



MedGemmaは、GoogleがHugging Faceプラットフォーム上で公開したオープンソースのAIモデル群で、医療分野におけるテキストと画像の理解に焦点を当てている。ベースとなっているのは Gemma 3 MedGemmaは、4Bパラメータのマルチモーダルモデルや27Bパラメータのテキスト&マルチモーダルモデルなど、複数のモデルバリエーションを提供しています。これらのモデルは、医療テキスト、電子カルテ(EHR)、X線、皮膚科画像、眼科画像、病理組織スライドなどの様々な医療画像に対して特別にトレーニングされている。MedGemmaはオープンソースであるため、アクセスが容易で、研究者や開発者が単一のGPUで実行するのに適しており、開発の障壁を低くしています。
機能一覧
- 医療テキスト処理:医療レポート、Q&Aペア、電子カルテなど、医療関連のテキストコンテンツを分析・生成。
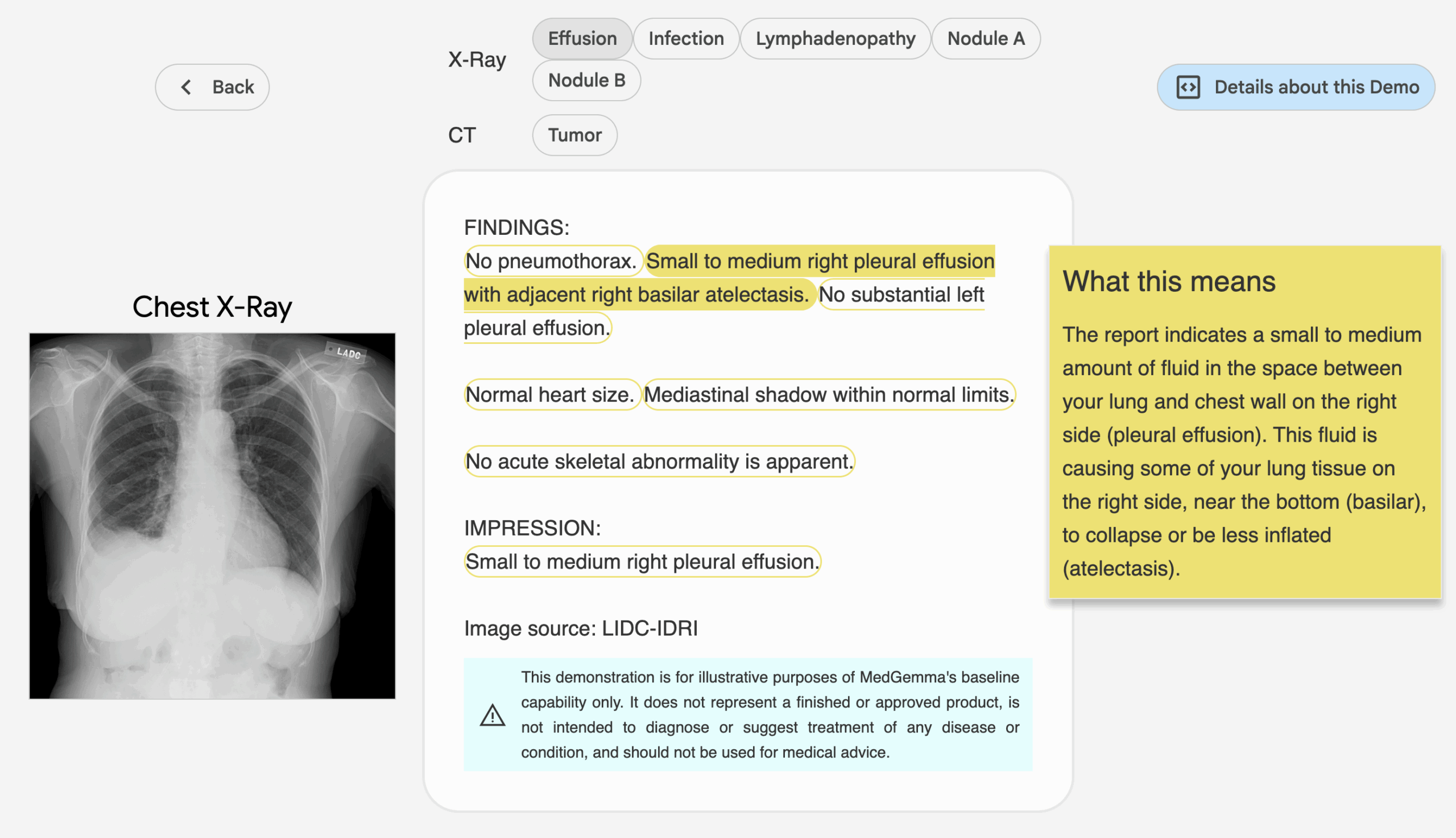
- 医療画像の理解:胸部X線、皮膚科画像、眼科画像、病理組織スライドなど、幅広い医療画像の解析をサポート。
- マルチモーダル推論:テキストと画像データを組み合わせて、放射線診断レポートの作成や画像コンテンツの解釈など、統合された医療推論機能を提供する。
- モデルのバリエーション:4Bパラメータのマルチモーダルモデル(事前学習済みおよびコマンド微調整版)と27Bパラメータのテキストおよびマルチモーダルモデル(コマンド微調整版のみ)を選択可能。
- 効率的な推論最適化:モデルは1つのGPUで実行できるように最適化され、必要な計算リソースが削減されます。
- オープンソースで微調整可能:このモデルは完全にオープンソースであり、開発者は特定のニーズに応じてパフォーマンスを向上させるために微調整することができる。
ヘルプの使用
インストールと展開
MedGemmaのモデルはHugging Faceプラットフォーム上でホストされており、開発者は複雑なインストールをすることなく使用することができます。その仕組みは以下の通りです:
- モデルページへのアクセス
見せるhttps://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4このページでは、4Bと27Bのパラメトリックモデルのダウンロードとドキュメントへのリンクを掲載しています。このページには、4Bおよび27Bパラメトリックモデルのダウンロードリンクとドキュメントが含まれています。 - 環境準備
- Python 3.8以降がインストールされていることを確認してください。
- ハギング・フェイス用のトランスフォーマー・ライブラリーをインストールし、以下のコマンドを実行する:
pip install transformers - PyTorchまたはTensorFlowをインストールする(モデルの要件に応じて選択する)。例えば、PyTorchをインストールします:
pip install torch - 画像データを処理する場合は、次のような追加のライブラリをインストールする必要があります。
Pillow:pip install Pillow
- ダウンロードモデル
ハギングフェイスのモデルページで、希望するMedGemmaのバリアントを選択する。google/medgemma-4b-it或google/medgemma-27b-multimodal).モデルをダウンロードしてロードするには、以下のコードを使用します:from transformers import AutoModel, AutoTokenizer model_name = "google/medgemma-4b-it" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModel.from_pretrained(model_name)27Bモデルはより多くのメモリを必要とし、少なくとも16GBのビデオメモリを搭載したGPUを推奨する。
- 動作環境
MedGemmaモデルは、ローカル開発またはクラウドデプロイメントのためにシングルGPUでサポートされています。デプロイにはGoogle CloudまたはHugging Face Inference Endpointsの使用を推奨します。https://gke-ai-labs.dev/配備のガイドライン
主な機能
1.医療テキスト処理
MedGemmaは、レポートの作成や医学的な質問への回答など、医学的な文章を処理することができる。手順は以下の通りである:
- 入力準備電子カルテの一部や医療に関する質問など、医療に関連するテキストを用意する。
- コード例:
input_text = "患者胸部 X 光显示肺部阴影,可能是什么原因?" inputs = tokenizer(input_text, return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) - 結局このモデルは、医学テキストに関するトレーニングに基づいて、可能性のある診断上の説明や推奨事項を生成します。
2.医用画像理解
MedGemmaのマルチモーダルモデルは、医用画像(X線、皮膚画像など)の解析をサポートします。手順
- 画像の前処理: 画像をモデルが許容するフォーマット(PNGやJPEGなど)に変換します。
- コード例(4Bマルチモーダルモデルを例に):
from PIL import Image import torch image = Image.open("chest_xray.png").convert("RGB") inputs = tokenizer(text="描述这张胸部 X 光图像", images=[image], return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) - 結局例えば、「右肺の下葉に影があり、肺炎の可能性があります。
3.マルチモーダルな推論
マルチモーダルモデルはテキストと画像の両方を処理できる。例えば、X線画像と "この画像は肺炎の兆候を示していますか?"という質問を入力すると、モデルは画像とテキストを組み合わせて回答を生成する。モデルは画像とテキストを組み合わせて答えを生成する。この操作は上で説明したものと似ていますが、ただし tokenizer テキストと画像の両方を
4.モデルの微調整
開発者は、特定のタスクのためにモデルを微調整することができる。手順は以下の通り:
- 特定の医療データセット(カスタム放射線画像やテキストなど)の収集。
- ハギング・フェイスの使用
Trainer微調整のためのAPI:from transformers import Trainer, TrainingArguments training_args = TrainingArguments( output_dir="./medgemma_finetuned", per_device_train_batch_size=4, num_train_epochs=3, ) trainer = Trainer(model=model, args=training_args, train_dataset=your_dataset) trainer.train() - 微調整したモデルは、次回以降使用するために保存しておく。
ほら
- データ汚染のリスクMedGemmaは、事前学習時に一般に公開されている医療データにさらされている可能性があり、開発者は、一般化能力を保証するために、未公開のデータセットを用いてモデルの性能を検証する必要がある。
- 非臨床用MedGemmaは研究開発のみを目的としており、検証なしに実際の臨床診断に使用すべきではない。
- ハードウェア要件4Bモデルは低リソース環境に適しており、27Bモデルはより高性能なGPUを必要とする。
アプリケーションシナリオ
- 放射線レポート作成
放射線技師は、MedGemmaを使ってX線画像やCT画像を解析し、予備レポートを作成することで、画像の迅速な解釈を支援することができる。 - 医療質疑応答システム
開発者は、MedGemmaのテキスト処理機能を使用して、患者や医学生からの一般的な質問に答える医療Q&Aボットを構築することができる。 - 電子カルテ分析
医療機関は、27Bマルチモーダルモデルを使用して、複雑なEHRデータを解析し、重要な情報を抽出して、治療プロセスを最適化することができる。 - 医療研究支援
研究者はMedGemmaを使って医学文献や画像データセットを分析し、例えば皮膚科学的な画像分類や病理組織学的な分析など、研究プロセスを加速することができる。
QA
- MedGemmaは実際の臨床診断に使用できますか?
現在、MedGemmaは研究開発のみに使用されており、臨床的検証なしに診断目的に直接使用することはできない。開発者は、特定のタスクにおけるモデルの信頼性をさらに検証する必要がある。 - 27Bモデルと4Bモデルの違いは何ですか?
4Bモデルは低リソース環境に適しており、マルチモーダルおよびテキストタスクをサポートする。27Bモデルはテキストバージョンとマルチモーダルバージョンに分かれており、より高性能で複雑なタスクに適しているが、より高い計算資源を必要とする。 - データ汚染にどう対処するか?
一般化能力に影響を与える事前学習データを避けるため、非公開データセットまたは内部機関データセットを使用してモデルを検証する。 - MedGemmaはどのような医用画像をサポートしていますか?
胸部X線、皮膚科画像、眼科画像、病理組織スライドなど、幅広い医療画像をサポート。
































