


LMCacheは、大規模言語モデル(LLM)における推論の効率を改善するために設計された、オープンソースのキー・バリュー(KV)キャッシュ最適化ツールです。モデルの中間計算結果をキャッシュして再利用する(キー・バリュー・キャッシュ)ことで、推論時間とGPUリソース消費を大幅に削減します。 vLLM 他の推論エンジンとシームレスに統合され、GPU、CPU、ディスクストレージをサポートし、多ラウンドQ&AやRAG(Retrieval Augmented Generation)などのシナリオに対応します。このプロジェクトは、Apache 2.0ライセンスの下、コミュニティ主導で進められており、エンタープライズレベルのAI推論最適化のために広く利用されています。
機能一覧
- キー・バリュー・キャッシュの再利用LLMのキーと値のペアをキャッシュし、接頭辞のないテキストの再利用をサポート。
- マルチストレージ・バックエンドのサポートGPU、CPU DRAM、ディスク、Redisなどのストレージをサポートし、メモリ制約に柔軟に対応。
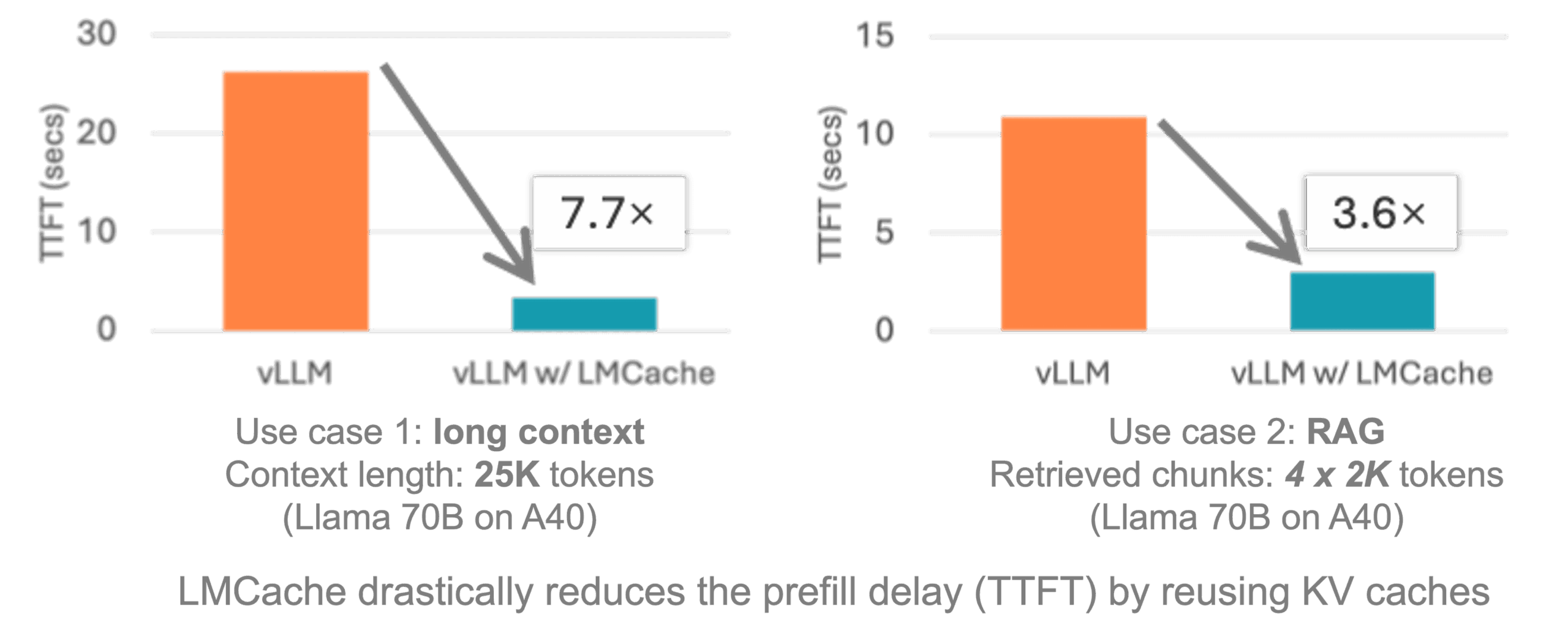
- vLLMとの統合vLLMへのシームレスなアクセスにより、推論レイテンシを3~10倍に最適化。
- 分散キャッシュ複数のGPUやコンテナ環境での共有キャッシングをサポートし、大規模なデプロイメントを可能にします。
- マルチモーダルサポート画像とテキストのキーと値のペアをキャッシュし、マルチモーダルモデル推論を最適化する。
- ワークロード生成複数ラウンドのクイズやRAGなどのワークロードを生成し、パフォーマンスを検証するためのテストツールを提供する。
- オープンソースコミュニティのサポートユーザーの貢献と交流を促進するために、文書、事例、コミュニティ・ミーティングを提供する。
ヘルプの使用
設置プロセス
LMCacheはインストールが簡単で、LinuxプラットフォームとNVIDIA GPU環境をサポートしています。以下は、公式ドキュメントとコミュニティの推奨に基づく、詳細なインストール手順です。
- 環境を整える:
- システムがLinux、Pythonバージョン3.10以上、CUDAバージョン12.1以上であることを確認してください。
- 仮想環境を作成するためにConda(Minicondaを推奨)をインストールする:
conda create -n lmcache python=3.10 conda activate lmcache
- クローン倉庫:
- Gitを使ってLMCacheリポジトリをローカルにクローンする:
git clone https://github.com/LMCache/LMCache.git cd LMCache
- Gitを使ってLMCacheリポジトリをローカルにクローンする:
- LMCacheのインストール:
- PyPI経由で最新の安定版をインストールする:
pip install lmcache - または、最新のプレリリース版(実験的な機能が含まれている可能性があります)をインストールしてください:
pip install --index-url https://pypi.org/simple --extra-index-url https://test.pypi.org/simple lmcache==0.2.2.dev57 - ソースからインストールする必要がある場合:
pip install -e .
- PyPI経由で最新の安定版をインストールする:
- vLLMのインストール:
- LMCacheはvLLMと一緒に使用する必要があるため、最新バージョンのvLLMをインストールしてください:
pip install vllm
- LMCacheはvLLMと一緒に使用する必要があるため、最新バージョンのvLLMをインストールしてください:
- インストールの確認:
- LMCacheが正しくインストールされていることを確認する:
python import lmcache from importlib.metadata import version print(version("lmcache"))出力されるのは、インストールのバージョン番号であるべきだ。
0.2.2.dev57。
- LMCacheが正しくインストールされていることを確認する:
- オプション:Dockerデプロイメント:
- LMCacheは、vLLMを統合したビルド済みのDockerイメージを提供します:
docker pull lmcache/lmcache:latest - Dockerコンテナを実行し、ドキュメントに従ってvLLMとLMCacheを設定する。
- LMCacheは、vLLMを統合したビルド済みのDockerイメージを提供します:
主要機能の使用
LMCacheの中核機能は、LLM推論を高速化するためにキー・バリュー・キャッシュを最適化することである。以下は、主な機能の詳細なハウツーガイドである。
1.キー・バリュー・キャッシュの再利用
LMCacheは、モデルのキー・バリュー・キャッシュ(KV Cache)を保存することで、同じテキストやコンテキストの繰り返し計算を回避します。ユーザーは、vLLMでLMCacheを有効にすることができます:
- 環境変数の設定:
export LMCACHE_USE_EXPERIMENTAL=True export LMCACHE_CHUNK_SIZE=256 export LMCACHE_LOCAL_CPU=True export LMCACHE_MAX_LOCAL_CPU_SIZE=5.0これらの変数は、LMCacheが実験的な機能を使用し、ブロックごとに256トークンを使用し、CPUバックエンドを有効にし、CPUメモリを5GBに制限するように設定する。
- vLLMインスタンスの実行:
LMCacheは、vLLMの起動時に自動的にキーと値のペアをロードし、キャッシュします。サンプルコードです:from vllm import LLM from lmcache.integration.vllm.utils import ENGINE_NAME from vllm.config import KVTransferConfig ktc = KVTransferConfig(kv_connector="LMCacheConnector", kv_role="kv_both") llm = LLM(model="meta-llama/Meta-Llama-3.1-8B-Instruct", kv_transfer_config=ktc)
2.マルチストレージバックエンド
LMCacheは、GPU、CPU、ディスク、Redis上のキーバリューキャッシュの保存をサポートしています。ユーザーはハードウェアリソースに応じてストレージ方法を選択できます:
- ローカル・ディスク・ストレージ:
python3 -m lmcache_server.server localhost 9000 /path/to/diskこれによりLMCacheサーバーが起動し、指定したディスク・パスにキャッシュが保存される。
- Redisストレージ:
Redisバックエンドを設定するには、ユーザー名とパスワードを設定する必要があります:export LMCACHE_REDIS_USERNAME=user export LMCACHE_REDIS_PASSWORD=pass
3.分散キャッシング
マルチGPUやコンテナ化された環境では、LMCacheはノード間の共有キャッシングをサポートします:
- LMCacheサーバーを起動します:
python3 -m lmcache_server.server localhost 9000 cpu - vLLMインスタンスがサーバーに接続できるように設定する。
disagg_vllm_launcher.sh例
4.マルチモーダルサポート
LMCacheは、ハッシュ化された画像トークン(mm_hashes)を介してキーと値のペアをキャッシュすることで、視覚的なLLM推論を最適化するマルチモーダルモデルをサポートしています:
- vLLMでマルチモーダルサポートを有効にするには、公式の例を参照してください。
LMCache-Examples倉庫。
5.テストツール
LMCacheは、パフォーマンスを検証するためのワークロードを生成するテストツールを提供しています:
- クローンテストウェアハウス:
git clone https://github.com/LMCache/lmcache-tests.git cd lmcache-tests bash prepare_environment.sh - テストケースを実行する:
python3 main.py tests/tests.py -f test_lmcache_local_cpu -o outputs/出力は
outputs/test_lmcache_local_cpu.csv。
取り扱い上の注意
- 環境検査CUDAとPythonのバージョンに互換性を持たせるため、Condaの管理環境を使用することを推奨します。
- ログ監視検査
prefiller.log、decoder.log和proxy.log問題をデバッグする。 - 地域支援LMCacheのSlackに参加するか、隔週火曜日午前9時(PT)に開催されるコミュニティ・ミーティングに参加して、助けを求めてください。
アプリケーションシナリオ
- マルチキャスト質疑応答システム
LMCacheは、複数ラウンドの対話シナリオを高速化するために、コンテキスト内のキーと値のペアをキャッシュします。ユーザーがチャットボットで連続した質問をすると、LMCacheは以前の計算結果を再利用して待ち時間を短縮する。 - 検索機能拡張ジェネレーション(RAG)
在 RAG このアプリケーションでは、LMCacheはドキュメントのキーと値のペアをキャッシュし、類似のクエリに素早く応答するため、インテリジェントなドキュメント検索や企業のナレッジベースに適している。 - マルチモーダルモデル推論
視覚言語モデルの場合、LMCacheは画像とテキストのキーと値のペアをキャッシュし、GPUのメモリフットプリントを削減し、応答時間を改善します。 - 大規模分散配置
マルチGPUまたはコンテナ化された環境では、LMCacheの分散キャッシング機能がノード間の共有をサポートし、エンタープライズグレードのAI推論を最適化します。
QA
- LMCacheはどのプラットフォームをサポートしていますか?
現在、LinuxとNVIDIA GPU環境がサポートされており、WindowsはWSL経由で使用できる。 - vLLMとの統合は?
とおすpip install lmcache vllmを有効にし、vLLM構成でLMCacheConnectorを有効にするには、公式サンプルコードを参照してください。 - プレフィックス以外のキャッシュはサポートされていますか?
をサポートし、LMCacheは部分的な再計算技術を使用して、RAGワークロードで接頭辞のないテキストをキャッシュする。 - パフォーマンスの問題をデバッグするには?
ログファイルを調べ、テストケースを実行し、レイテンシーとスループットを分析するためにCSVファイルを出力します。




























