



Fake News Detectorは、ファクトチェックに基づく自動フェイクニュース検出システムである。 人工知能技術、特に大規模言語モデル(LLM)と高度な埋め込みモデルを使用して、ニュース・テキストの真実性を分析する。その中核となるワークフローは、まずユーザーが入力したニュース・コンテンツから、検証が必要な核となる考え方や発言を自動的に識別し、抽出することである。次に、検索エンジンを使ってインターネットにアクセスし、関連する証拠情報を見つける。ニュースの記述と検索された証拠情報を比較・分析することにより、システムは最終的にニュースの真実性について「正しい」「間違っている」「部分的に正しい」といった判断を下します。システムは最終的に、ニュースの真実性について「正しい」、「間違っている」、「部分的に正しい」といった判断を下し、判断の根拠と推論プロセスを示す。システム全体はビジュアルなウェブインタフェースで操作され、ユーザーは各ステップでの検証の進捗状況を直感的に確認することができる。
機能一覧
- コア・ステートメントの自動抽出複雑なニューステキストから、検証が必要な最も重要な核となる事実を自動的に識別し、抽出します。
- リアルタイムのウェブ検索このシステムはDuckDuckGo検索エンジンに接続されており、抽出されたコア・ステートメントを基に、関連記事やレポートなどを支援資料としてリアルタイムでインターネット検索することができる。
- セマンティック・マッチング分析BGE-M3エンベッディング・モデルは、ニュースの記述とウェブ上の証拠との間の意味的な相関関係を計算するために使用され、発見された証拠が検証されるべき視点の内容と高度に関連していることを保証した。
- 長文の証拠処理:: 検索された証拠資料が長すぎる場合、システムは自動的にそれを小さな段落に分割し、中核となる陳述に最も関連性の高い証拠の断片をフィルタリングします。
- 信頼できるファクトチェック: : 発見された証拠に基づき、システムは総合的な判断を下し、「正しい」、「正しくない」、「部分的に正しい」の検証結論を出し、その結論に至った推論プロセスを説明する。
- オペレーター・インターフェースの視覚化Streamlitを通じて、陳述書抽出から証拠検索、最終判定まで、プロセスの全ステップをリアルタイムで確認できるユーザーフレンドリーなウェブインターフェースを構築。
ヘルプの使用
このツールは、ユーザーが自分のコンピューターに導入する必要のあるアプリケーションで、直接アクセスできるウェブサイトは持っていないため、インストールと起動を完了するには、基本的なプログラミングの知識が必要です。
事前準備
インストールを開始する前に、お使いのコンピュータが以下の条件を満たしていることを確認する必要があります:
- PythonのインストールPythonのバージョン3.12がインストールされている必要があります。インストーラはPythonのウェブサイトからダウンロードできます。
- 大規模言語モデリング(LLM)例えば、ローカルにデプロイできる大規模な言語モデルが必要です。
Qwen2.5またはOpenAI APIインターフェースと互換性のあるその他のモデル。これが、システム全体を動かす分析と判断の核となる。 - モデルの埋め込み準備するもの
BGE-M3埋め込みモデルは、ウェブからダウンロードしてローカルに展開するか、API経由でリモートから呼び出します。このモデルは主にテキスト間の類似性を分析するために使用される。
インストール手順
- クローン・コード・リポジトリ
まず、Gitツールを使ってGitHubからプロジェクトのソースコードをコンピューターにダウンロードする必要があります。コンピューターのターミナル(WindowsではコマンドプロンプトまたはPowerShell、macOSやLinuxではターミナル)を開き、以下のコマンドを入力します:git clone https://github.com/CaptainYifei/fake-news-detector.gitコマンドを実行すると、コードは次の名前のファイルにダウンロードされる。
fake-news-detectorフォルダに入る。次に、このフォルダに入る:cd fake-news-detector - 依存ライブラリのインストール
プロジェクトの実行は、多くのサードパーティの Python ライブラリに依存しています。requirements.txtを使うことができます。ファイルにはpipツールは、ワンクリックで必要なすべてのライブラリをインストールします。ターミナルで以下のコマンドを実行する:pip install -r requirements.txtこのプロセスは、必要なすべてのソフトウェアライブラリを自動的にダウンロードしてインストールするため、時間がかかる場合があります。
- モデルパスの設定
インストールが完了したら、プログラムにあなたのBGE-M3埋め込みモデルが保存されている場所。- プロジェクトフォルダを
fact_checker.pyファイルを作成し、コード・エディターで開く。 - ファイル内の次のコード行を見つける:
self.embedding_model = BGEM3FlagModel('/path/to/your/bge-m3/') - コード内にパスを配置する
'/path/to/your/bge-m3/'自分自身のものを保存するために修正するBGE-M3モデルの実際のフォルダパス。リモートAPIを使用している場合、使用しているモデルサービスプロバイダの要件に従って、コードのこの部分を修正する必要があります。
- プロジェクトフォルダを
アプリケーションを起動する
すべての設定が終わったら、このフェイク・ニュース検出ツールを起動することができる。プロジェクトのルート・ディレクトリ (fake-news-detectorフォルダ)を開き、ターミナルで以下のコマンドを実行する:
streamlit run app.py
コマンドが実行されると、プログラムは自動的にブラウザで新しいページを開きます。http://localhost:8501. これがツールのインターフェイスだ。
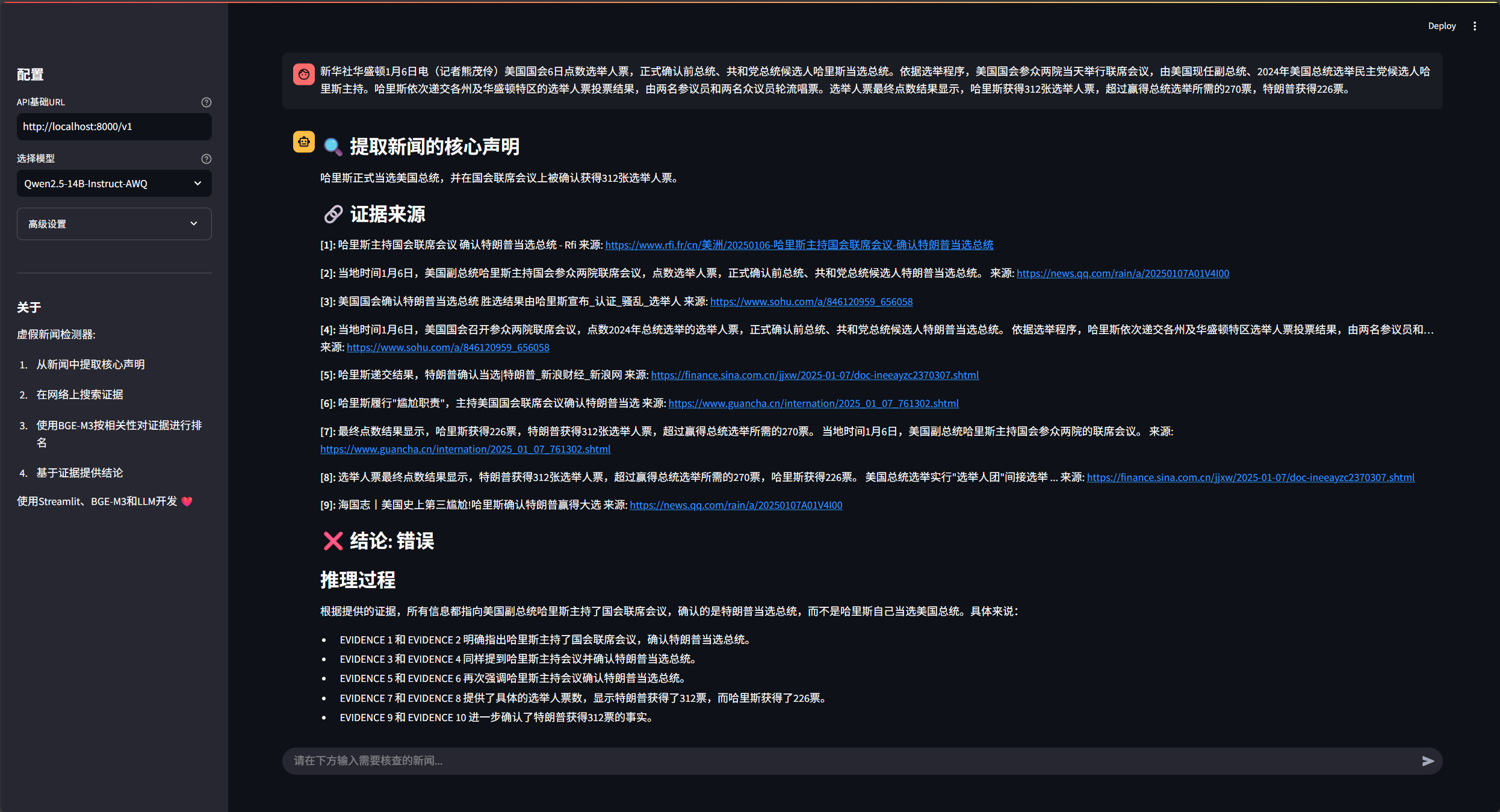
仕組み
アプリが起動すると、すっきりとしたウェブ・インターフェイスが表示される。
- インターフェイス上でテキスト入力ボックスを探す。
- 真偽を確認したいニュース項目の全文をコピーして、この入力ボックスに貼り付けてください。
- 検証開始」または同様のボタンをクリックする。
- システムはすぐに作動を開始し、インターフェイス上でリアルタイムで更新される検証プロセスを見ることができます:
- このニュースの核心部分を抜粋すると...。
- 関連する証拠を探す...
- エビデンスは、声明との関連性について分析されている...
- ファクトチェックの結論が出されている...。
- 最後に、システムは最終的な検証結果(正しい、正しくない、部分的に正しい)を、証拠や分析プロセスへの関連リンクとともに表示し、その結論に至った経緯を示します。
アプリケーションシナリオ
- 個人ユーザーによる情報の迅速な選別
ソーシャルメディアやウェブ上で不確かなニュース記事を目にした場合、このツールを使って素早く事実確認を行うことができる。ユーザーは、ニュースのテキストをコピーしてツールに貼り付けるだけで、オンライン上の証拠に基づいた最初の判断を得ることができ、噂に惑わされることを避けることができる。 - ジャーナリスト支援
ジャーナリスト、編集者、その他の報道関係者にとって、このツールは効率的な支援となる。ニュースの一部を報道したり引用したりする前に、真偽の事前審査を行ったり、関連する裏付け資料を素早く見つけたり、矛盾点を発見したりするのに利用できる。 - コンテンツ・プラットフォーム情報レビュー
ソーシャルメディアプラットフォームやコンテンツアグリゲーションサイトなどは、同様のテクノロジーを統合することで、プラットフォーム上の大量の情報のレビューを自動化することができる。ユーザーによって投稿されたコンテンツをリアルタイムで分析することで、潜在的な偽情報を素早く特定し、フラグを立てることができ、噂の範囲を縮小し、プラットフォーム・コンテンツの健全な生態系を維持することができる。
QA
- ニュース検出ツールはどの言語をサポートしていますか?
このツールは、Large Language Model(LLM)とその背後にある組み込みモデルの機能に大きく依存している。理論的には、設定されたモデル(Qwen2.5やBGE-M3など)が多言語処理をサポートしていれば、ツールは対応する言語のニューステキストも処理できる。現在のところ、中国語と英語が主な対象である。 - 検査結果は完全に信頼できるのか?
完全に信頼できるものではありません。このツールの検出結果は、AIモデルがウェブ上で公開されている情報を検索・分析したものであり、非常に貴重な参考資料として利用できますが、100%の正確性を保証するものではありません。結果の精度は、検索エンジンが見つけることができる証拠の質と、ビッグ・ランゲージ・モデル自体の判断能力に影響される。非常に重要な情報の検証のために、ユーザーはこのツールの結果を補助として使用し、他の複数の証拠ソースと組み合わせることをお勧めします。 - 私はプログラマーではありませんが、このツールを使えますか?
プログラミングの素養がないユーザーにとっては、コードのダウンロードや環境設定、ローカルコンピューターでの起動が必要なため、プロジェクトを直接利用するのは難しいだろう。現在のところ、このプロジェクトは一般向けのオンラインウェブサイトを提供しておらず、一定の技術的基盤を持つ開発者や研究者を主な対象としている。


























