



Kitten-TTS-Serverはオープンソースプロジェクトであり、軽量なTTSサーバーを提供します。 KittenTTS このモデルは機能を強化したサーバーを提供する。ユーザはこのプロジェクトで音声合成(TTS)サービスを自分で構築することができる。このプロジェクトの核となる強みは、直感的なウェブUI、オーディオブック用の長文処理、大幅なパフォーマンス向上のためのGPUアクセラレーションを追加することによって、オリジナル・モデルをベースにしていることである。サーバーの基礎となるモデルは25MB未満と非常に小さいが、リアルで自然な響きの人間の声を生成する。このプロジェクトでは、専門知識のないユーザーにも使いやすいフル機能のサーバーを提供することで、モデルのインストールと実行のプロセスを簡素化しました。サーバーには8つのプリセット・ボイス(男性4、女性4)が内蔵されており、Docker経由でのデプロイをサポートすることで、設定やメンテナンスの複雑さを大幅に軽減している。
機能一覧
- 軽量モデルこのコアはKittenTTS ONNXモデルを使用しており、サイズが25MB未満で、リソースのフットプリントが小さくなっています。
- GPUアクセラレーション最適化された
onnxruntime-gpuNVIDIA(CUDA)アクセラレーションをフルサポートするパイプラインおよびI/Oバインディングテクノロジーにより、スピーチ生成を大幅に高速化。 - 長文とオーディオブックの生成文章をインテリジェントに分割し、チャンク単位で処理し、音声をシームレスにつなぎ合わせることで、長い文章を自動的に処理する機能は、完全なオーディオブックを生成するのに理想的です。
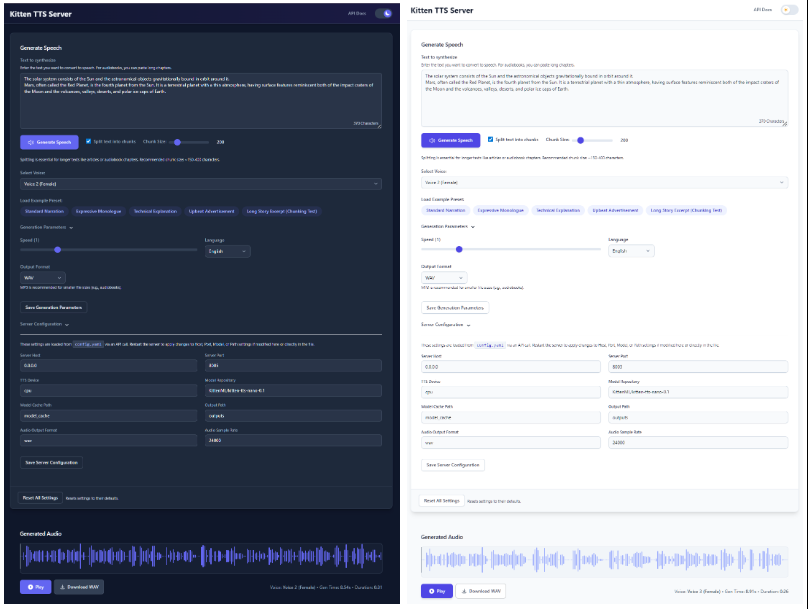
- 近代化されたウェブ・インターフェイスウェブUIは直感的なウェブインターフェースを提供し、ユーザーはテキストの入力、音声の選択、音声レートの調整、生成された音声の波形をリアルタイムで確認することができます。
- 内蔵マルチボイスKittenTTSモデル付属の8ボイス(男性4ボイス、女性4ボイス)を統合し、インターフェースから直接選択できます。
- デュアルAPIインターフェース完全な機能を提供
/ttsインターフェースと互換性のあるOpenAI TTS API構造。/v1/audio/speech既存のワークフローに簡単に統合できるインターフェース。 - シンプルな構成すべての設定は
config.yamlドキュメントは管理されている。 - ステートメモリーWebインターフェースは、最後に使用したテキスト、音声、および関連する設定を記憶し、操作プロセスを簡素化します。
- DockerのサポートDocker Compose: CPUおよびGPU環境用に設定済みのDocker Composeファイルを提供し、ワンクリックでコンテナをデプロイできます。
ヘルプの使用
Kitten-TTS-Serverプロジェクトは、ユーザーが自分のハードウェア上で問題なく稼働できるように、明確なインストールと使用プロセスを提供しています。
システム環境の準備
インストールの前に、以下の環境を準備する必要がある:
- オペレーティングシステムWindows 10/11 (64-bit) または Linux (Debian/Ubuntu 推奨)。
- Python3.10以降
- GitGitHubからプロジェクトのコードをクローンする。
- eSpeak NGこれはテキストの音声化には必須の依存関係です。
- WindowseSpeak NGのリリースページからダウンロードし、インストールしてください。
espeak-ng-X.XX-x64.msi.インストール後、コマンドライン・ターミナルを再起動する必要があります。 - Linuxターミナルでコマンドを実行する。
sudo apt install espeak-ng。
- WindowseSpeak NGのリリースページからダウンロードし、インストールしてください。
- (GPUアクセラレーションはオプション):
- CUDA対応のNVIDIAグラフィックカード。
- (Linuxのみ):以下のインストールが必要。
libsndfile1和ffmpeg.これはコマンドsudo apt install libsndfile1 ffmpegをインストールする。
インストール手順
インストールプロセス全体は「ワンクリック」で行えるように設計されており、ハードウェアによってインストール経路が異なります。
ステップ1:コードリポジトリをクローンする
ターミナル(WindowsではPowerShell、LinuxではBash)を開き、以下のコマンドを実行する:
git clone https://github.com/devnen/Kitten-TTS-Server.git
cd Kitten-TTS-Server
ステップ2:Python仮想環境の作成と起動
他のプロジェクトの依存ライブラリとの競合を避けるため、別の仮想環境を作成することを強くお勧めします。
- Windows (PowerShell):
python -m venv venv .\venv\Scripts\activate - Linux (Bash):
python3 -m venv venv source venv/bin/activate
アクティベーションに成功すると、コマンドラインプロンプトの前に (venv) 言葉だ。
ステップ3:Pythonの依存関係をインストールする
お使いのコンピュータにNVIDIAグラフィックスカードが搭載されているかどうかに応じて、次のいずれかのインストール方法を選択してください。
- オプション1:CPUのみのインストール(最も簡単)
これはすべてのコンピューターで機能する。pip install --upgrade pip pip install -r requirements.txt - オプション2:NVIDIA GPUによるインストール(より高いパフォーマンス)
このアプローチでは、プログラムがグラフィックカード上で実行できるように、必要なCUDAライブラリをすべてインストールする。pip install --upgrade pip # 安装支持GPU的ONNX Runtime pip install onnxruntime-gpu # 安装支持CUDA的PyTorch,它会一并安装onnxruntime-gpu所需的驱动文件 pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu121 # 安装其余的依赖 pip install -r requirements-nvidia.txtインストールが完了したら、次のコマンドを実行して、PyTorchがグラフィックスカードを正しく認識していることを確認できます:
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}')"出力が
CUDA available: TrueGPU環境は正常に設定されています。
オペレーション・サーバー
銘記する初回起動時に、Hugging FaceのKittenTTSモデルファイル(約25MB)を自動的にダウンロードします。このプロセスは一度だけ行えばよく、その後の起動は非常に速くなります。
- 仮想環境が有効になっていることを確認してください(コマンドラインの前に
(venv))。 - ターミナルでサーバーを起動する:
python server.py - サーバーが起動すると、デフォルトのブラウザーでウェブ・インターフェイスが自動的に開きます。
- ウェブインターフェースのアドレス。
http://localhost:8005 - APIドキュメントのアドレス
http://localhost:8005/docs
- ウェブインターフェースのアドレス。
サーバーを停止するには、サーバーを実行しているターミナル・ウィンドウで次のように押します。 CTRL+C。
Dockerのインストール方法
Dockerに慣れていれば、デプロイにDocker Composeを使うことができる。
- 環境準備:
- DockerとDocker Composeをインストールします。
- (GPU ユーザー)NVIDIA Container Toolkit をインストールします。
- クローン・コード・リポジトリ (もしそうでなければ)。
git clone https://github.com/devnen/Kitten-TTS-Server.git cd Kitten-TTS-Server - 打ち上げコンテナ (ハードウェアに応じてコマンドを選択してください)。
- NVIDIA GPUユーザー:
docker compose up -d --build - CPUユーザーのみ:
docker compose -f docker-compose-cpu.yml up -d --build
- NVIDIA GPUユーザー:
- アクセスと管理:
- ウェブインターフェース。
http://localhost:8005 - ジャーナルを見る
docker compose logs -f - コンテナを止める。
docker compose down
- ウェブインターフェース。
機能操作
- 通常の音声を生成する:
- サーバーを起動し
http://localhost:8005。 - テキストボックスに変換したいテキストを入力します。
- ドロップダウンメニューから好きなサウンドを選択します。
- スライダーをドラッグして話すスピードを調整できます。
- Generate Speech "ボタンをクリックすると、音声が自動的に再生され、ダウンロードリンクが表示されます。
- サーバーを起動し
- オーディオブックの作成:
- 本全体または章をプレーンテキストでコピーする。
- それをウェブページのテキストボックスに貼り付ける。
- テキストを分割する」にチェックが入っていることを確認してください。
- 間をより自然にするために、チャンクサイズを300文字から500文字の間に設定することをお勧めします。
- Generate Speech "ボタンをクリックすると、サーバーが自動的に長いテキストをスライスし、音声を生成し、最終的に完全な音声ファイルにつなぎ合わせてダウンロードできるようにします。
アプリケーションシナリオ
- オーディオブックの制作
本を聴くのが好きなユーザーやコンテンツ制作者にとって、このツールは電子ブックや長い記事、ウェブ小説をオーディオブックに変換するのに使えます。その長いテキスト処理機能は、自動的に完全なオーディオファイルを生成するためにスライスとスプライスを行うことができます。 - パーソナル音声アシスタント
開発者はAPIをアプリケーションに統合することで、ニュースや天気予報、通知メッセージの読み上げなど、音声アナウンスをアプリに追加することができる。 - ビデオ・コンテンツのダビング
セルフメディアクリエイターは、動画制作時のナレーションや吹き替えの生成に利用できます。生録よりも効率的でコストもかからず、いつでもコピーを変更してナレーションを再生できます。 - 学習教材
学習者は単語や文章を入力すると、標準化された発音が生成され、それに沿って模倣することができます。学習教材は音声に変換して、通勤中や運動中に聞くこともできます。
QA
- このプロジェクトは、KittenTTSモデルを直接使うのとどう違うのですか?
このプロジェクトはKittenTTSモデルの「サービス」ラッパーであり、複雑な環境設定、ユーザーインターフェースの欠如、モデルを直接使用する際のGPUアクセラレーションの欠如といった問題を解決します。Kitten-TTS-Serverは、すぐに使えるウェブインターフェースとAPIサービスを提供し、一般的なユーザーが簡単に使えるようにします。 - インストール中にeSpeak関連のエラーが発生した場合はどうすればよいですか?
これは最も一般的な問題です。お使いのオペレーティングシステムにeSpeak NGが正しくインストールされているか、インストール後にコマンドラインターミナルを再起動したかどうかを確認してください。問題が解決しない場合は、eSpeak NGがシステムの標準パスにインストールされていることを確認してください。 - GPUアクセラレーションが有効であることを確認するには?
まず、NVIDIA GPU用の依存関係がすべてインストールされていることを確認してください。それからpython -c "import torch; print(torch.cuda.is_available())"コマンドが返された場合Trueと表示され、環境が正しく設定されていることを示す。サーバーの実行中に、タスクマネージャーまたはnvidia-smiコマンドでGPUの使用状況を見ることができます。 - ポートが占有されています。
これは、お使いのコンピューター上に、ポート8005を占有する他のプログラムがすでに存在することを意味します。あなたはconfig.yamlファイルを作成する。server.portを他の空いているポート番号に変更する。8006)、サーバーを再起動する。



























