



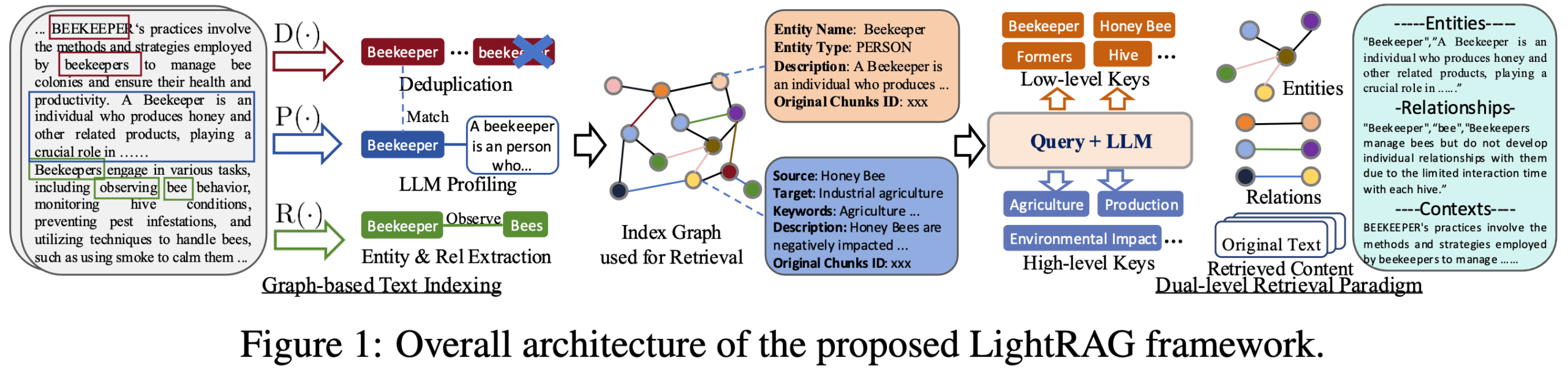
LightRAGは、香港大学データサイエンス学部のチームによって開発されたオープンソースのPythonフレームワークで、RAG(Retrieval Augmented Generation)アプリケーションの構築プロセスを簡素化・高速化する。 従来のベクトル検索技術にナレッジグラフを組み合わせることで、生成されるコンテンツの質を高め、大規模言語モデル(LLM)により正確で文脈に関連した情報を提供する。 このフレームワークの中核となる特徴は、複雑なRAGプロセスを、文書解析、インデックス構築、情報検索、コンテンツ再配置、テキスト生成などの複数の独立したコンポーネントに分解する、軽量でモジュール化された設計にある。この設計は、開発者の敷居を低くするだけでなく、高い柔軟性を提供し、ユーザは、異なるベクトルデータベース、グラフデータベース、または大規模な言語モデルの統合など、特定のニーズに応じて異なるモジュールを簡単に置き換えたり、カスタマイズしたりすることができます。 複雑な情報と深い関係を処理する必要があるシナリオのために設計されたLightRAGは、従来のRAGシステムにおける断片的なテキスト情報と深いつながりの欠如の問題を解決することに専念している。
機能一覧
- モジュール設計RAGプロセスを、ドキュメントの解析、索引付け、検索、再フォーマット、生成のための明確なモジュールに分解し、理解しやすく、カスタマイズしやすくします。
- ナレッジグラフ統合構造化されていないテキストからエンティティや関係を自動的に抽出し、ナレッジグラフを構築する機能。
- 二層検索メカニズムベクトルベースの類似検索と知識グラフベースの関連検索を組み合わせ、特定の詳細(ローカル)とマクロ概念(グローバル)の両方を対象としたクエリを扱うことができます。
- 柔軟なストレージ・オプションキー・バリュー・ペア・ストレージにはJson、PostgreSQL、Redis、ベクトル・ストレージにはFAISS、Chroma、Milvus、グラフ・ストレージにはNeo4j、PostgreSQL AGEなど。
- 高いモデル互換性OpenAI、Hugging Face、Ollamaなどのプラットフォームが提供するものを含む、幅広い大規模言語モデル(LLM)や埋め込みモデルへのアクセスをサポートします。
- マルチファイル・フォーマット対応PDF、DOCX、PPTX、CSV、プレーンテキストなど、さまざまなドキュメント形式を扱うことができます。
- 視覚化ツールナレッジグラフの視覚的な探索をサポートするウェブインターフェースを提供し、データ間のつながりを視覚化できるようにします。
- マルチモーダル機能RAG-Anythingとの統合により、画像、表、数式などのマルチモーダルコンテンツを扱えるようになりました。
ヘルプの使用
LightRAGは、開発者が独自の知識ベースに基づいてインテリジェントなQ&Aシステムを迅速に構築できるように設計された、強力で使いやすいフレームワークです。最大の特徴はナレッジグラフの組み合わせで、検索結果を関連性の高いものにするだけでなく、論理的な関係性をより強固なものにします。以下に、そのインストール方法と使用方法について詳しく説明します。
取り付け
LightRAGを使い始めるのはとても簡単で、Pythonのパッケージマネージャであるpipを使って直接インストールできる。ナレッジグラフの視覚化を含む全機能を体験するには、APIとウェブインターフェースを備えたフルバージョンをインストールすることをお勧めします。
- PyPI経由でのインストール:
ターミナルを開き、以下のコマンドを実行する:pip install "lightrag-hku[api]"このコマンドは、LightRAG のコアライブラリと、サーバーに必要な関連依存関係をインストールします。
- 環境変数の設定:
インストールが完了したら、ランタイム環境を設定する必要があります。LightRAG には環境ファイルのテンプレートが用意されています。env.example.としてコピーする必要があります。.envファイルを開き、あなたの状況に合わせて設定を変更してください。最も重要なのは、大規模言語モデル(LLM)と埋め込みモデルのAPIキーを設定することです。cp env.example .env次にテキストエディタで開く
.envファイルにOPENAI_API_KEYまたはその他のモデルアクセス認証情報。 - サービス開始:
設定が完了したら、ターミナルから次のコマンドを直接実行して、LightRAG サービスを開始します:lightrag-serverサービスが開始されると、ブラウザーからそのサービスが提供するウェブ・インターフェイスにアクセスしたり、APIを通じて対話したりすることができる。
コア使用プロセス
LightRAGの中心的なプログラミング・プロセスは、以下のような明確なものである。 RAG ロジックだ:データ供給 -> インデックス構築 -> クエリー生成以下は簡単な Python コード例です。以下は、LightRAG Coreを使って完全なQ&Aプロセスを実装する方法を示す簡単なPythonコード例です。
- LightRAG インスタンスの初期化
まず、必要なモジュールをインポートし、LightRAG インスタンスを作成する必要があります。初期化中に、作業ディレクトリ(データとキャッシュ用)、組み込み関数、LLM 関数を指定する必要があります。import os import asyncio from lightrag import LightRAG, QueryParam from lightrag.llm.openai import gpt_4o_mini_complete, openai_embed from lightrag.kg.shared_storage import initialize_pipeline_status # 设置工作目录 WORKING_DIR = "./rag_storage" if not os.path.exists(WORKING_DIR): os.mkdir(WORKING_DIR) # 设置你的OpenAI API密钥 os.environ["OPENAI_API_KEY"] = "sk-..." async def initialize_rag(): # 创建LightRAG实例,并注入模型函数 rag = LightRAG( working_dir=WORKING_DIR, embedding_func=openai_embed, llm_model_func=gpt_4o_mini_complete, ) # 重要:必须初始化存储和处理管道 await rag.initialize_storages() await initialize_pipeline_status() return rag銘記する:
initialize_storages()和initialize_pipeline_status()これら2つの初期化ステップは必須であり、さもなければプログラムはエラーを報告する。 - 給餌データ(挿入)
初期化が完了したら、LightRAG にテキストデータを追加できます。ainsertメソッドは文字列または文字列のリストを受け取る。async def feed_data(rag_instance): text_to_insert = "史蒂芬·乔布斯是一位美国商业巨头和发明家。他是苹果公司的联合创始人、董事长和首席执行官。乔布斯被广泛认为是微型计算机革命的先驱。" await rag_instance.ainsert(text_to_insert) print("数据投喂成功!")このステップで、LightRAGは自動的にテキストをチャンクし、エンティティと関係を抽出し、ベクトル埋め込みを生成し、バックグラウンドで知識グラフを構築する。
- クエリーデータ(Query)
データが供給され、インデックスが付けられると、クエリーの準備が整う。aqueryメソッドは質問を受け取りQueryParamオブジェクトを使ってクエリの動作を制御することができる。async def ask_question(rag_instance): query_text = "谁是苹果公司的联合创始人?" # 使用QueryParam配置查询模式 # "hybrid" 模式结合了向量搜索和图检索,推荐使用 query_params = QueryParam(mode="hybrid") response = await rag_instance.aquery(query_text, param=query_params) print(f"问题: {query_text}") print(f"答案: {response}") - 組み合わせて実行する
最後に、上記のステップを1つのメイン関数にまとめ、その中でasyncioを実行する。async def main(): rag = None try: rag = await initialize_rag() await feed_data(rag) await ask_question(rag) except Exception as e: print(f"发生错误: {e}") finally: if rag: # 程序结束时释放存储资源 await rag.finalize_storages() if __name__ == "__main__": asyncio.run(main())
クエリーパターンの説明
LightRAGには、さまざまなアプリケーションシナリオに適した複数のクエリーモードがあります:
naive簡単なクイズのための基本的なベクトル検索パターン。localクエリに直接関連するエンティティ情報に焦点を当て、正確で具体的な回答を必要とするシナリオに適しています。globalマクロで相関的な答えを必要とするシナリオのために、エンティティ間の関係とグローバルな知識に焦点を当てる。hybrid:: コンバインドlocal和globalこのモデルの利点は、最も汎用性が高く、通常最も効果的であることだ。mix知識グラフとベクトル検索の統合は、ほとんどの場合、推薦モデルです。
を使用する。 QueryParam セットアップ mode パラメータを使用すると、これらのモードを柔軟に切り替えて、最良のクエリ結果を得ることができます。
アプリケーションシナリオ
- インテリジェントなカスタマーサービスとQ&Aシステム
企業は、製品マニュアル、ヘルプファイル、過去のカスタマーサービス記録などの内部情報をLightRAGに注入することで、顧客の質問に正確かつ迅速に回答できるインテリジェントなカスタマーサービスロボットを構築することができる。 ナレッジグラフの組み合わせにより、システムは回答を見つけるだけでなく、質問の背後にある関連情報を理解し、より包括的な回答を提供することができる。例えば、製品の機能に関する質問に回答する場合、回答とともに関連するヒントやよくある質問へのリンクを提供することができる。 - 企業内ナレッジベース管理
膨大な量の社内文書(技術文書、プロジェクト報告書、規則や規定など)を抱える組織にとって、LightRAGはそれらを構造化し、インテリジェントに照会可能なナレッジベースに変換することができる。 従業員は自然言語で質問し、必要な情報を素早く見つけ、さらには異なる文書間の隠れたつながりを発見することができ、情報検索の効率と知識の活用を大幅に改善することができます。 - 科学的研究と文献分析
研究者はLightRAGを使って、大量の学術論文や研究報告を処理することができる。 このシステムは、キーとなるエンティティ(技術、研究者、実験など)や概念、それらの関係を自動的に抽出し、ナレッジグラフに構築することができます。これにより、研究者は「ある技術の異なる研究への応用」や「2人の研究者の共同研究」といったクエリのように、文書間の知識を容易に探索することができ、研究プロセスを加速することができる。 - 財務・法律文書分析
金融や法律など、文書が複雑で膨大になりがちな専門分野において、LightRAGはアナリストや弁護士が年次報告書、目論見書、法的条項などの文書から重要な情報を素早く抽出し、それらの論理的関係を整理するのに役立つ。 例えば、契約におけるすべての責任当事者とそれに対応する権利と責任の条項を素早く特定したり、複数の企業の財務報告書における同じ事業の記述を分析して意思決定を支援したりすることが可能である。
QA
- LightRAGはLangChainやLlamaIndexのような汎用フレームワークとどう違うのですか?
LightRAGの差別化の核心は、ナレッジグラフをRAGプロセスに深く統合することに焦点を当て、従来のRAG情報の断片化の問題を解決することにある。 LangChainやLlamaIndexが、より広範な機能を備えた汎用のLLMアプリケーション開発フレームワークであり、豊富なツールや統合オプションを提供する一方、学習曲線が比較的急であるのに対し、LightRAGはより軽量で、ナレッジグラフを組み込んだシンプルで高速かつ効率的なRAGソリューションを開発者に提供することを目的としています。 - LLM(大規模言語モデル)がLightRAGを使用するための特別な要件はありますか?
はい。LightRAG は LLM を使って文書から実体と関係を抽出し、ナレッジグラフを構築する必要があるため、高いレベルのコマンド追従能力とモデルからの文脈理解が必要になります。 参照カウントが少なくとも320億、コンテキストウィンドウの長さが少なくとも32KBのモデルを使用することが公式に推奨されており、より長いドキュメントを処理し、エンティティ抽出タスクを正確に実行するためには64KBを推奨する。 - LightRAGはどのようなデータベースをサポートしていますか?
LightRAGのストレージレイヤーはモジュール式で、複数のデータベース実装をサポートしている。Key-Value Storage (KV Storage)では、ネイティブJSONファイル、PostgreSQL、Redis、MongoDBをサポートし、Vector Storage (Vector Storage)では、NanoVectorDB (デフォルト)、FAISS、Chroma、Milvusなどをサポートする。グラフストレージ(Graph Storage)については、NetworkX(デフォルト)、Neo4j、AGEプラグインを使用したPostgreSQLをサポートしている。この設計により、ユーザーはテクノロジースタックやパフォーマンスのニーズに応じて柔軟に選択することができる。 - LightRAGで自分のモデルを使うことはできますか?例えば、Hugging FaceやOllamaに配備されているモデルなど?
LightRAGは、カスタムLLMや組み込みモデルを統合できる柔軟なモデルインジェクションメカニズムを設計している。 リポジトリにあるサンプルコードでは、すでにHugging Faceと Ollama モデルの例です。インターフェイス仕様に準拠した呼び出し関数を書き、LightRAGインスタンスを初期化する際に渡すだけでよい。































