



OCRFluxは、明確なMarkdown形式にPDFファイルや画像を変換することに焦点を当てたオープンソースの軽量ツールです。それはChatDOCチームによって開発され、大規模の構築のマルチモーダルモデルの3Bパラメータに基づいて、GTX 3090などの通常のハードウェア上で実行することができます。このツールは、複雑なドキュメントレイアウトを処理するのが得意で、正確に複数列のフォーマット、複雑なテーブルを解析し、ページ間のコンテンツの自動マージをサポートしています。他のオープンソースOCRモデルと比較して、OCRFluxは、特に表と段落処理の精度に優れています。それは、使いやすいコマンドライン操作を提供し、開発者、研究者やMarkdown形式にドキュメントを変換する必要があるユーザーに適しています。このプロジェクトは、Apache 2.0ライセンスの下、GitHub上でオープンソースとして公開されており、活発なコミュニティと1.7kのスターがあります。
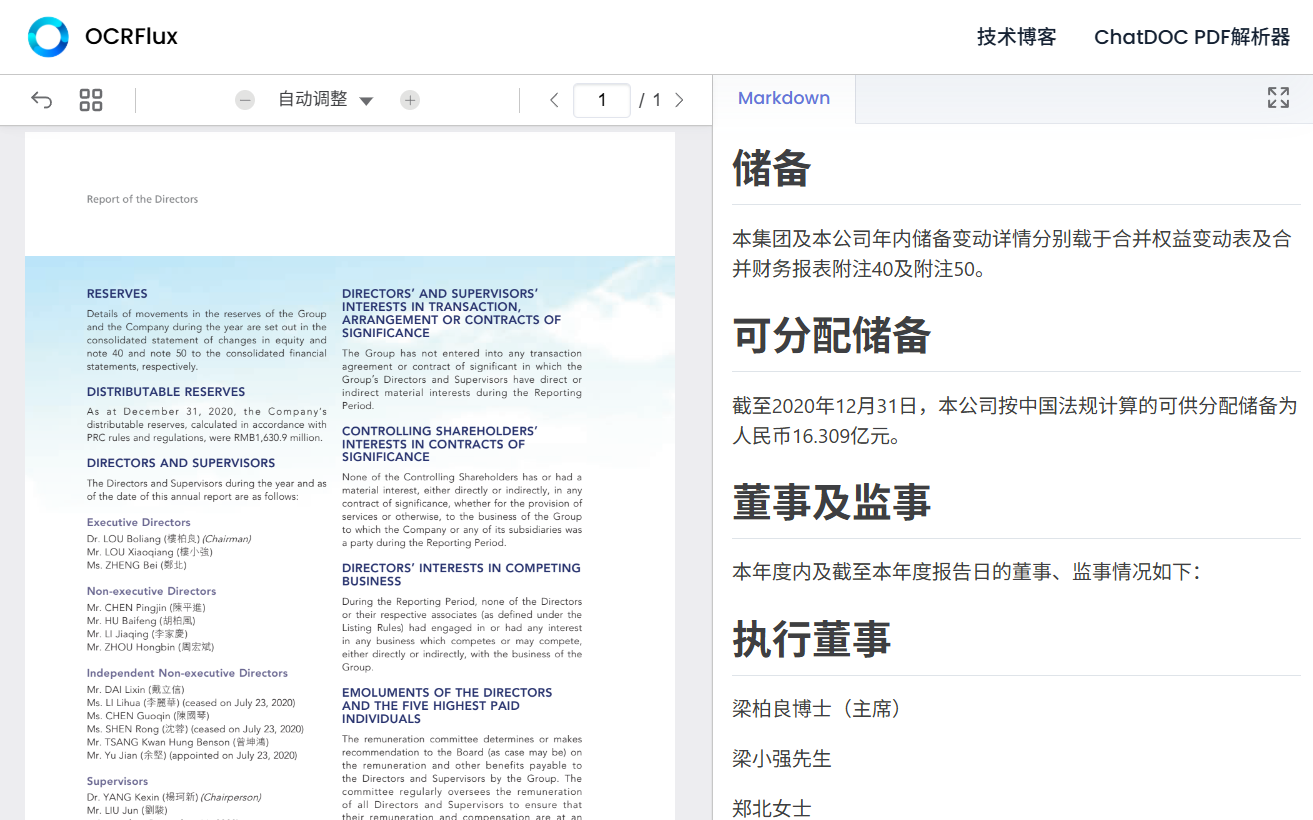
機能一覧
- PDFや画像を、自然な読み順を保ったままMarkdown形式に変換。
- マルチカラム文書、イラスト、埋め込みコンテンツなど、複雑なレイアウト処理をサポート。
- 複雑なテーブルを自動的に解析し、rowspanとcolspanのHTMLテーブル出力をサポートします。
- ページをまたいだ表や段落を自動的に検出して統合する、クロスページ・コンテンツ・マージング。
- 最大0.967の編集距離類似度(EDS)で高精度のテキスト認識を提供します。
- 通常のGPU動作と互換性のある3Bパラメトリック・マルチモーダルモデルに基づく。
- オープンソースで無料、コードとドキュメントはGitHubで公開されており、コミュニティによる貢献もサポートされている。
ヘルプの使用
設置プロセス
OCRFluxはDockerベースのツールで、インストールと実行にはDocker環境が必要です。以下は詳細なインストール手順です:
- Dockerのインストール
Dockerがシステムにインストールされていることを確認する。インストールされていない場合は、Dockerのウェブサイトにアクセスし、オペレーティング・システムに適したバージョンをダウンロードしてインストールする。インストールが完了したら、以下のコマンドを実行して確認する:docker --version
- OCRFluxミラーを引く
ターミナルで以下のコマンドを実行し、Docker Hubから最新のOCRFluxイメージを取り出します:docker pull chatdoc/ocrflux:latest - ファイルパスの準備
ローカル作業ディレクトリを作成する(例えば/path/to/localworkspace)は入力ファイルと出力ファイルの保存に使用されます。以下のディレクトリがあることを確認してください:- PDFファイルのディレクトリを入力します。
/path/to/test_pdf_dir)。 - OCRFlux モデルファイルディレクトリ (例.
/path/to/OCRFlux-3B).モデルファイルは公式のGitHubリポジトリか、ChatDOCが提供するリンクからダウンロードしてください。
- PDFファイルのディレクトリを入力します。
- OCRFluxの実行
以下のコマンドを使用して、OCRFlux コンテナを起動し、ローカルディレクトリをマウントし、入力 PDF とモデルのパスを指定します:docker run -it --gpus all \ -v /path/to/localworkspace:/localworkspace \ -v /path/to/test_pdf_dir:/test_pdf_dir \ -v /path/to/OCRFlux-3B:/OCRFlux-3B \ chatdoc/ocrflux:latest /localworkspace --data /test_pdf_dir/* --model /OCRFlux-3B/--gpus allGPU アクセラレーションを有効にします(GPU がない場合はこのパラメータを外します)。-vローカルディレクトリをコンテナにマウントする。--data入力PDFファイルのパスを指定します。--modelモデルファイルのパスを指定します。
- Markdownファイルの生成
実行が完了すると、Markdown出力ファイルは./localworkspace/markdowns/DOCUMENT_NAMEディレクトリに移動します。以下のコマンドを使用して、JSONLフォーマットをMarkdownに変換する:python -m ocrflux.jsonl_to_markdown ./localworkspace
使用プロセス
OCRFluxのコア機能は、PDFまたは画像をMarkdownに変換することです:
- 入力ファイルの準備
変換したいPDFファイルまたは画像を/path/to/test_pdf_dirカタログ。一般的なPDFフォーマットと画像フォーマット(PNG、JPGなど)をサポート。 - 変換タスクを実行する
ocRFluxは自動的にドキュメントのレイアウトを分析し、テキスト、表、ページ間のコンテンツを識別します。ファイルサイズやハードウェアのパフォーマンスによっては、変換処理に数分かかる場合があります。 - 出力のチェック
変換が完了したら./localworkspace/markdowns/DOCUMENT_NAME生成されたMarkdownファイルを見るにはカタログをご覧ください。ファイルはドキュメントの自然な読み順を保持し、表はMarkdownまたはHTML形式で表示されます。 - 複雑なフォームの処理
OCRFluxはrowspanとcolspanを含む複雑な表を扱うことができます。結果として得られるMarkdownファイルは、テーブルを直接編集したり、他のツールにインポートしたりするのに適した明確なフォーマットに構造化します。 - クロス・ページ・コンテンツのマージ
ページにまたがる表や段落は、OCRFlux が自動的に検出して結合します。例えば、2ページにまたがる表は1つの完全な表に統合され、段落は論理的な順序でつなぎ合わされます。
注目の機能操作
- 複雑なレイアウト処理OCRFlux は、複数カラムの文書や埋め込みイラストの解析をサポートします。実行時に追加の設定は必要なく、ツールは自動的に文書構造を認識します。
- 高精度の認識OCRFlux-bench-singleテストでは、EDSスコア0.967を達成し、olmOCR-7B(0.872)、Nanonets-OCR-s(0.858)、MonkeyOCR(0.780)を上回った。
- クロスページ・マージこれはOCRFluxのユニークな機能です。このツールは、連続するページを分析し、マージが必要な表や段落を検出し、完全なコンテンツを出力します。
ほら
- 入力されたPDFファイルが判読可能であり、スキャンの推奨解像度が300DPI以上であることを確認してください。
- GPUが使用できない場合、変換に時間がかかる可能性があり、高性能のCPUを推奨します。
- モデルファイルの整合性をチェックしてください。ファイルが見つからない場合、変換に失敗する可能性があります。
- GitHubリポジトリに定期的にアクセスし、最新バージョンとアップデート方法を確認してください。
アプリケーションシナリオ
- 学術研究
OCRFluxは、複数カラムのレイアウトや複雑な表を処理し、数式や参考文献の明確な書式設定を保証します。 - 技術文書
開発者は、技術マニュアルやAPIドキュメントをPDFからMarkdownに変換し、ナレッジベースやブログにインポートすることができます。断片化を避けるためにページ間でマージします。 - インボイスとフォームの処理
財務担当者は、請求書や帳票のPDFをMarkdownに変換し、購入者、単価、価格/税合計などの重要な情報を抽出して、簡単にデータ分析を行うことができます。 - コンテンツクリエーター
クリエイターは、スキャンした本やメモをMarkdown Jellybeanフォーマットに変換し、ウェブサイトや文書で直接使用するのに適した、公開可能なMarkdownファイルに整理することができます。
QA
- OCRFluxはどのようなファイル形式をサポートしていますか?
PDFや一般的な画像形式(PNG、JPGなど)をサポートしています。入力ファイルは、鮮明な文書またはスキャンである必要があります。 - 高性能ハードウェアが必要ですか?
OCRFluxは3Bパラメトリックモデルに基づいており、通常のGPU(GTX 3090など)または高性能CPUで実行できます。 - ページをまたぐフォームはどのように扱えばよいですか?
OCRFluxは、ページ間の表や段落を自動的に検出し、手作業なしで完全なMarkdownフォーマットを出力するためにそれらをマージします。 - 変換結果が不正確だったら?
入力ファイルの解像度を確認してください(300DPI以上を推奨)。それでも問題が解決しない場合は、GitHubにissueを投稿してコミュニティの助けを求めてください。 - 操作にはネットワークが必要ですか?
OCRFluxはローカルのDocker環境で実行され、モデルとデータはオフラインで処理されます。































