

大規模言語モデル(LLM)に基づく知識ベースクイズアプリケーションを構築する際、開発者は一般的に検索拡張生成(RAG)技術を採用している。しかし、RAGの実用的な有効性は、しばしば中心的なパラドックスによって制限される。精度文脈的完全性テキストチャンクが小さすぎる場合、ユーザーのクエリを正確にヒットさせることはできますが、LLMに十分なコンテキストを提供できないため、回答の質が低下します。テキストのスライス(チャンク)が小さすぎる場合、ユーザーのクエリを正確にヒットすることはできますが、LLMに提供されるコンテキストが不十分で、回答の品質が低下します。
この課題に対処するためだ。 Dify という新機能としてバージョン1.9.0で導入された。 Parent-child-HQ 組み込みの知識処理パイプラインテンプレート。このテンプレートは「親子チャンキング」(Parent-Child Chunking)戦略を採用し、巧みな階層チャンキング方法を通じて、魚と熊の前足の両方を同時に実現しようとしている。本稿では、3つのレベルのコアコンセプト、練習構成、ソースコード実装からこの機能を分析する。
コアコンセプト:父子チャンキング戦略
親子チャンキング」戦略の核となる考え方は、テキスト情報を2つのレベルに構造化して処理することで、検索マッチングとコンテンツ生成の間でテキストの粒度に対する異なる要求を切り離すことである。
- 完全一致のための子チャンク元の文書は、一連のきめの細かい、非常に集中した「サブ・チャンク」に分割される。これらのサブチャンクは通常、一文か短い段落であり、ユーザーのクエリーベクトルとの意味的類似度計算にのみ使用される。粒度が小さいため、非常に正確なマッチングを達成することができる。
- 親チャンクは、完全なコンテキストを提供するために使用されます。各サブチャンクはより大きな「親」に属し、それは完全な段落であったり、セクションであったり、あるいは文書全体であったりする。システムが子チャンクを通して最も関連性の高いマッチに的を絞った後、実際にコンテンツ生成のためにLLMに供給されるのは、子チャンクを含む完全な「親チャンク」である。
このメカニズムにより、LLMは質問に答える際に、一致する情報が存在する最も完全な元の文脈を「読み取る」ことができ、論理的に首尾一貫した有益な応答が生成される。
この高度な戦略は、意味的類似性を計算するためにベクトル検索に依存しているため、Difyの知識ベースのみをサポートしています。 HQ(ハイクオリティ) インデックス作成モード。一方、経済的なモードでは、キーワードに基づく転置インデックスを構築するだけであり、親子チャンキングの運用要件を満たすことはできない。

実践ガイド:親子本部ナレッジベースの設定
Difyでこの機能を使うには、まず Parent-child-HQ この知識ベースはプロセス・テンプレートを扱います。
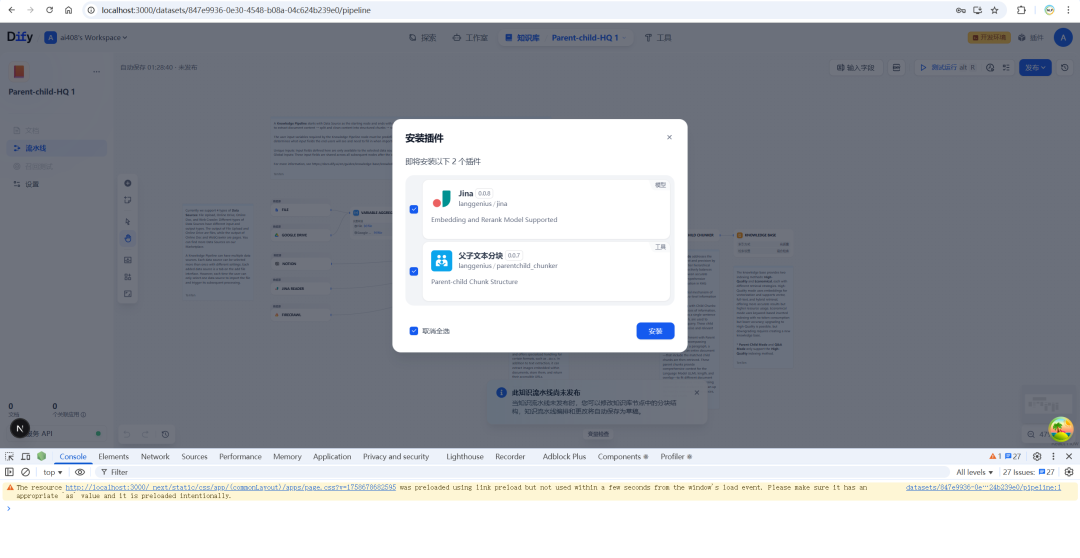
インストール後、パイプラインの最も中心的なノードは「親子テキストチャンク」である。
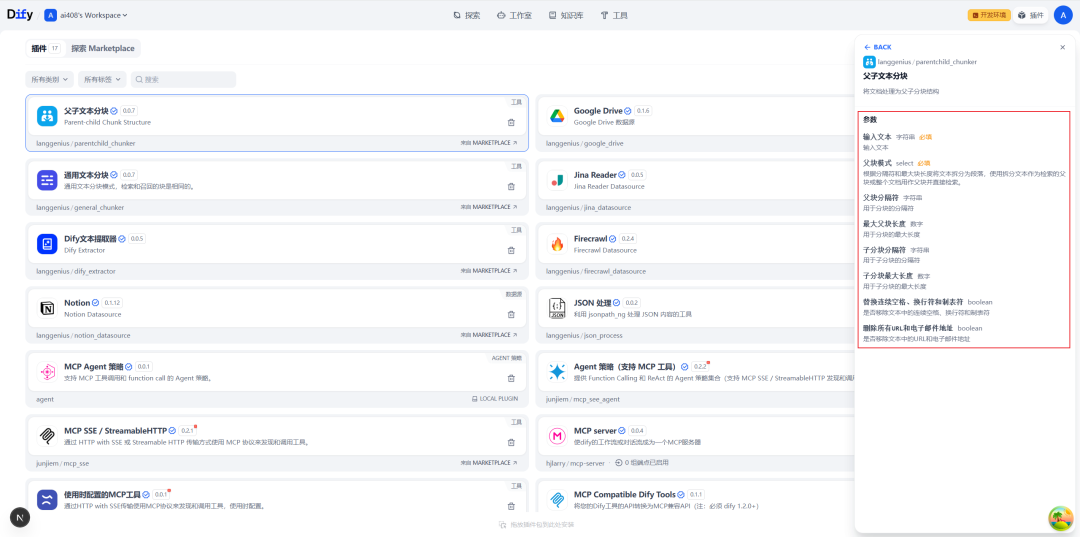
チャンキング・ノードの構成
このノードの設定画面では、親ブロックと子ブロックの分割ルールを詳細に定義することができます。
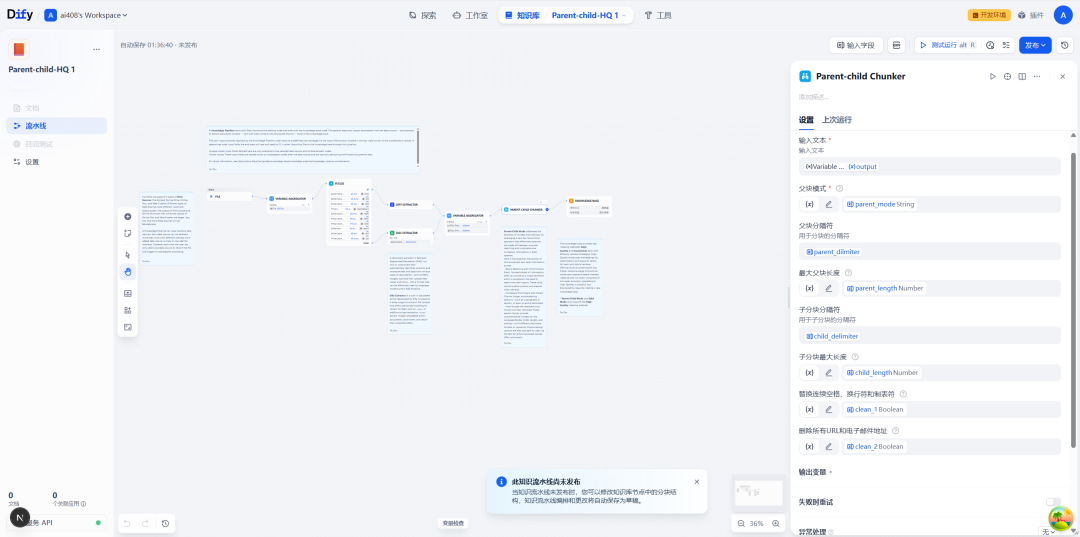
| 設定項目 | 指示 |
|---|---|
| 親チャンクセパレータ | 親ブロックをスライスする方法を定義する。これは通常 \n\n(改行2つ)で段落を分割する。 |
| 親チャンクの最大長 | 1つの親ブロックの最大文字数。 |
| サブチャンクセパレーター | 親ブロック内のサブブロックをさらにスライスする方法を定義します。これは \n(改行 1 文字) 行で分割する。 |
| 最大サブチャンク長 | 1つのサブブロックの最大文字数。 |
| 親ブロックモデル | 親ブロックのスコープを定義する。 paragraph(段落)と full_doc(完全なドキュメント)2つのモード。 |
この場合、「親ブロックパターン」がコンテキストのマクロ境界を決定する:
- 段落パターン(
paragraph mode)テキストをセパレータ(段落など)で複数の親ブロックに分割します。これは最もよく使われるモードで、精度と文脈の範囲のバランスがとれています。 - 全文モード (
full_doc mode)文書全体を1つの巨大な親ブロック(10,000以上)として扱う。 tokens (切り捨てられる部分)。このモードは、グローバル・コンテキストが必要な特定のシナリオに適している。
さらに、前処理オプションは、データ品質を向上させるために、テキストから余分なスペース、URL、電子メールアドレスの除去をサポートする。
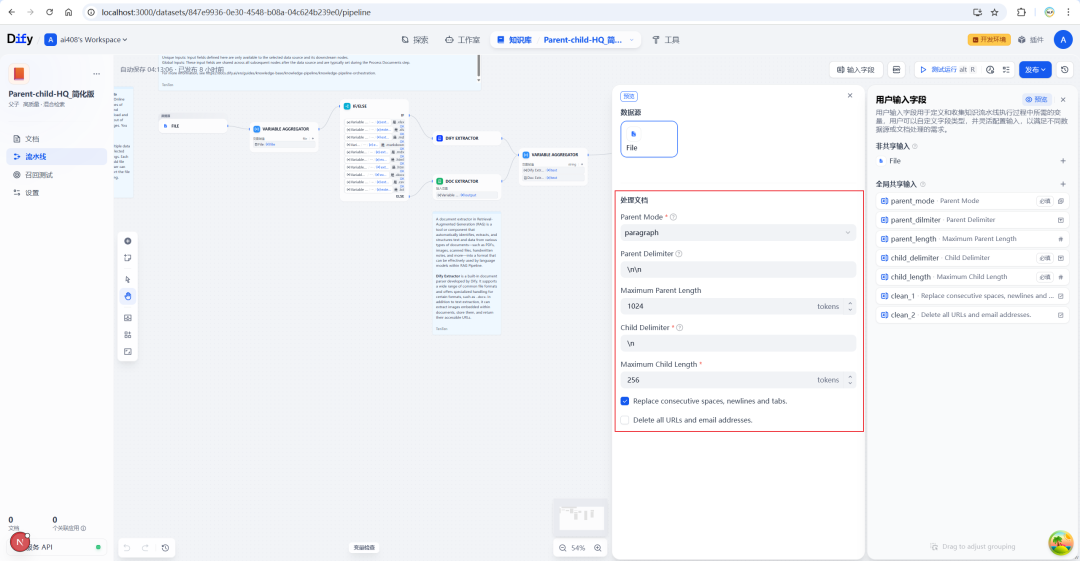
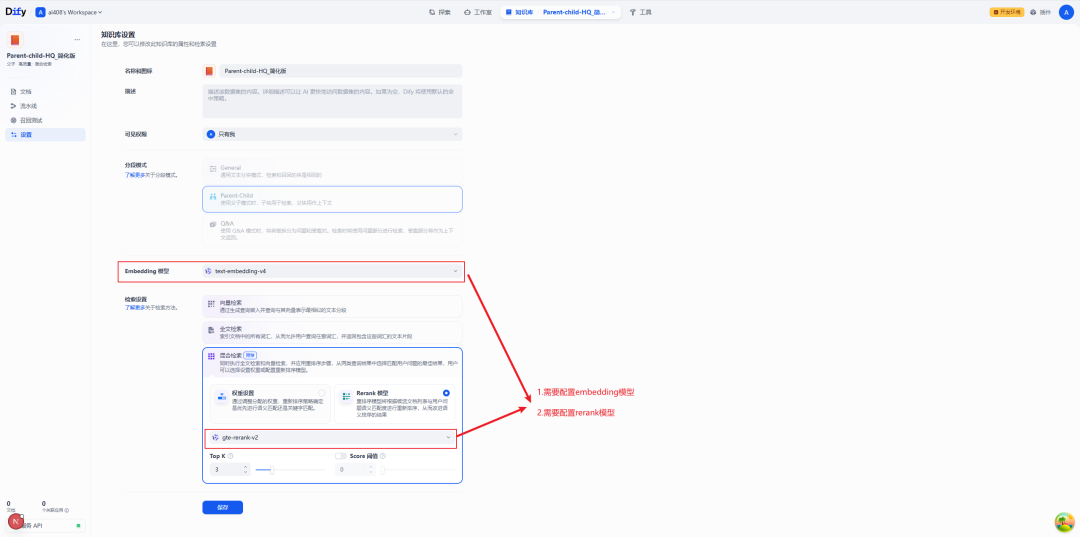
高品質インデックスの設定
前述の通りだ。Parent-Child このモデルはHQインデックスと組み合わせて使用する必要があります。そのため、知識ベース設定で埋め込みモデルと再ランクモデルを設定する必要があります。
試運転と操作
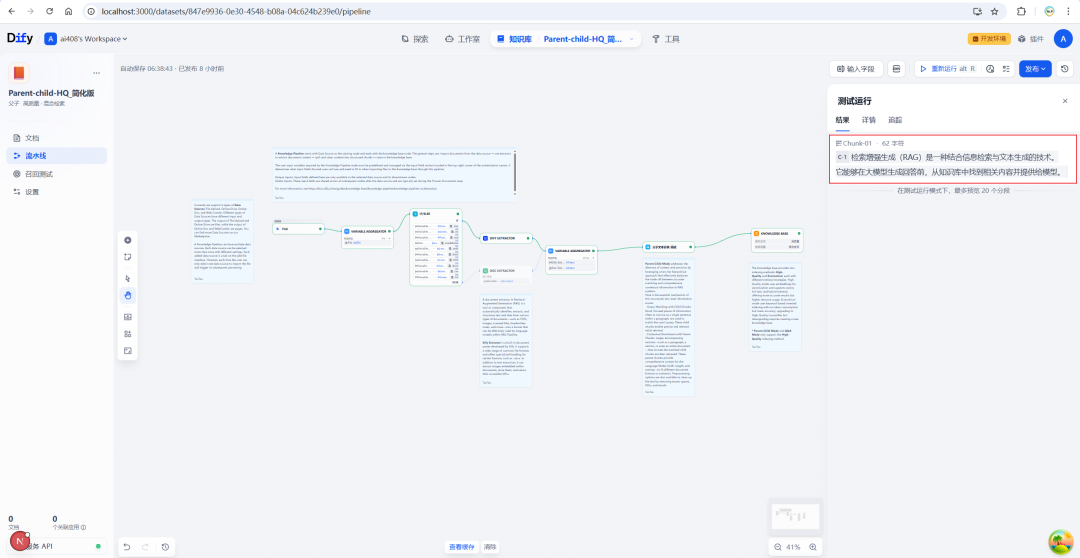
すべての設定が完了したら、デバッグ機能を使ってチャンキング効果をテストできます。サンプルテキストを入力してパイプラインを実行すると、元のテキストがどのように親子構造に整理されるかを明確に確認できます。
最終的な実行結果は、親ブロックとそれが含む子ブロックのリストの構造化されたプレゼンテーションとなる。
アーキテクチャの深層:コードレベルでの実装ロジック
その仕組みをよりよく理解するために、私たちは次のようなことに取り組んでいる。 parentchild_chunker プラグインのソースコードを分析する。以下のUMLタイミング図は、プラグインの起動からデータの受信、処理、結果の返送までの完全なフローをまとめたものです。
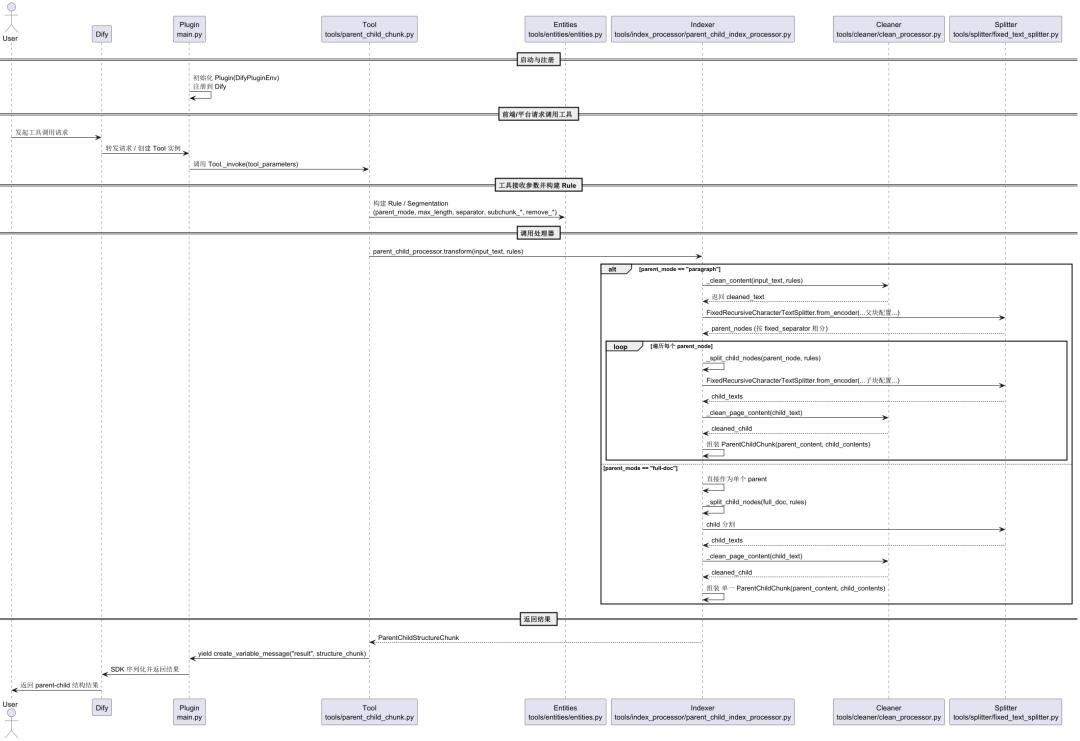
データ処理プロセス全体を要約すると、次のような主要ステップになる:
1.プラグインの起動とツールの呼び出し
ディファイのプラットフォームが立ち上がるときmain.py ファイルは、プラグインのエントリーポイントとして機能し、Difyの初期化と登録を行います。 ParentChildChunkTool ツールの機能ツールのフロントエンドのフォーム、入力パラメータ、出力フォーマットは tools/parent_child_chunk.yaml ファイルの定義
ユーザーがツールを起動すると、Dify SDK は tools/parent_child_chunk.py で定義されている。 ParentChildChunkTool クラスを呼び出し _invoke メソッドで、フロントエンドから渡されたパラメータ(たとえば input_text、parent_mode 等)が渡された。
2.コア処理とテキストクリーニング
_invoke このメソッドの中心的な責任は tools/index_processor/parent_child_index_processor.py で定義されている。 ParentChildIndexProcessorビジネス・ロジック全体の軸となるもの。これはビジネスロジック全体のピボットです
チャンキングの前に、テキストはまず tools/cleaner/clean_processor.py 正鵠を得る CleanProcessor クリーニング。このモジュールは、無効な文字を削除し、ユーザーの設定に従って冗長なスペースを選択的にマージしたり、URLや電子メールアドレスを削除したりする役割を果たし、その後に処理されるテキストの品質を保証します。
3.インテリジェントなテキストセグメンテーション
テキストのセグメンテーションは、親子チャンキング戦略の技術的な中核であり、主に次のような方法で行われる。 tools/splitter/ カタログには複数のスプリッター実装が掲載されている。その中でもFixedRecursiveCharacterTextSplitter が鍵だ。
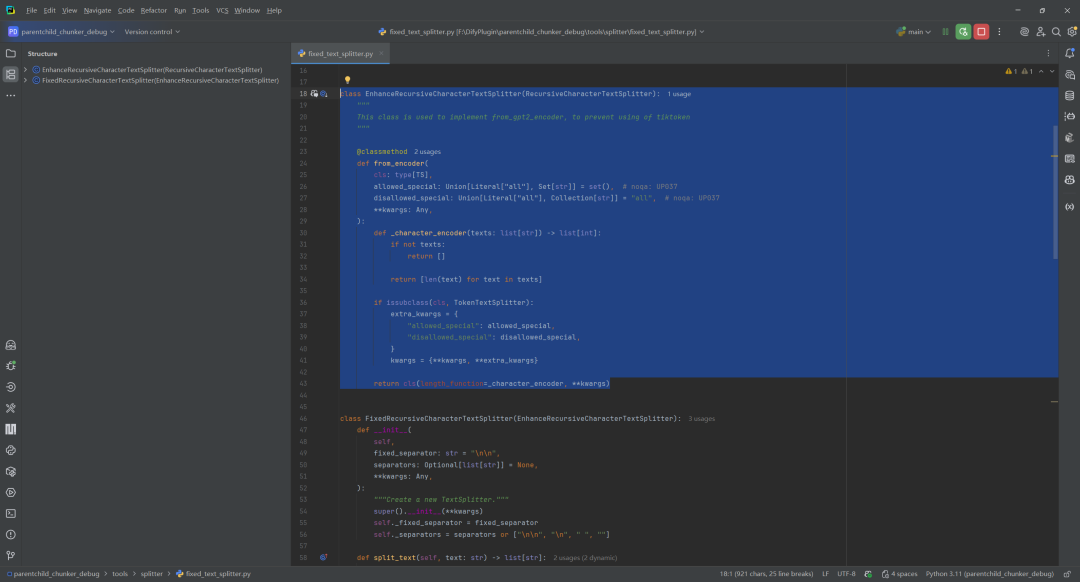
ここで2つの重要なクラスを区別する必要がある:
EnhanceRecursiveCharacterTextSplitterその主な改良点は、文字数に基づいて新しいシステムを作成する方法を提供することである。tiktoken) は、特定のトークナイザーに依存する必要がないように、テキストの長さを計算します。セグメンテーションロジックは、標準的な再帰的文字セグメンテーション機能と一致しています。FixedRecursiveCharacterTextSplitterこのクラスは、再帰的パーティショニングに重要なステップを追加します。まず、優先順位の高い固定されたfixed_separator(例えば\n\n)を使って最初の分割を行う。.その後、内部の再帰ロジックが再度呼び出され、長さの制限を超えるブロックだけが細分化される。
この "粗く分割し、次に細かくする "という戦略は、親子チャンキングのニーズに完璧にマッチしている。 \n\n 意味的に完全な親ブロック(段落)を分割し、親ブロック内でより細かい区切り文字を使う(例えば \n) サブブロックを切り出す。
4.データ構造の構築と返却
洗浄・分割後ParentChildIndexProcessor に基づいている。 paragraph 或 full-doc このパターンは、親ブロックの内容とそれに対応する子ブロックの内容のリストを ParentChildChunk オブジェクトにカプセル化される。これらのオブジェクトは最終的に ParentChildStructureChunk 構造体
これらのデータ構造の定義は tools/entities/entities.pyパイダンティック・モデルを使用することで、データが正規化され、一貫性が保たれる。
最後にParentChildChunkTool とおす yield self.create_variable_message(...) 処理された構造化データはDify SDKに返され、パイプラインノード全体の実行が完了します。
このよく設計された処理フローと柔軟なテキスト分割機能によりParent-child-HQ テンプレートは、以下の問題を効果的に解決するパワフルでエレガントなツールを開発者に提供する。 RAG アプリケーションにおける永続的なコンテキストと精度のトレードオフのジレンマ。



























