
クロード・コードは、これまでで最も楽しいAIエージェントのワークフローのひとつである。指示されたコードの編集や即興ツールの開発を煩わしくなくするだけでなく、それを使う経験自体が楽しいとさえ言われている。開発者に突発的なストレスを与えることなく、興味深いタスクをこなすのに十分な自律性を備えている。.

Retrieval Augmented Generation (RAG)に基づく知識ベースアプリケーションを構築する際、ドキュメントの前処理とスライシング(チャンキング)は、最終的な検索結果を決定する重要なステップである。オープンソースのRAGエンジンRAGFlowは様々なスライシング戦略を提供しているが、その公式ドキュメントには手法の詳細や具体的なケースに関する明確な説明がないため、開発者に多くの混乱を招いている。.

RAG(Retrieval Augmented Generation)システムを構築する際、開発者はしばしば次のような不可解なシナリオに遭遇する。 あいまいなスキャンに直面したとき、モデルが確信を持って完全に正しくないコンテンツを与えてしまう。 数式中の和記号 “Σ ”が文字 “E ”として誤って認識される。 文書の透かし.

まずは簡単なタスクから始めよう。 ユーザーが、“ねぇ、明日ちょっと同期してみない?”と言ったとする。 プロンプト・エンジニアリングだけに頼るAIなら、“はい、明日で結構です。何時に予約しますか?” と答えるかもしれない。 この返答は正しいが、機械的で...

要旨 大規模言語モデル(LLM)の出現は、生成モデルを使用して情報を収集し、要約してユーザーのクエリに回答する検索エンジンの新しいパラダイムを切り開いた。我々は、正確でパーソナライズされた回答を生成するGenerative Engines (GEs)のフレームワークの下でこの新しい技術を統合し、Googleや...といった従来の検索エンジンに急速に取って代わる。.

Manusプロジェクトの初期、チームは重大な決断に迫られた。オープンソースのモデルをベースにエンドツーエンドのエージェントモデルを訓練すべきか、それとも最先端のモデルの強力な「コンテキスト学習」機能を活用してエージェントを構築すべきか。 10年前にさかのぼれば、自然言語処理分野では開発者に選択肢すらなかった。BERTの時代には、どんなモデルでも...

RAGやAIエージェントのようなAIシステムを構築する場合、検索品質はシステムの上限を決定する鍵となる。開発者は通常、キーワード検索とセマンティック検索の2つの主要な検索技術に頼っている。 キーワード検索(例:BM25):高速で完全一致が得意。しかし、ユーザーの質問の文言が変わると、想起率が低下する。 ...

会話の内容をいつも忘れてしまい、毎回最初から話し始めなければならない友人とのコミュニケーションは、間違いなく非効率的で疲れるものだ。しかし、現在のほとんどのAIシステムでは、まさにこれが普通なのだ。それらは強力だが、一般的に重要な要素である「記憶」が欠けているのだ。 真に学習し、進化し、協力できるAIインテリジェンス(エージェント)を構築するためには、記憶は...

大規模言語モデル(LLM)のAPIコールから、自律的で目標駆動型のエージェント型ワークフローまで、AIアプリケーションのパラダイムに根本的な変化が起きている。オープンソースコミュニティはこの波において重要な役割を果たしており、特定の研究タスクに焦点を当てたAIツールが数多く生まれている。これらのツールは ...

強化学習(RL)のすべてを学び、UnslothとGRPOを使用して独自のDeepSeek-R1推論モデルをトレーニングする方法を学びます。初心者からマスターまでの完全ガイドです。 RLとは? RLVRとは? PPOとは? GRPOとは? RLHFとは? RFTとは?...

大規模な言語モデリング技術の急速な発展と広範な応用に伴い、その潜在的なセキュリティリスクはますます業界の注目の的となっている。このような課題に対処するため、世界トップクラスのテクノロジー企業、標準化団体、研究機関の多くが、独自のセキュリティフレームワークを構築し、公開しています。本稿では、関連分野の包括的な概観を提供することを目的として、大規模モデルの代表的な9つのセキュリティフレームワークを分析する。.
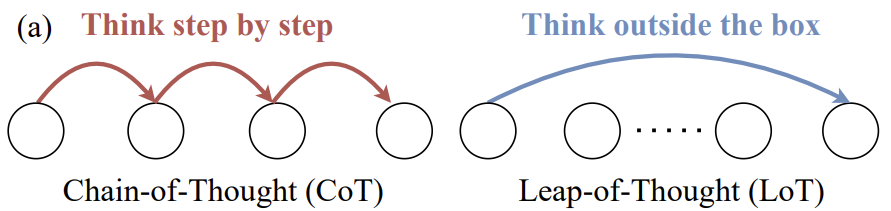
大規模言語モデリング(LLM)研究の分野では、モデルの思考飛躍能力、すなわち創造性は、思考連鎖(Chain-of-Thought)に代表される論理的推論能力に劣らず重要である。しかし、LLMの創造性についての詳細な議論や有効な評価方法は、まだ相対的に不足している。
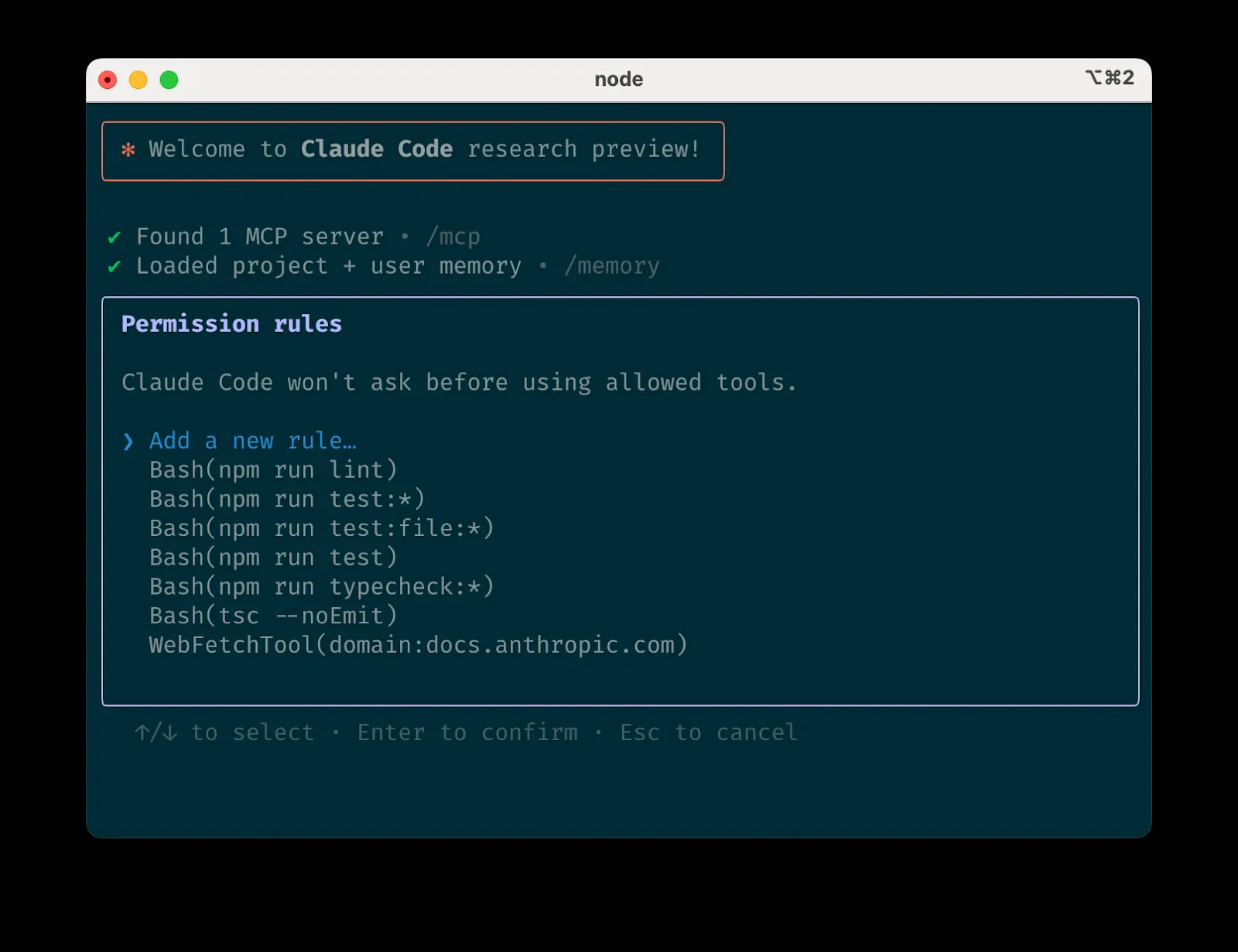
クロード・コードを使いこなす:最前線からのハンズオン・エージェント・コーディングのヒント クロード・コードは、エージェント・コーディングのためのコマンドライン・ツールです。Agentic Codingとは、AIにある程度の自律性を与え、タスクを理解し、ステップを計画し、アクション(...

GPT-4.1ファミリーは、GPT-4oと比較して、コーディング、命令順守、長いコンテキストの処理能力が大幅に向上しています。具体的には、コード生成と修復タスクでより優れたパフォーマンスを発揮し、複雑な命令をより正確に理解して実行し、長い入力テキストを効率的に処理することができます。このヒントエンジニアリングガイドは、OpenAI ...
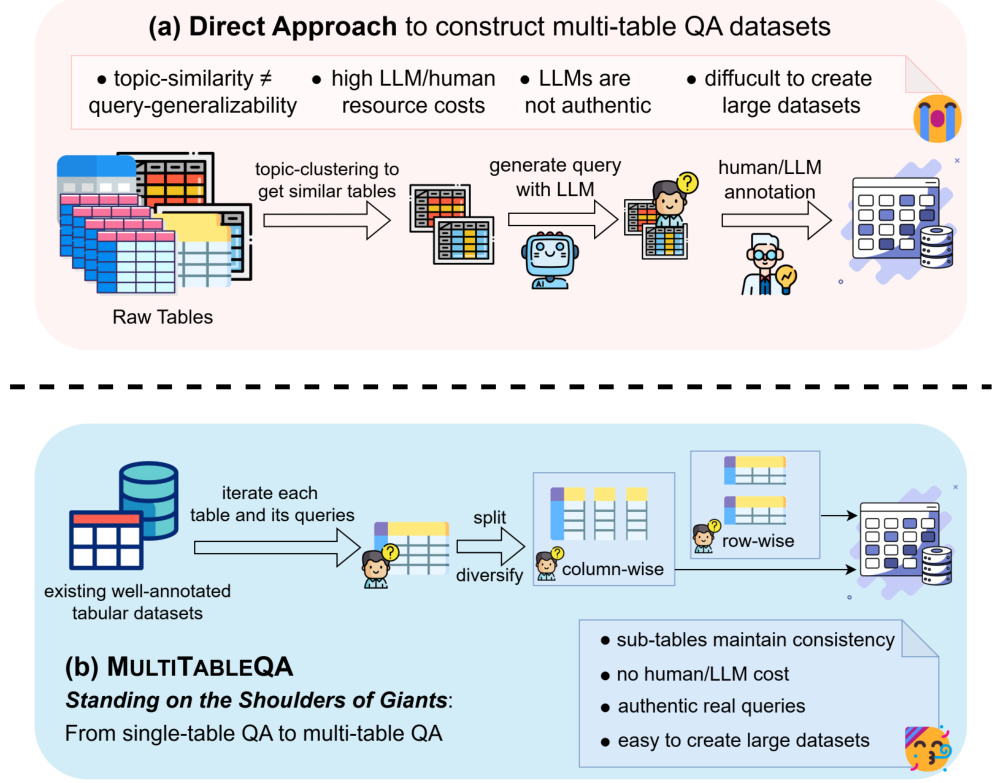
1.はじめに 今日の情報爆発では、大量の知識がウェブページ、ウィキペディア、リレーショナル・データベースのテーブルの形で保存されている。しかし、従来のQ&Aシステムでは、複数のテーブルにまたがる複雑なクエリの処理に苦戦することが多く、人工知能の分野で大きな課題となっている。この課題に対処するため、研究者はGTR(Graph-Table ...
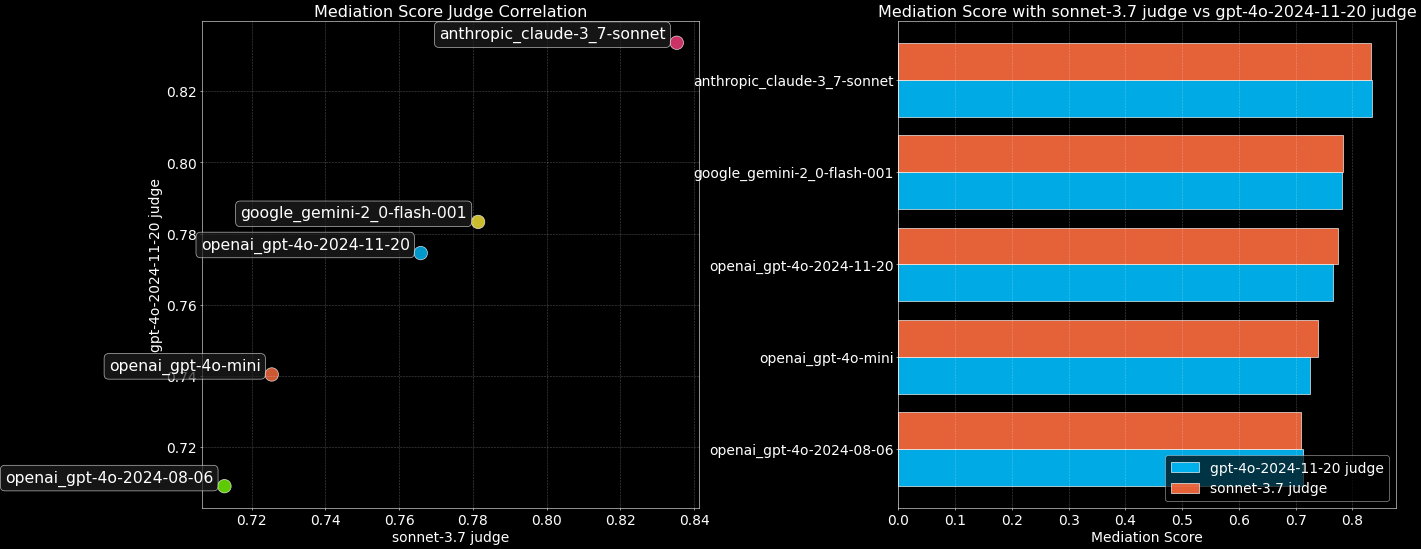
大規模言語モデル(LLM)の能力が飛躍的に向上するにつれ、MMLUのような従来のベンチマークテストでは、トップモデルの識別に限界が見えてきています。感情的知性、創造性、判断力、コミュニケーション能力など、実世界の相互作用においてモデルにとって重要な微妙な能力を総合的に測定するために、知識クイズや標準化されたテストだけに頼ることはもはや不可能です。このような状況においてこそ.

大規模言語モデル(LLM)の開発は急速に変化しており、その推論能力は知能レベルを示す重要な指標となっている。特に、OpenAIのo1、DeepSeek-R1、QwQ-32B、Kimi K1.5のような長い推論能力を持つモデルは、複合問題を解くことによって人間の深い思考プロセスをシミュレートする...
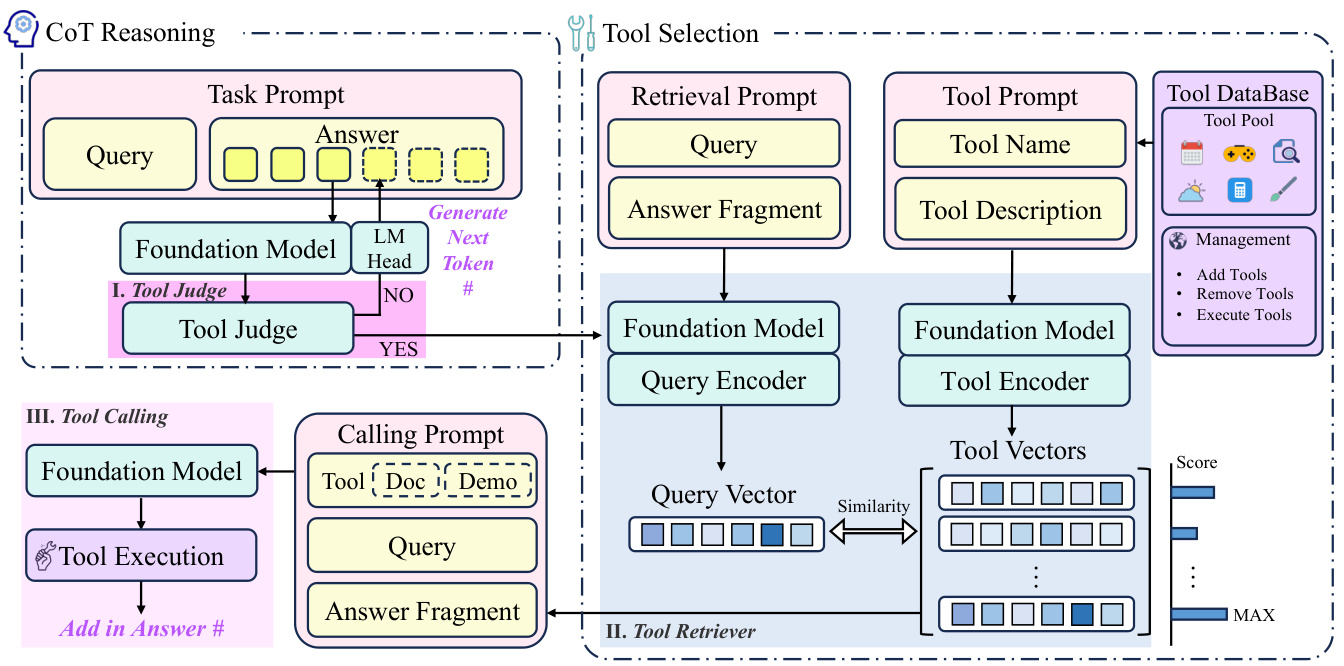
はじめに 近年、大規模言語モデル(Large Language Models: LLM)は人工知能(Artificial Intelligence: AI)の分野で目覚ましい進歩を遂げ、その強力な言語理解・生成能力により、様々な領域で幅広い応用が行われている。しかし、外部ツールの起動を必要とする複雑なタスクを扱う場合、LLMは依然として多くの課題に直面している。例えば、ユーザーが「明日の目的地の天気は?.
Pythonのエコシステムは、古典的なpipやvirtualenvから、pip-toolsやconda、最新のPoetryやPDMに至るまで、パッケージ管理や環境管理ツールに常に事欠かない。それぞれのツールにはそれぞれの専門分野があるが、開発者のツールチェーンを断片化し複雑にしてしまうことが多い。 今、 ...
トップに戻る

