



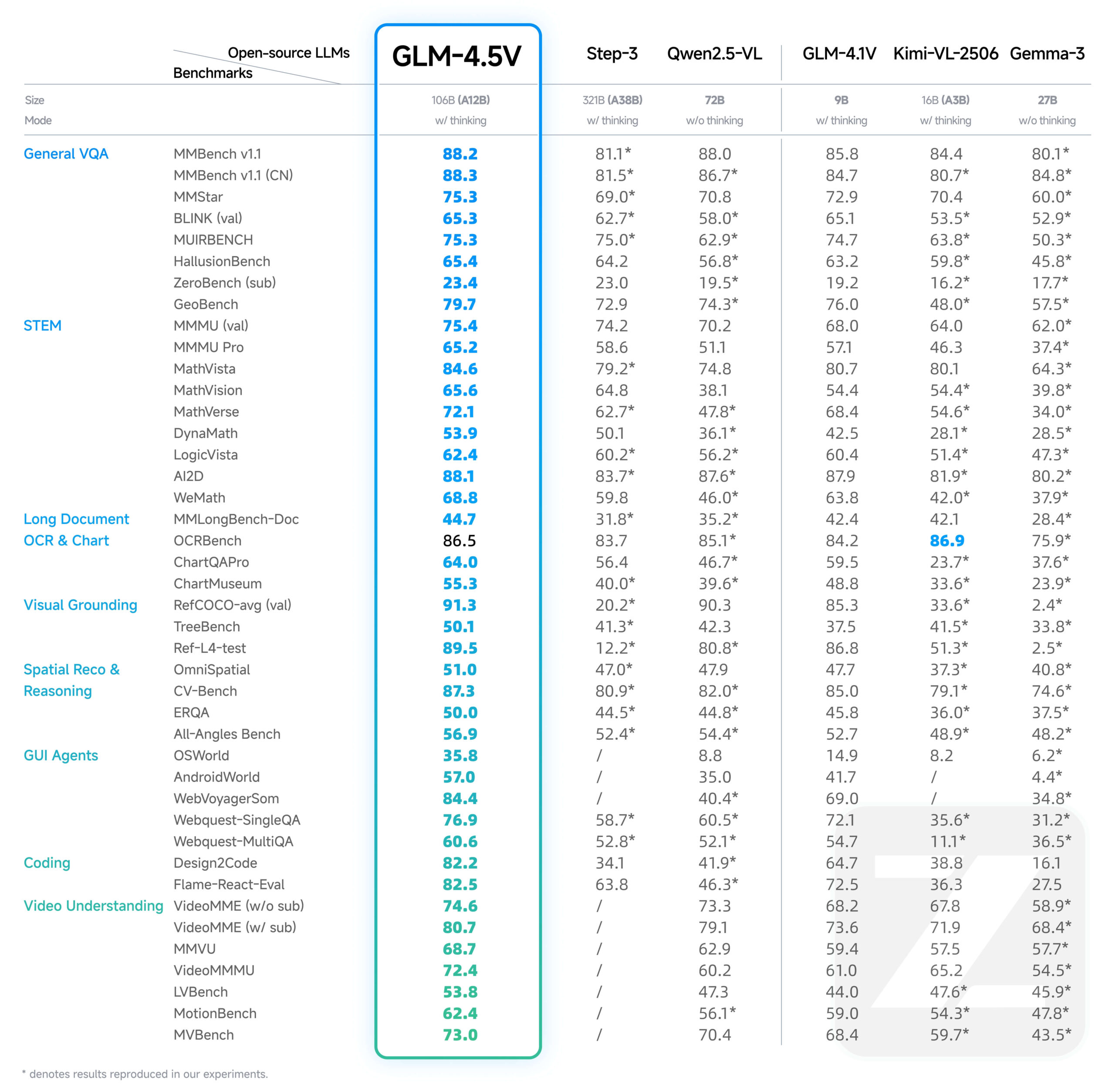
GLM-4.5VはZhipu AI (Z.AI)によって開発された新世代の視覚言語メガモデル(VLM)です。GLM-4.5Vは画像とテキストを扱うだけでなく、ビデオコンテンツも理解することができ、そのコアコンピテンシーは複雑な画像推論、長時間のビデオ理解、文書コンテンツの解析、グラフィカルユーザーインターフェイス(GUI)の操作タスクに及びます。のタスクが含まれる。異なるシナリオにおける効率と有効性のバランスをとるため、このモデルは「思考モード」スイッチを導入しており、ユーザーは高速応答が必要なタスクと深い推論が必要なタスクを切り替えることができる。このモデルは最大64Kトークンの出力長をサポートし、MITライセンスの下、Hugging Face上でオープンソース化されているため、開発者は商用および二次開発に使用することができます。
機能一覧
- ウェブページのコード生成ウェブページのスクリーンショットやスクリーンレコーディングを分析し、レイアウトやインタラクションロジックを理解し、完全に使用可能なHTMLとCSSコードを直接生成します。
- 接地画像やビデオ内の特定のオブジェクトの位置を正確に特定し、座標の形で特定することができる(例.
[x1,y1,x2,y2])は、セキュリティ、品質管理、コンテンツ監査などのシナリオのためにターゲット・ロケーションに戻る。 - GUIインテリジェンススクリーンショットを認識・処理し、コマンドに応じてクリック、スワイプ、コンテンツの変更などのアクションを実行する能力は、自動化されたタスクを実行する知能をサポートする。
- 長い複雑な文書の解釈数十ページに及ぶ複雑なグラフィカルレポートを深く分析し、コンテンツの要約、翻訳、図表抽出、ドキュメントの内容に基づいた洞察を提供する機能をサポートします。
- 画像認識と推論強力なシーン理解と論理的推論能力。外部検索に頼ることなく、画像の内容のみからその背後にある文脈情報を推論することができる。
- ビデオ理解長いビデオコンテンツを解析し、ビデオ内の時間、人物、出来事、それらの論理的関係を正確に特定する。
- 懲罰に関する質問と回答:: グラフィックとテキストを組み合わせた複雑な問題を解く能力。特に、K12教育の場面での演習問題を解き、説明するのに適している。
ヘルプの使用
GLM-4.5Vは、公式APIによる迅速な統合やHugging Faceによるローカル展開など、開発者がアクセスし使用するための様々な方法を提供する。
1.ウィズダムスペクトラムAIオープンプラットフォームAPIを通じて利用する(推奨)
公式APIの使用は、モデルをアプリケーションに素早く統合したい開発者にとって最も便利な方法です。このアプローチでは、複雑なハードウェアリソースを管理する必要がありません。
API価格
- 輸入百万円 tokens
- 輸出1.8円/100万トークン
起動ステップ
- APIキーの取得Smart Spectrum AI Open Platformにアクセスし、アカウント登録とAPI Keyの作成を行う。
- SDKのインストール:
pip install zhipuai - 呼び出しコードを書く以下はPython SDKを使ったAPI呼び出しの例で、画像とテキストを送信して質問する方法を示しています。
from zhipuai import ZhipuAI # 使用你的API Key进行初始化 client = ZhipuAI(api_key="YOUR_API_KEY") # 请替换成你自己的API Key response = client.chat.completions.create( model="glm-4.5v", # 指定使用GLM-4.5V模型 messages=[ { "role": "user", "content": [ { "type": "text", "text": "这张图片里有什么?请详细描述一下。" }, { "type": "image_url", "image_url": { "url": "https://img.alicdn.com/imgextra/i3/O1CN01b22S451o81U5g251b_!!6000000005177-0-tps-1024-1024.jpg" } } ] } ] ) print(response.choices[0].message.content)
シンキング・モードの有効化
モデルによるより深い推論を必要とする複雑なタスク(複雑なグラフの分析など)にはthinkingパラメータで "think mode "を有効にする。
以下は、最も一般的なcURL思考モードの呼び出しと有効化の公式例:
curl --location 'https://api.z.ai/api/paas/v4/chat/completions' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "glm-4.5v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://cloudcovert-1305175928.cos.ap-guangzhou.myqcloud.com/%E5%9B%BE%E7%89%87grounding.PNG"
}
},
{
"type": "text",
"text": "桌子上从右数第二瓶啤酒在哪里?请用[[xmin,ymin,xmax,ymax]]格式提供坐标。"
}
]
}
],
"thinking": {
"type":"enabled"
}
}'
2.ハギング・フェイス・トランスフォーマーによる現地展開
二次開発やオフラインでの使用を必要とする研究者や開発者のために、ハギング・フェイス・ハブからモデルをダウンロードし、自身の環境に展開することができる。
- 環境要件ローカル展開には強力なハードウェアサポートが必要で、通常は大容量ビデオメモリを搭載した高性能NVIDIA GPUが必要です(例:A100/H100)。
- 依存関係のインストール:
pip install transformers torch accelerate Pillow - モデルのロードと実行:
import torch from PIL import Image from transformers import AutoProcessor, AutoModelForCausalLM # Hugging Face上的模型路径 model_path = "zai-org/GLM-4.5V" processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True) # 加载模型 model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True ).to("cuda").eval() # 准备图片和文本提示 image = Image.open("path_to_your_image.jpg").convert("RGB") prompt_text = "请使用HTML和CSS,根据这张网页截图生成一个高质量的UI界面。" prompt = [{"role": "user", "image": image, "content": prompt_text}] # 处理输入并生成回复 inputs = processor.apply_chat_template(prompt, add_generation_prompt=True, tokenize=True, return_tensors="pt", return_dict=True) inputs = {k: v.to("cuda") for k, v in inputs.items()} gen_kwargs = {"max_new_tokens": 4096, "do_sample": True, "top_p": 0.8, "temperature": 0.6} with torch.no_grad(): outputs = model.generate(**inputs, **gen_kwargs) response_ids = outputs[:, inputs['input_ids'].shape[1]:] response_text = processor.decode(response_ids[0]) print(response_text)
アプリケーションシナリオ
- フロントエンド開発の自動化
開発者はデザインされたウェブページのスクリーンショットを提供することができ、GLM-4.5VはスクリーンショットのUIレイアウト、カラースキーム、コンポーネントスタイルを直接分析し、対応するHTMLとCSSコードを自動的に生成することができます。 - インテリジェント・セキュリティ
セキュリティ監視のシナリオでは、このモデルはリアルタイムのビデオストリームを分析し、コマンド(例えば、「写真の中で赤い服を着ているすべての人の位置を特定してください」)に従って画面上のターゲットの位置を正確にマークすることができ、これは人物の追跡や異常行動の検出などに使用できる。 - オフィス・オートメーション・インテリジェンス
オフィス・ソフトウェアでは、ユーザーは自然言語コマンド・モデルを通じて複雑な操作を完了することができる。例えば、ユーザーは「PPTの4ページ目の表の1行目のデータを'89', '21', '900'に変更してください」と言うことができ、モデルは画面の内容を認識し、マウスとキーボードの操作をシミュレートして修正を完了する。「モデルは画面の内容を認識し、マウスとキーボードの操作をシミュレートして修正を完了します。 - リサーチと財務書類分析
研究者やアナリストは、何十ページもの調査報告書や財務報告書をPDF形式でアップロードし、このモデルに「報告書の核となるポイントを要約し、第3章の主要データをMarkdownテーブルに変換する」よう依頼することができる。モデルは、詳細な情報を読み取り、情報を抽出し、構造化されたサマリーとチャートを生成します。 - K12教育カウンセリング
生徒は数学や物理の応用問題(図や文章を含む)の写真を撮り、モデルに質問することができます。模範解答は正解を示すだけでなく、先生のように、問題を解くための考え方や公式を段階的に説明し、詳しい解答プロセスを提供します。
QA
- GLM-4.5VとGLM-4.1Vの関係は?
GLM-4.5Vは、GLM-4.1V-Thinkingテクノロジーラインの継続的かつ反復的なアップグレードです。より強力なプレーンテキストのフラッグシップモデルGLM-4.5-Airをベースに構築され、先行モデルの能力を継承することを基本に、あらゆる種類の視覚的マルチモーダルなタスクのパフォーマンスを総合的に向上させます。 - GLM-4.5VのAPIを使用するコストは?
Wisdom Spectrum AIの公式APIを通じてモデルを使用する場合の課金レートは、入力側が100万トークンあたり0.6人民元、出力側が100万トークンあたり1.8人民元である。 - シンキングモード」(思考モード)は具体的に何をするのか?
「思考モードは、深い推論を必要とする複雑なタスクのために設計されています。有効にすると、モデルは論理的思考と情報の統合に多くの時間を費やし、より高品質で正確な回答を生成しますが、応答時間は長くなります。複雑なダイアグラムの分析、コードの記述、長い文書の解釈などのシナリオに適しています。単純な質問と回答には、より高速な非思考モデルを使用することができます。



























