビデオを含むPaper2Videoと呼ばれるベンチマークを提案し、ビデオが論文の情報を正確に伝えることができるかどうかを測定するためのいくつかの評価次元を設計している。
機能一覧
- マルチインテリジェンス・コラボレーションスライドジェネレーターや字幕ジェネレーターなど、複数のインテリジェンスを駆使して作業を分担し、複雑な映像生成タスクをこなす。
- スライドの自動生成LaTeXの論文ソースコードからコアコンテンツを直接抽出し、プレゼンテーション用のスライドを自動生成し、コンパイルフィードバックによってレイアウトを最適化します。
- 音声・字幕合成スライドの内容に基づいて対応するプレゼンテーションを生成し、テキスト音声合成(TTS)技術を使って音声を合成し、正確にタイムスタンプを揃えた字幕を生成します。
- マウストラック・シミュレーションプレゼンテーションの内容やスライド要素を分析し、実際の人の動きを模倣したマウスの動きやクリックの軌跡を自動的に生成。
- バーチャル・デジタル・パーソン世代スピーカーの正面写真があれば、バーチャルなデジタル人物(トーキングヘッド)を生成し、映像の中でしゃべることができる。
- 並列処理各スライドページに関連する生成タスク(音声、マウストラックなど)を並列処理し、動画生成の効率を飛躍的に向上。
- つの世代モードVMを使用するフルモードとVMを使用しない高速モードがあり、ユーザーは必要に応じて選択することができます。
ヘルプの使用
Paper2Videoは、LaTeX形式の論文プロジェクト、講演者の画像、音声サンプルを、完全な学術講演ビデオに合成する自動化されたパイプラインを提供します。
1.環境準備
始める前に、プロジェクトを実行するための環境を準備する必要がある。パッケージのバージョンの衝突を避けるために、Condaを使って別のPython環境を作ることを推奨する。
プライマリ環境のインストール:
まず、プロジェクトのコードをクローンして src ディレクトリに移動し、Conda環境を作成し、有効化する。
git clone https://github.com/showlab/Paper2Video.git
cd Paper2Video/src
conda create -n p2v python=3.10
conda activate p2v
次に、必要なPython依存ライブラリとLaTeXコンパイラをインストールします。 tectonic。
pip install -r requirements.txt
conda install -c conda-forge tectonic
バーチャルデジモン環境のインストール(オプション):
バーチャルデジタイザープレゼンテーションのビデオを生成する必要がない場合(クイックバージョンを実行する場合)は、このステップをスキップすることができます。バーチャルデジタイザー機能の依存関係 Hallo2 プロジェクト用に別の環境を作成する必要がある。
# 在 Paper2Video 项目根目录下
git clone https://github.com/fudan-generative-vision/hallo2.git
cd hallo2
conda create -n hallo python=3.10
conda activate hallo
pip install -r requirements.txt
インストールが完了したら、次のことをメモしておく必要がある。 hallo Pythonインタープリターへのパス。以下のコマンドでパスを見つけることができます:
which python
2.大規模言語モデル(LLM)の設定
Paper2Videoのコンテンツを理解し生成する能力は、強力な大規模言語モデルに依存しています。APIキーを設定する必要があります。プロジェクトでは GPT-4.1 或 Gemini 2.5-Proが最良の結果をもたらす。
APIキーをターミナルで環境変数としてエクスポートする:
export GEMINI_API_KEY="你的Gemini密钥"
export OPENAI_API_KEY="你的OpenAI密钥"
3.ビデオ生成の実装
Paper2Videoは主に2つの実行スクリプトを提供します:pipeline_light.py バーチャルデジタルマンなしで)迅速な生成のために。pipeline.py バーチャルなデジタル人物を含むビデオの完全版を生成するために使用する。
最小ハードウェア要件このプロセスを実行するには、少なくとも48GBのビデオメモリを搭載したNVIDIA A6000 GPUを推奨します。
ファストモード(バーチャルデジタルマンなし)
このモードは、バーチャルなデジタル人物をレンダリングするという時間のかかるステップを省き、ナレーション、字幕、マウストラック付きのスライドショー・ビデオを素早く生成します。
以下のコマンドを実行する:
python pipeline_light.py \
--model_name_t gpt-4.1 \
--model_name_v gpt-4.1 \
--result_dir /path/to/output \
--paper_latex_root /path/to/latex_proj \
--ref_img /path/to/ref_img.png \
--ref_audio /path/to/ref_audio.wav \
--gpu_list [0,1,2,3,4,5,6,7]
フルモード(バーチャルデジタルパーソン付き)
このモードは、スピーカーの画面を使って完全なビデオを生成するためのすべてのステップを実行します。
以下のコマンドを実行する:
python pipeline.py \
--model_name_t gpt-4.1 \
--model_name_v gpt-4.1 \
--model_name_talking hallo2 \
--result_dir /path/to/output \
--paper_latex_root /path/to/latex_proj \
--ref_img /path/to/ref_img.png \
--ref_audio /path/to/ref_audio.wav \
--talking_head_env /path/to/hallo2_env \
--gpu_list [0,1,2,3,4,5,6,7]
パラメータの説明
model_name_tテキストタスクの処理に使われる大規模言語モデルの名前。gpt-4.1。result_dir生成されたスライドやビデオなどの出力結果を保存します。paper_latex_rootLaTeX論文プロジェクトのルート・ディレクトリ。ref_img正方形の顔写真であること。ref_audioクローン音色の基準となるスピーカーの音声は、10秒程度のサンプルを推奨します。talking_head_env(フルモードのみ必要) 以前にインストールされたものhalloあなたの環境にあったPythonインタプリタへのパス。gpu_list並列コンピューティングに使用されるGPUデバイスのリスト。
実行の最後に result_dir ディレクトリで、すべての中間ファイルと最終的に生成されたビデオを見つける。
アプリケーションシナリオ
- 学会報告
研究者はPaper2Videoを使用することで、論文を素早くビデオプレゼンテーションに変換し、オンライン会議で共有したり、学会に投稿したりすることができます。これにより、手作業でスライドを作成し、ビデオを録画する時間を大幅に節約できます。 - 研究成果の普及
複雑な学位論文の内容をわかりやすく動画にし、ソーシャルメディアや動画プラットフォームに投稿することで、研究成果がより多くの人に届き、学術的な影響力を高めることができます。 - 教育・カリキュラム教材
教員や研究者は、古典的な学術論文や最新の学術論文を指導用ビデオに変換し、学生が最先端の科学をより直感的に理解できるようにするための教材として使用することができる。 - 論文の事前発表とリハーサル
正式な弁護やオフラインでの報告を行う前に、作成者はツールを使ってプレビュービデオを作成し、最適化と反復のためにレポートの論理的な流れ、タイムコントロール、ビジュアルをチェックすることができます。
QA
- このプロジェクトはどのような核心的問題に取り組んでいるのか?
このプロジェクトは、時間と労力を要する学術講義ビデオ制作の問題を解決することに焦点を当てている。伝統的に、研究者はスライドのデザイン、講義の執筆、録画、編集に多くの時間を費やしている。paper2Videoは、自動化することで、研究者をこの退屈な作業から解放することを目指している。 - ビデオを生成するには、どのような入力ファイルを準備する必要がありますか?
用意するものは3つ:LaTeX形式で書かれた完全な論文プロジェクト、スピーカーの正方形の正面写真、スピーカーの10秒程度の参考録音。 - ハードウェアの要件についてよく知らないのですが、私の普通のコンピューターで動きますか?
このプロジェクトのハードウェア要件は、特にGPUが非常に高い。公式には、少なくとも48GBのビデオメモリを搭載したNVIDIA A6000 GPUを使用することを推奨している。普通のPCやラップトップでは、完全な生成プロセス、特に仮想デジタル人物のレンダリングを含む部分を実行できない可能性が高い。 - ビデオに顔を映したくない場合、このツールを使うことはできますか?
できる。このプロジェクトはpipeline_light.pyスクリプトを実行すると、すべてのコア要素(スライド、ボイスオーバー、字幕、マウストラック)を含むビデオを生成する高速モードが実行されますが、仮想デジタルパーソンの画面は含まれません。このモードも、比較的低い計算リソースで動作します。






























