


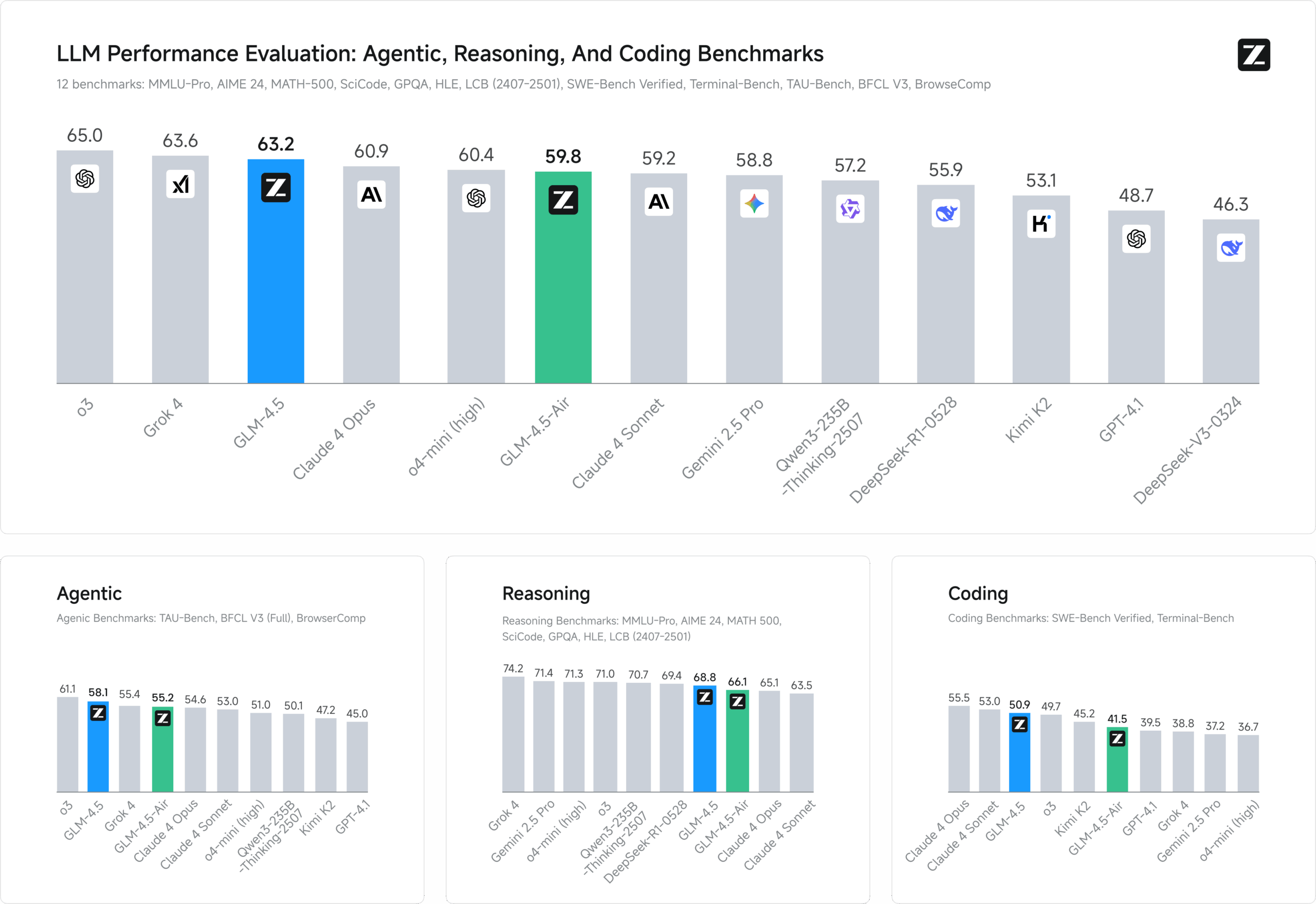
GLM-4.5はzai-orgによって開発されたオープンソースのマルチモーダル大規模言語モデルで、知的推論、コード生成、知的身体タスクのために設計されています。GLM-4.5(3,550億パラメータ、320億アクティブパラメータ)、GLM-4.5-Air(1,060億パラメータ、120億アクティブパラメータ)、その他のバリエーションから構成され、Mixed Expertise (MoE)アーキテクチャを採用し、128Kのコンテキスト長と96Kの出力トークンをサポートする。GLM-4.5は、MITライセンスのもとでリリースされ、学術的、商業的な使用をサポートし、開発者、研究者、企業がローカルまたはクラウド上で展開するのに適しています。
機能一覧
- ミックス推論モード:複雑な推論やツールの呼び出しを処理する思考モードと、迅速な応答を提供する非思考モードをサポートします。
- マルチモーダル対応:マルチモーダルなQ&Aやコンテンツ生成のために、テキストや画像の入力を扱う。
- インテリジェント・プログラミング:Python、JavaScript、その他の言語で高品質のコードを生成し、コード補完とバグ修正をサポートします。
- インテリジェントな本体機能:複雑なワークフローのための関数呼び出し、ウェブブラウジング、自動タスク処理をサポートします。
- コンテキストキャッシュ:長いダイアログのパフォーマンスを最適化し、重複した計算を削減します。
- 構造化出力:JSONやその他のフォーマットをサポートし、システム統合を容易にします。
- 長いコンテキストの処理:長い文書の分析に適した128Kのコンテキストの長さをネイティブでサポート。
- ストリーミング出力: リアルタイムの応答を提供し、インタラクティブな体験を向上させる。
ヘルプの使用
GLM-4.5は、GitHubリポジトリ(https://github.com/zai-org/GLM-4.5)を介してモデルの重みとツールを提供します。技術的なバックグラウンドを持つユーザーがローカルまたはクラウドで展開するのに適しています。以下は、ユーザーがすぐに始められるよう、詳細なインストールと使い方のガイドです。
設置プロセス
- 環境準備
Python 3.8以上とGitがインストールされていることを確認する。仮想環境を推奨する:python -m venv glm_env source glm_env/bin/activate # Linux/Mac glm_env\Scripts\activate # Windows - クローン倉庫
GLM-4.5のコードはGitHubから入手してください:git clone https://github.com/zai-org/GLM-4.5.git cd GLM-4.5 - 依存関係のインストール
互換性を確保するために、指定されたバージョンの依存関係をインストールします:pip install setuptools>=80.9.0 setuptools_scm>=8.3.1 pip install git+https://github.com/huggingface/transformers.git@91221da2f1f68df9eb97c980a7206b14c4d3a9b0 pip install git+https://github.com/vllm-project/vllm.git@220aee902a291209f2975d4cd02dadcc6749ffe6 pip install torchvision>=0.22.0 gradio>=5.35.0 pre-commit>=4.2.0 PyMuPDF>=1.26.1 av>=14.4.0 accelerate>=1.6.0 spaces>=0.37.1注:vLLMはコンパイルに時間がかかることがあるので、必要なければコンパイル済みバージョンを使うこと。
- モデルダウンロード
モデルの重みは、Hugging FaceとModelScopeにホストされています。以下は、GLM-4.5-Airをロードする例です:from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("zai-org/GLM-4.5-Air", trust_remote_code=True) model = AutoModel.from_pretrained("zai-org/GLM-4.5-Air", trust_remote_code=True).half().cuda() model.eval() - ハードウェア要件
- GLM-4.5-Air:16GBのGPUメモリが必要(INT4は約12GB)。
- GLM-4.5:マルチGPU環境に推奨、約32GBのRAMが必要。
- CPUの理由:GLM-4.5-Airは、32GBのRAMを搭載したCPUで動作するが、速度が遅い。
使用方法
GLM-4.5はコマンドライン、ウェブインターフェイス、APIコールをサポートし、様々なインタラクション方法を提供します。
コマンドライン推論
利用する trans_infer_cli.py インタラクティブな対話のためのスクリプト:
python inference/trans_infer_cli.py --model_name zai-org/GLM-4.5-Air
- テキストまたは画像を入力すると、モデルが応答を返します。
- 複数回の対話をサポートし、履歴を自動的に保存します。
- 例:Python関数の生成:
response, history = model.chat(tokenizer, "写一个 Python 函数计算三角形面积", history=[]) print(response)出力:
def triangle_area(base, height): return 0.5 * base * height
ウェブインタフェース
マルチモーダル入力をサポートするGradio経由でウェブインターフェースを起動します:
python inference/trans_infer_gradio.py --model_name zai-org/GLM-4.5-Air
- ローカルアドレスへのアクセス(通常は
http://127.0.0.1:7860)。 - テキストを入力するか、画像またはPDFをアップロードして、送信をクリックすると回答が得られます。
- 特徴:PDFをアップロードし、モデルを解析し、質問に答えることができる。
APIサービス
GLM-4.5は、OpenAI互換のAPIをサポートしています。 vLLM 配備:
vllm serve zai-org/GLM-4.5-Air --limit-mm-per-prompt '{"image":32}'
- リクエスト例
import requests payload = { "model": "GLM-4.5-Air", "messages": [{"role": "user", "content": "分析这张图片"}], "image": "path/to/image.jpg" } response = requests.post("http://localhost:8000/v1/chat/completions", json=payload) print(response.json())
注目の機能操作
- 混合推論モデル
- 思考パターン 数学的推論やツールの呼び出しなどの複雑なタスクに適しています:
model.chat(tokenizer, "解决方程:2x^2 - 8x + 6 = 0", mode="thinking")モデルは詳細な解決策を出力する。
- 合意形成 手っ取り早いクイズに適している:
model.chat(tokenizer, "翻译:Good morning", mode="non-thinking") - マルチモーダルサポート
- テキストや画像の入力を処理します。例えば、数学のトピックの画像をアップロードする:
python inference/trans_infer_gradio.py --input math_problem.jpg - 注:現在、画像と動画の同時処理はサポートされていません。
- テキストや画像の入力を処理します。例えば、数学のトピックの画像をアップロードする:
- インテリジェント・プログラミング
- コードを生成:完全なコードを生成するためにタスクの説明を入力します:
response, _ = model.chat(tokenizer, "写一个 Python 脚本实现贪吃蛇游戏", history=[]) - ラピッドプロトタイピングのためのコード補完とバグ修正をサポートします。
- コードを生成:完全なコードを生成するためにタスクの説明を入力します:
- コンテキストキャッシュ
- 長いダイアログのパフォーマンスを最適化し、ダブルカウントを減らす:
model.chat(tokenizer, "继续上一轮对话", cache_context=True)
- 長いダイアログのパフォーマンスを最適化し、ダブルカウントを減らす:
- 構造化出力
- システム統合を容易にするJSON形式を出力します:
response = model.chat(tokenizer, "列出 Python 的基本数据类型", format="json")
- システム統合を容易にするJSON形式を出力します:
ほら
- トランスフォーマー4.49.0を使用すると互換性の問題が発生する可能性があるため、4.48.3を推奨します。
- vLLM APIは、1回の入力で最大300枚の画像をサポートしています。
- GPUドライバがCUDA 11.8以上をサポートしていることを確認してください。
アプリケーションシナリオ
- ウェブ開発
GLM-4.5は、フロントエンドとバックエンドのコードを生成し、 最新のウェブアプリケーションの迅速な構築をサポートします。例えば、インタラクティブなウェブページを作るには、数センテンスの記述で済みます。 - 知的質疑応答(Q&A)
このモデルは複雑なクエリを解析し、ウェブ検索とナレッジベースを組み合わせて正確な回答を提供する。 - スマートオフィス
論理的なPPTやポスターを自動生成し、見出しからコンテンツを展開することができます。 - コード生成
Python、JavaScriptなどでコードを生成し、迅速なプロトタイピングとバグ修正のための反復開発を複数回サポートします。 - 複雑な翻訳
長文の学術文書や政策文書を、出版物や国境を越えたサービスに適した意味的一貫性とスタイルで翻訳する。
QA
- GLM-4.5とGLM-4.5-Airの違いは何ですか?
GLM-4.5(3,550億パラメータ、320億アクティブ)は高性能推論に適しており、GLM-4.5-Air(1,060億パラメータ、120億アクティブ)は軽量で、リソースに制約のある環境に適している。 - 推理のスピードを最適化するには?
GPUアクセラレーションを使用するか、INT4定量化を有効にするか、またはGLM-4.5-Airを選択して、必要なリソースを削減する。 - 商業利用は可能か?
はい、MITライセンスは自由な商用利用を認めています。 - 長いコンテクストをどのように扱っていますか?
128Kコンテキストのネイティブサポートyarnパラメータはさらに拡張できる。






























