



DeepSieveはGitHubでホストされているオープンソースのRAG(Retrieval Augmented Generation)フレームワークで、複雑なクエリとマルチソースデータの処理に焦点を当てています。MinghoKwok氏によって開発されたDeepSieveは、構造化データ(SQLテーブル、JSONログなど)や非構造化データ(Wikipediaなど)の処理をサポートしており、多段階の推論を必要とするシナリオに適している。モジュール設計に重点を置いており、ユーザーは必要に応じて機能を調整することができるため、研究者や開発者が複雑なデータ分析タスクを処理するのに適している。このプロジェクトは2025年7月29日にarXivにプレプリントとして公開され、完全なコーパスはArkivにアップロードされた。
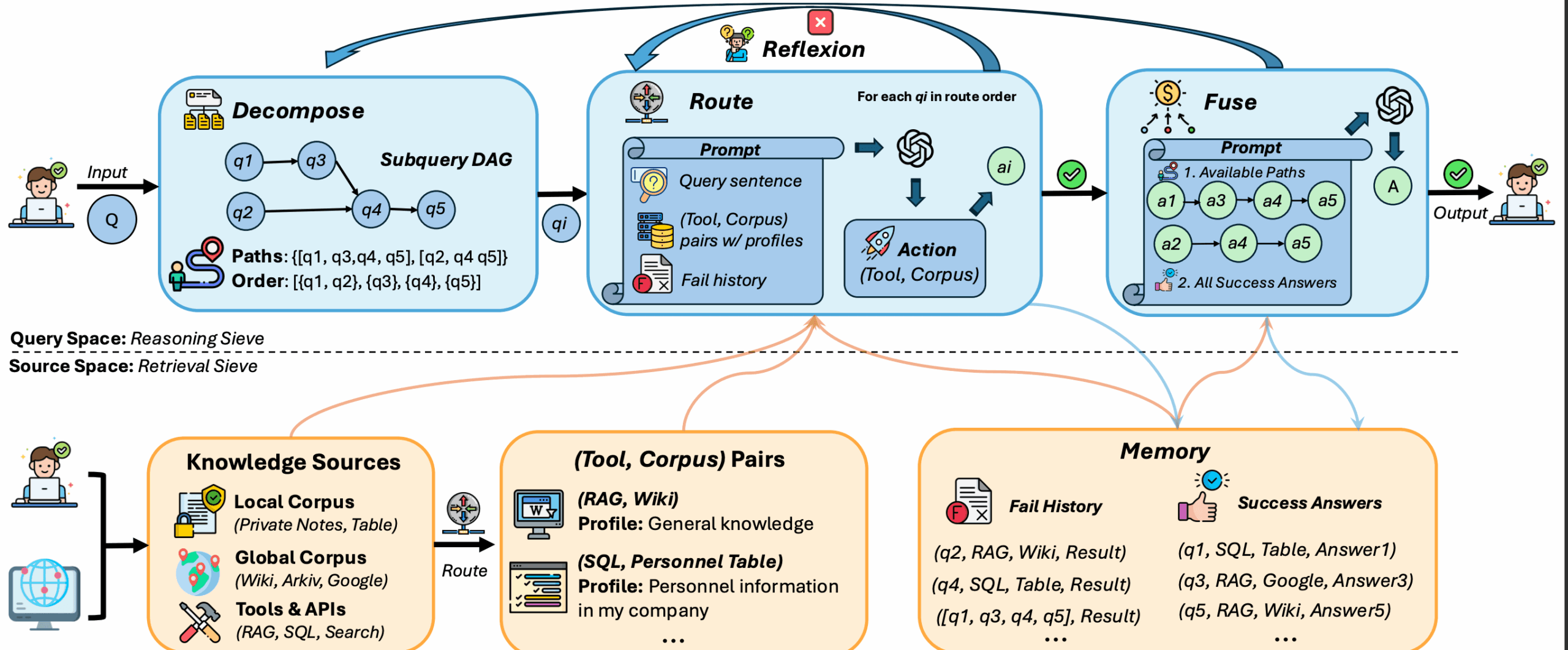
機能一覧
- クエリの分解 複雑なクエリを複数の単純なサブ問題に分割し、的確な処理を行う。
- サブイシューのルーティング サブクエスチョンを適切なツールやデータソース(ローカルデータベースやグローバルナレッジベースなど)にインテリジェントに割り当てる。
- 反射メカニズム 失敗した検索を自動的に検出し、再試行します。
- 答えの収束 サブクエスチョンの回答を統合し、最終的な完全回答を作成する。
- 複数のデータソースをサポート SQLテーブル、JSONログ、ウィキペディアなどの異種データを扱う。
- 2つのRAGモード 検索モードはシンプル(Naive)とグラフ構造(Graph)の2種類で、さまざまなニーズに対応できる。
- 詳細ログ 各クエリの中間結果、フュージョンヒント、パフォーマンスメトリクスを保存し、デバッグや最適化を容易にします。
- モジュール設計 機能モジュールの有効・無効は、コマンドラインスイッチで柔軟に切り替えることができます。
ヘルプの使用
設置プロセス
DeepSieveはPythonベースのオープンソースプロジェクトです。詳しい手順は以下の通りです:
- クローン倉庫
ターミナルで次のコマンドを実行して、DeepSieveリポジトリをローカルにクローンします:git clone https://github.com/MinghoKwok/DeepSieve.gitプロジェクト・カタログにアクセスする:
cd DeepSieve - 依存関係のインストール
このプロジェクトはPython 3.7+と関連する機械学習・データ処理ライブラリに依存している。依存関係をインストールしてください:pip install -r requirements.txt万が一
requirements.txt提供されていないため、コア・ライブラリの手動インストールを推奨:pip install numpy pandas scikit-learn openai依存関係の衝突を避けるため、仮想環境を使用することを推奨する:
python -m venv venv source venv/bin/activate # Linux/macOS venv\Scripts\activate # Windows - 環境変数の設定
DeepSieveは、Large Language Model (LLM)を使用して、APIキーの設定が必要なクエリを処理します。例えば DeepSeek モデルexport OPENAI_API_KEY=your_api_key export OPENAI_MODEL=deepseek-chat export OPENAI_API_BASE=https://api.deepseek.com/v1使用モード(NaiveまたはGraph)に応じて、以下のように設定する。 RAG タイプ
export RAG_TYPE=naive # 或 graph - 検証環境
すべての依存関係が正しくインストールされ、APIキーが有効であることを確認する。カスタム・データ・ソースを使用している場合は、データ・ファイルのパスが正しく設定されていることを確認する。
DeepSieveの実行
DeepSieveはコマンドラインから実行でき、柔軟なパラメータ設定が可能です。以下に基本的な使用方法を示します:
ナイーブRAGモデル
Naiveモードは単純な作業に適している:
export RAG_TYPE=naive
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
--datasetデータセットを指定する。hotpot_qa)。--sample_size処理サンプル数を設定する。--decomposeクエリの分解を有効にする。--use_routingサブイシューのルーティングを有効にする。--use_reflection反射的なメカニズムを可能にする。--max_reflexion_times最大反射回数を設定。
グラフRAGモード
グラフ・モードは複雑なクエリに適しており、グラフ構造のサポートが必要である:
export RAG_TYPE=graph
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
モジュールを無効にする
ユーザーは、コマンドラインパラメーターを削除することで、機能を無効にすることができる。例
- クエリ分解を使用しない:削除
--decompose。 - ルートを使用しない:削除
--use_routing。 - 使用されていない反射:削除
--use_reflection。
出力結果
以下のファイルが各走行ごとに生成される:
- 各クエリの結果
outputs/{rag_type}_{dataset}/query_{i}_results.jsonl - フュージョンのヒント
outputs/{rag_type}_{dataset}/query_{i}_fusion_prompt.txt - 総合的なパフォーマンス指標:
overall_results.txt和overall_results.json
主な機能
クエリの分解
DeepSieveは、複雑なクエリをサブ問題に分割します。例えば、「2023年の会社の売上高と従業員数」というクエリは、次のように分割されます:
- 小問1:2023年の会社の売上高を求めよ。
- 小問2:ある会社の従業員数を求めよ。
操作手順:
- スクリプトやコマンドラインにクエリを入力する。
- スクリプトを実行すると、DeepSieveは自動的にクエリを分解し、サブ問題を表示します(ログで表示可能)。
サブイシューのルーティング
各サブクエスチョンは、適切なツールまたはデータソースに割り当てられている。例
- 構造化データ(SQLテーブルなど)がデータベースクエリーツールにルーティングされる。
- 非構造化データ(ウィキペディアなど)をテキスト検索ツールにルーティング。
ユーザが手動で指定する必要はなく、DeepSieveが自動的にルーティングを行います。ログファイルの確認query_{i}_results.jsonlルートの詳細を見ることができる。
反射メカニズム
サブ項目の検索に失敗した場合、DeepSieveは自動的に最大2回まで再試行します。再試行のプロセスはログに記録され、ユーザは失敗の理由と再試行の結果を確認できます。
答えの収束
DeepSieve は、サブ質問の回答を統合して、最終的な回答を生成します。たとえば、上記の会社に関するクエリの回答は、以下のように統合されます:
- "2023年、この会社の売上高はXドル、従業員数はY人になる"
フュージョンチップはquery_{i}_fusion_prompt.txtこれはユーザーが簡単にチェックできる。
使用上の注意
- データ準備 エンコードエラーを避けるため、入力データが正しいフォーマット(CSVやJSONなど)であることを確認してください。
- APIキー LLM API キーが有効であること、ネットワーク接続が安定していることを確認してください。
- ログチェック 走行後の表示
outputs/カタログを作成し、パフォーマンス・メトリクスとエラー・ログを分析する。 - 地域支援 もし問題が発生した場合は、GitHubのIssuesページかarXivの論文を参照してください。
アプリケーションシナリオ
- 学術研究
研究者は、DeepSieveを使用して、複数のソース(例えば、ウィキペディアや実験データベース)からのデータを処理し、複雑な質問に迅速に回答します。例えば、生物学的データセットや文献中の遺伝的関連性の分析などです。 - ビジネスデータ分析
企業アナリストは、DeepSieveを使用して販売データと顧客ログを処理し、"2023年に最も売上が高く、顧客満足度の高い商品はどれか?"といった多角的な質問に答えます。. - プライバシーに配慮したシナリオ
DeepSieveはプライベートなデータソース(社内データベースなど)をサポートし、データをマージすることなくクエリを処理します。 - オープンソース開発
開発者は、DeepSieveのモジュール設計を利用して機能を拡張したり、既存のシステムに統合してカスタマイズしたデータ処理を行うことができます。
QA
- DeepSieveはどのようなデータ・ソースをサポートしていますか?
SQLテーブル、JSONログ、ウィキペディアなどのサポート、具体的なサポート範囲は、プロジェクトのドキュメントまたは設定ファイルを参照してください。 - ランタイムエラーをデバッグするには?
プローブoutputs/ディレクトリにあるログファイルを参照し、エラーの詳細を確認する。依存ライブラリのバージョンが正しく、APIキーが有効であることを確認してください。 - グラフモードとナイーブモードの違いは?
ナイーブモードは単純なクエリに適しており、高速である。グラフモードは複雑な多段階推論に適しており、精度は高いが計算コストは高くなる。 - コードを提供するには?
リポジトリをフォークしてコードを変更し、Pull Requestを提出する。CONTRIBUTING.mdコード仕様に従った文書。


























