まえがき:独自のAIエージェント・スタジオの構築
Coze Studio は、ByteDanceによってオープンソース化されたローコードAIエージェント開発プラットフォームです。開発者が最小限のコードでAIインテリジェンス、アプリケーション、ワークフローを迅速に構築、デバッグ、展開できるビジュアルツールセットを提供します。このアプローチは、技術的な敷居を低くするだけでなく、高度にカスタマイズされたAI製品を構築するための強固な基盤を提供します。
AIエージェントは、ユーザーの意図を理解し、複雑なタスクを自律的に計画・実行するインテリジェントなプログラムである。ローカルへの展開 Coze Studioつまり、データとモデルを完全にコントロールすることができ、優れたプライバシーと柔軟な開発・実験が可能になります。
プラットフォームのバックエンドは Golangフロントエンドは React + TypeScript 全体的にマイクロサービスとドメイン駆動設計(DDD)アーキテクチャに基づくこの組み合わせは、システムの高いパフォーマンスとスケーラビリティを保証する。
この記事では、以下のことを説明する。 Coze Studio オープンソース版をローカルに展開し、ローカルへの接続を設定する。 Ollama も OpenRouter モデリングサービスの
1.Ollamaの設置:自分だけの大型モデルを持つ
Ollama は、ネイティブの大規模言語モデルを実行するための軽量で拡張可能なフレームワークである。これは Llama 3, Qwen 和 Gemma その他のモデリングプロセス持つ Ollamaサードパーティのクラウドサービスに依存することなく、完全にオフラインの環境でAIを活用してプライベートデータを処理し、セキュリティとコストのバランスをとることができる。
インタビュー https://ollama.com/お使いのオペレーティングシステム(macOS、Linux、Windows)に適したクライアントをダウンロードしてインストールします。ウィザードに従ってインストールするだけです。
プルモデル
インストールが完了したら Ollama のモデルライブラリからローカルにモデルをダウンロードします。を使います。 Qwen 例えば、モデル・ライブラリには、パラメータ・スケールの異なるバージョンが用意されている。
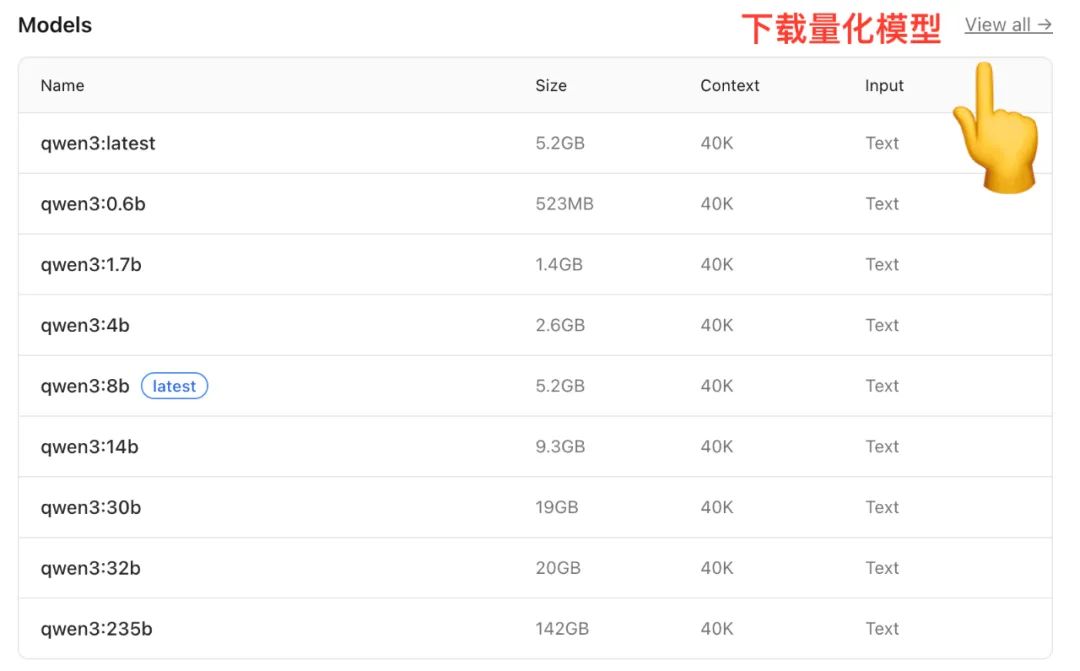
(画像出典:https://ollama.com/library/qwen)
サイズが異なれば、必要なメモリー(RAM)も異なる:
- 7Bモデル推奨16GB RAM
- 14Bモデル推奨32GB RAM
- 72Bモデル推奨64GB RAM
また、多くのモデルでは定量化 バージョン定量化とは、モデルのパフォーマンスを維持しながら重み付けの精度を下げることで、モデルのサイズとメモリフットプリントを削減する手法であり、民生グレードのハードウェアでモデルをより効率的に実行できるようにする。
端末(ターミナルまたはコマンドプロンプト)を開き、以下のコマンドを入力して中型モデルを引き抜く:
ollama run qwen:14b
このコマンドは、指定されたモデルをクラウドから自動的にダウンロードし、解凍します。正確な所要時間はネットワーク状況に依存します。
2.Dockerのインストール:アプリケーションデプロイのための標準化されたツール
Docker は、アプリケーションとその依存関係をすべて、標準的で移植可能な「コンテナ」にパッケージするコンテナ化技術だ。一言で言えばDocker 標準化された容器のようなものだ。 Coze Studio 積み込むのは貨物だによって Docker私たちは、サポートされているどのバージョンにも、簡単に新しいバージョンを追加することができる。 Docker を実行しているマシン上で Coze Studio複雑な環境設定や依存関係の衝突を心配する必要はない。
インタビュー https://www.docker.com/ダウンロードとインストール Docker Desktopまた、macOS、Linux、Windows用のグラフィカルなインストールインターフェイスも提供します。また、macOS、Linux、Windows用のグラフィカルなインストールインターフェイスも提供します。
3.コーズスタジオの現地展開
3.1 環境要件
- ソフトウェア少なくとも2コアのCPUと4GBのRAMを搭載していることを確認してください。
- ハードウェアプレインストール
Docker、Docker ComposeそしてDockerサービスが開始された。
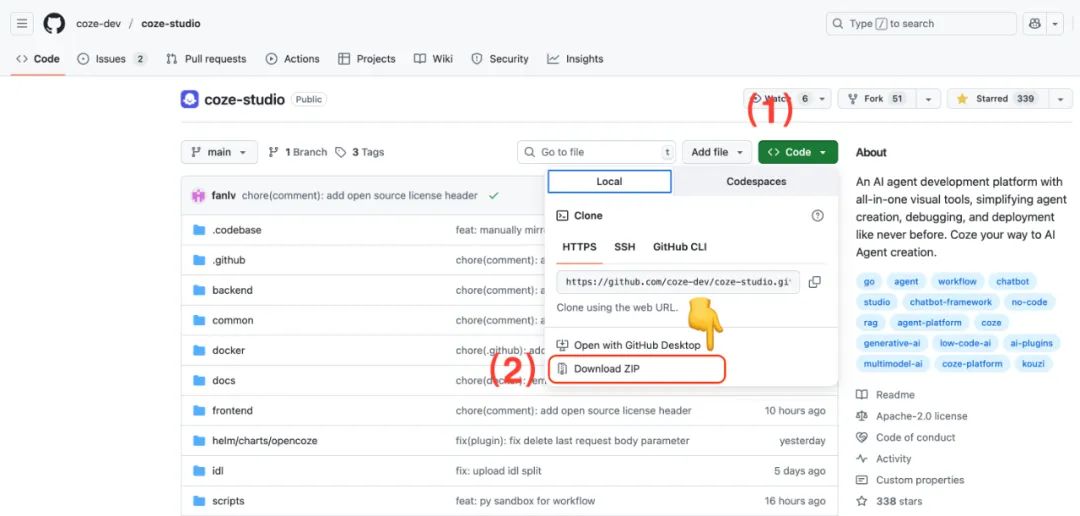
3.2 Coze Studioソースコードの入手
マシンがインストールされている場合 Git実施 git clone コマンドは、ソースコードを入手する最も直接的な方法である。
git clone https://github.com/coze-dev/coze-studio.git
未装着の場合 Gitから直接情報を得ることもできる。 GitHub ページからZIPアーカイブをダウンロードしてください。
3.3 Coze Studioのモデル設定
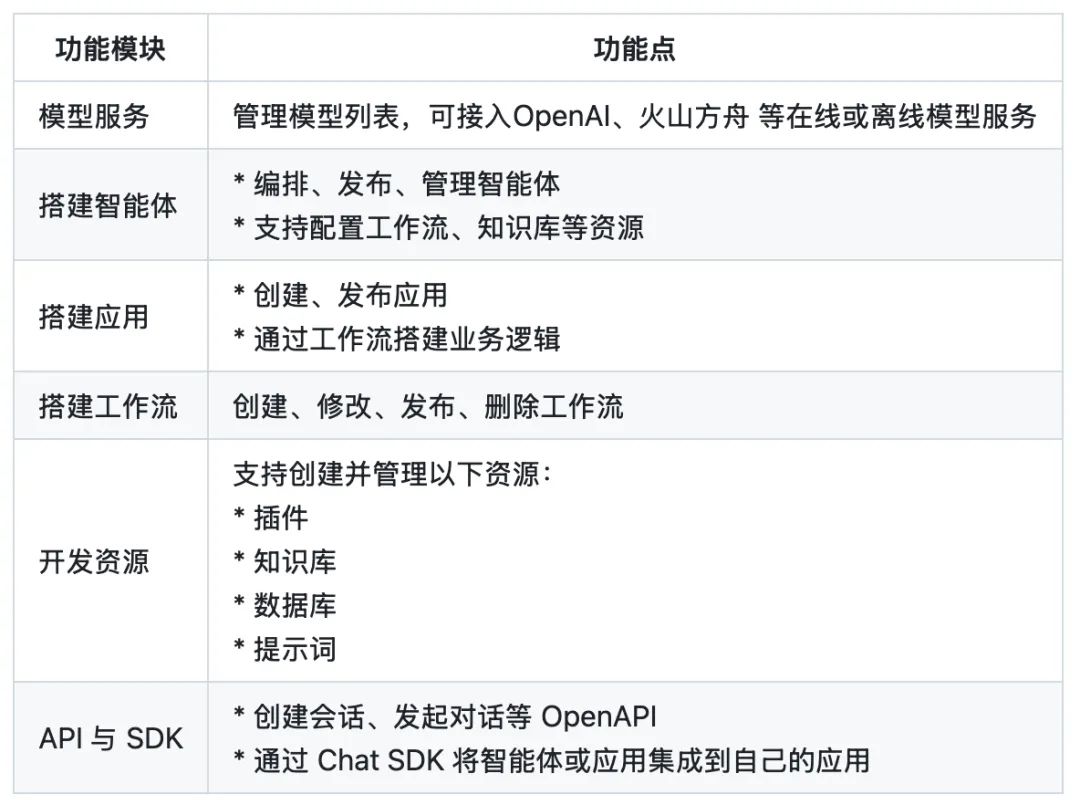
Coze Studio 以下のような複数のモデリングサービスがサポートされている。 Ark(火山の箱舟)OpenAI、DeepSeek、Claude、Ollama、Qwen 和 Gemini。
コードエディターを使って coze-studio プロジェクトで backend/conf/model/template ディレクトリに、さまざまなモデルサービスのコンフィギュレーション・テンプレートがあります。
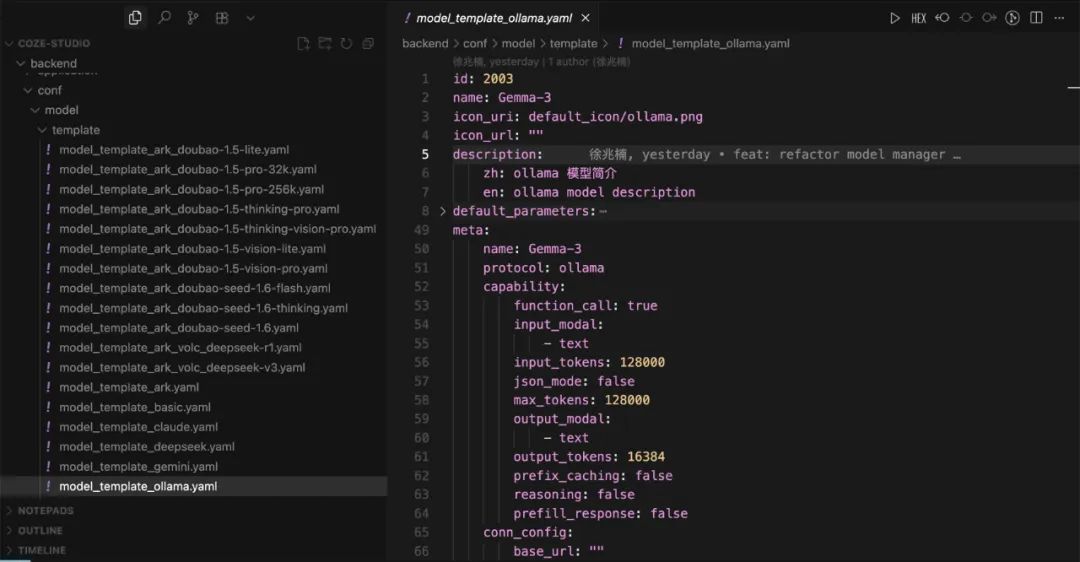
ローカルOllamaモデルの設定
- 将
model_template_ollama.yamlテンプレート・ファイルはbackend/conf/modelカタログ - 名前を変更する。
model_ollama_qwen14b.yaml。 - このファイルを編集して
qwen:14bモデルを例に挙げている:
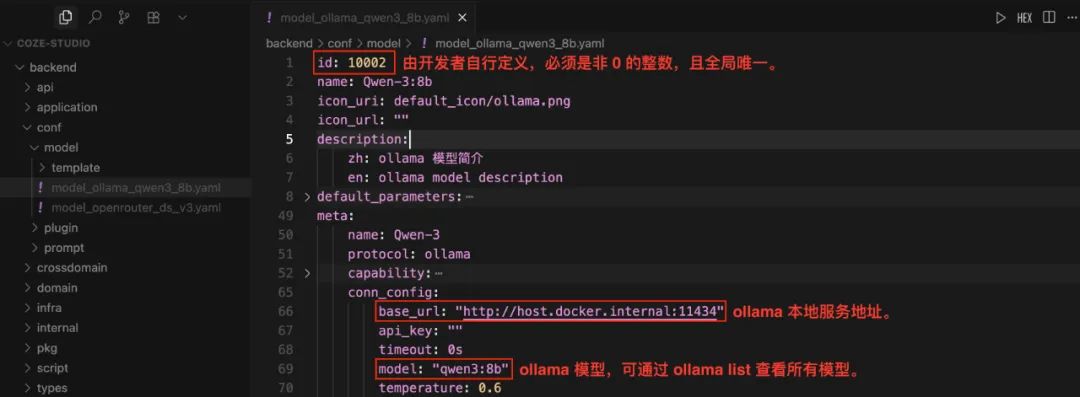
注目してほしい:id フィールドはグローバルに一意なゼロ以外の整数でなければならない。すでにオンラインになっているモデルについては、その idそうでなければ、呼び出しは失敗する。コンフィギュレーションの前に ollama list コマンドを使って、ローカルで利用可能なモデルを表示する。
OpenRouter モデルの設定
OpenRouter これは、開発者が統一されたAPIインターフェースを通じて異なるベンダーの複数のモデルを呼び出すことを可能にするモデルアグリゲーションサービスであり、APIキーの管理とモデルの切り替えプロセスを簡素化する。
- 将
model_template_deepseek.yamlテンプレート・ファイルはbackend/conf/modelカタログ - リネーム
model_openrouter_ds_v2.yaml。 - ファイルを編集して
DeepSeek-V2例として、以下の情報を記入する。OpenRouter後天的api_key。
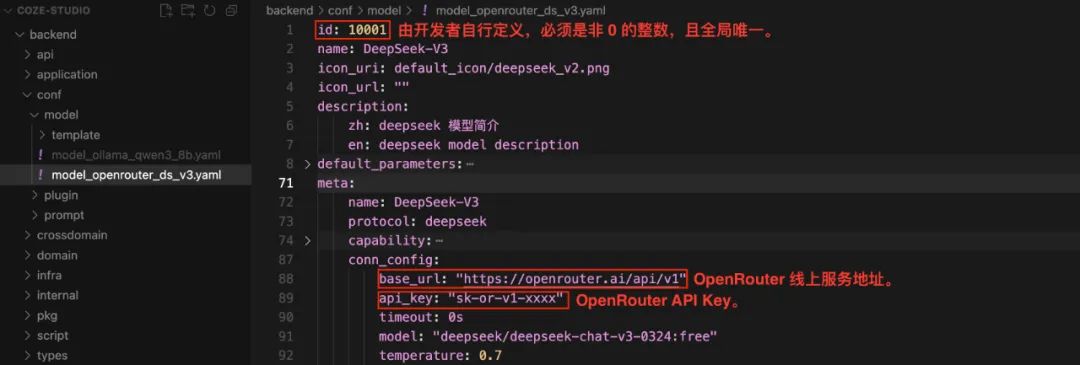
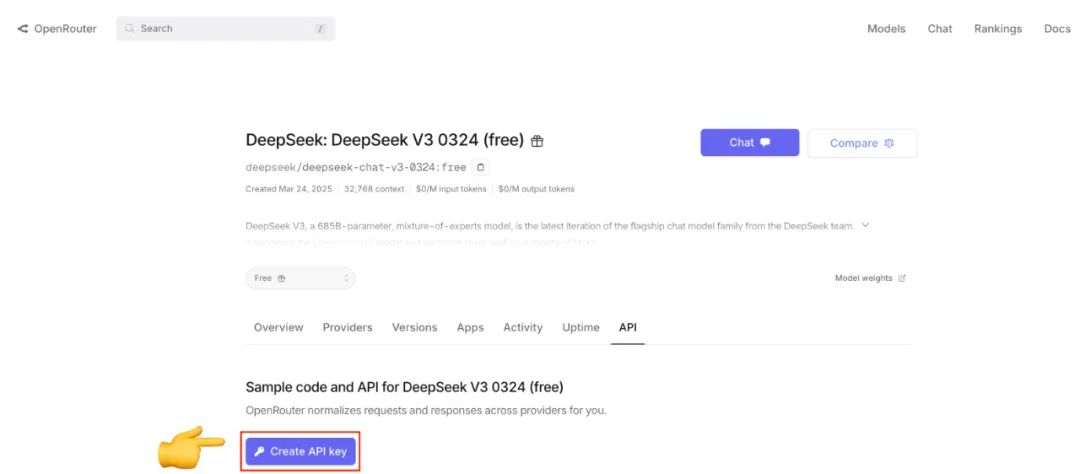
まだの場合 OpenRouter APIキーは、公式ウェブサイトにアクセスして登録・作成できる。
3.4 サービスの展開と開始
モデルを設定したら、プロジェクトの docker ディレクトリに移動し、以下のコマンドを実行する:
cd docker
cp .env.example .env
docker compose --profile '*' up -d
--profile '*' パラメータは docker-compose.yml ファイルで定義されたすべてのサービス(オプションのサービスを含む)が開始される。最初のデプロイメントでは、イメージのプルとビルドに時間がかかる。
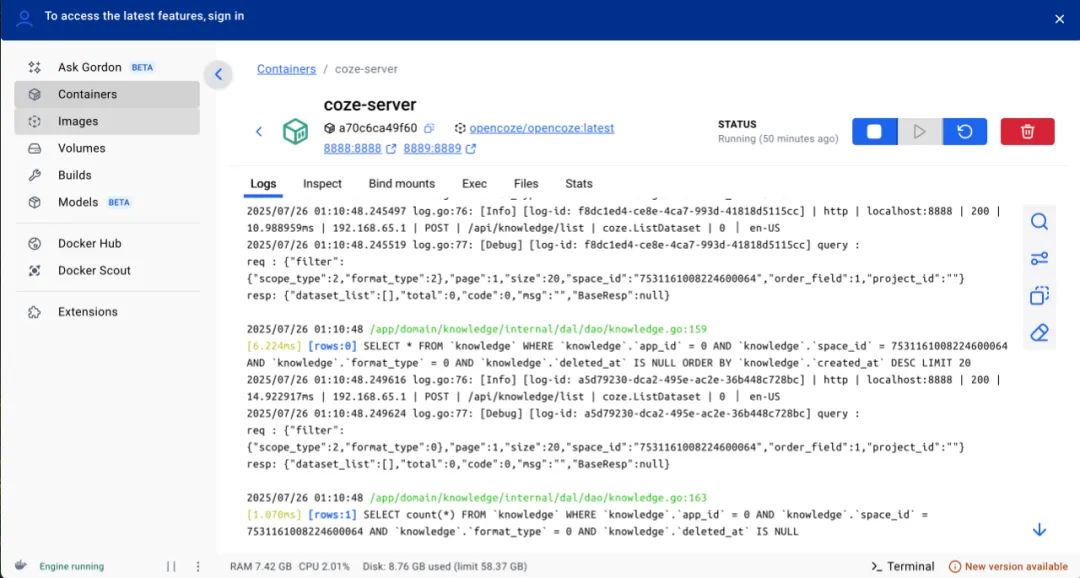
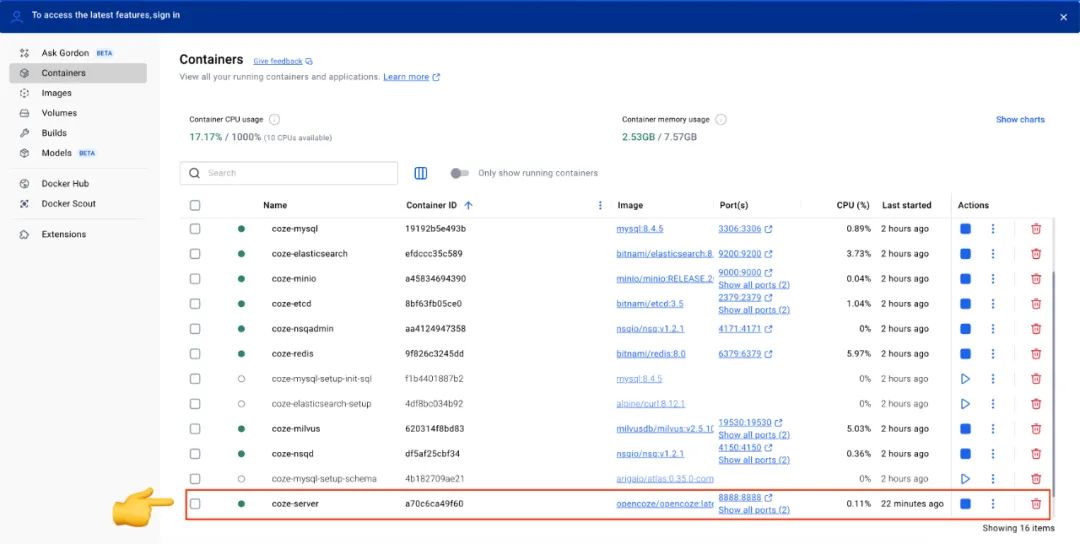
スタート後 Docker Desktop のインターフェイスですべてのサービスのステータスを表示します。が表示されます。 coze-server サービスのステータス・インジケータが緑色に点灯します。 Coze Studio は無事に打ち上げられた。
各コンフィギュレーション・ファイルの変更後、コンフィギュレーションを有効にするために、以下のコマンドを実行してサービスを再起動する必要があります:
docker compose --profile '*' restart coze-server
3.5 Coze Studioの使用
サービス開始後、ブラウザでアクセスしてください。 http://localhost:8888/。
初めてご利用になる場合は、Eメールアドレスとパスワードを入力して新規登録を行ってください。ログインに成功したら、画面右上の Create を選択します。 Create agent。
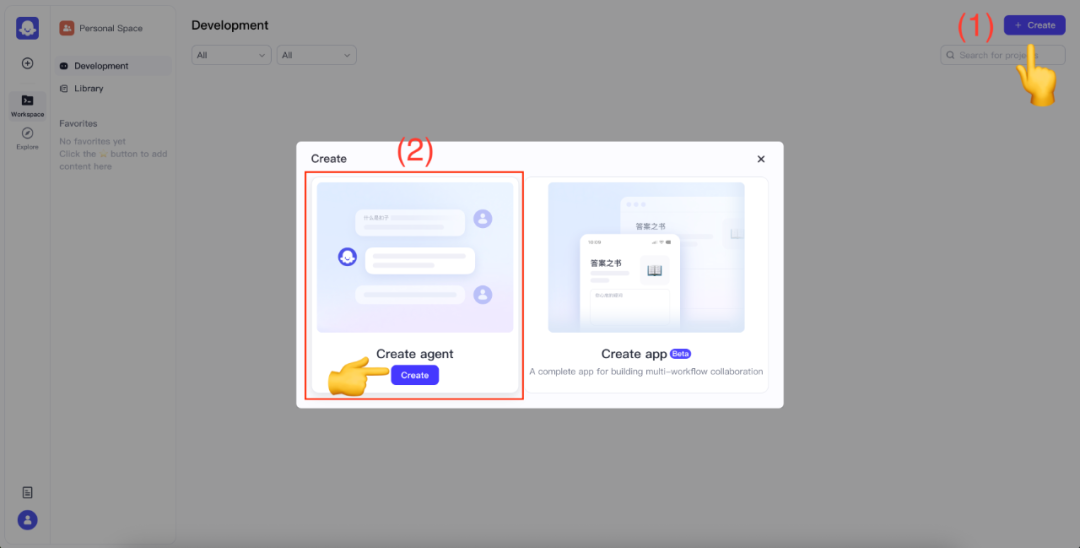
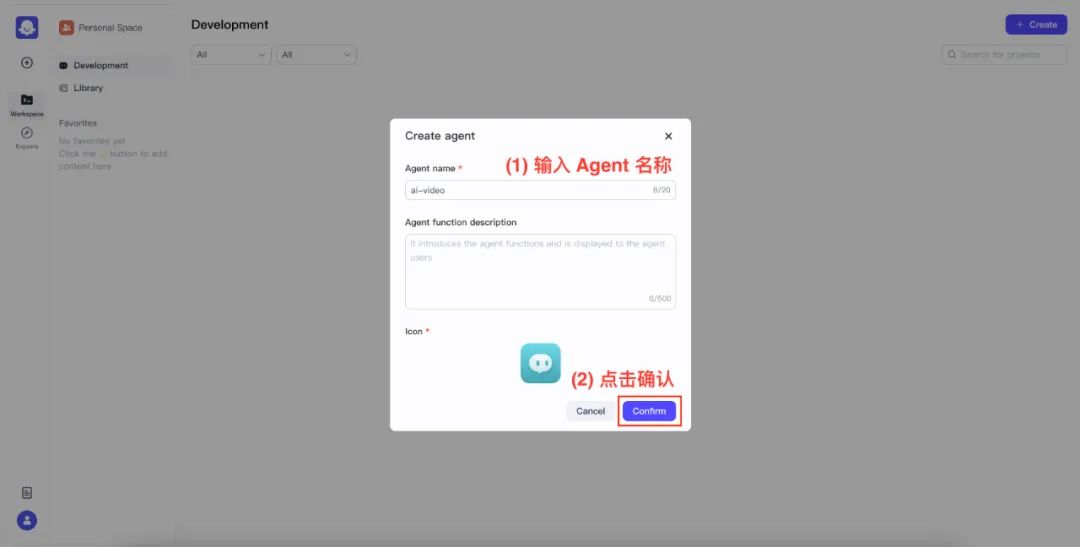
代理人の名前と確認
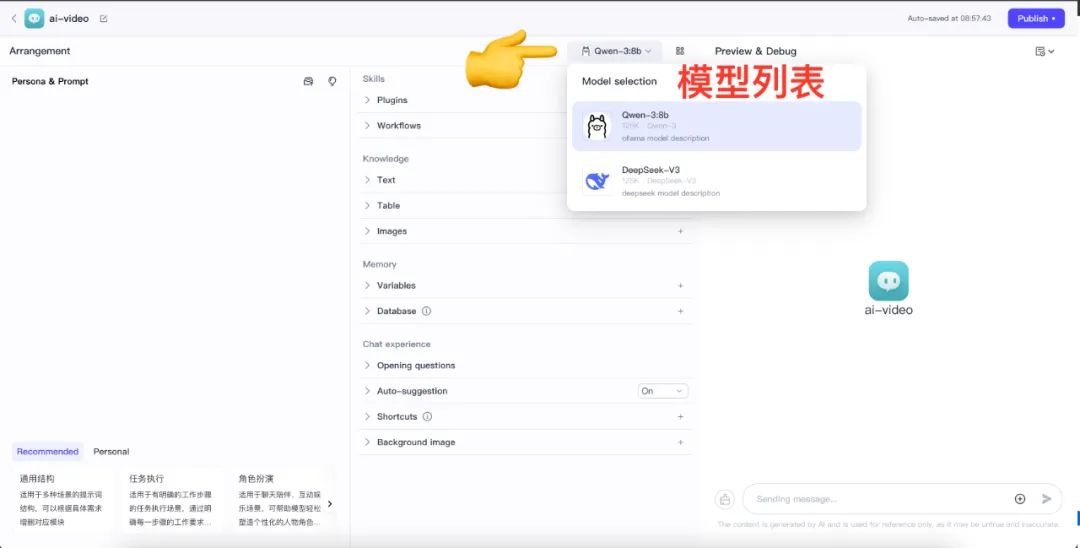
エージェントデザイン画面に入ったら、モデルリストをクリックし、設定されているすべてのモデルを確認します。
右側の下部にあるチャットボックスを使って、モデルが正しく動作しているかどうかをテストすることができます。
- テスト・ローカル・オーラマ
qwen:14bサービス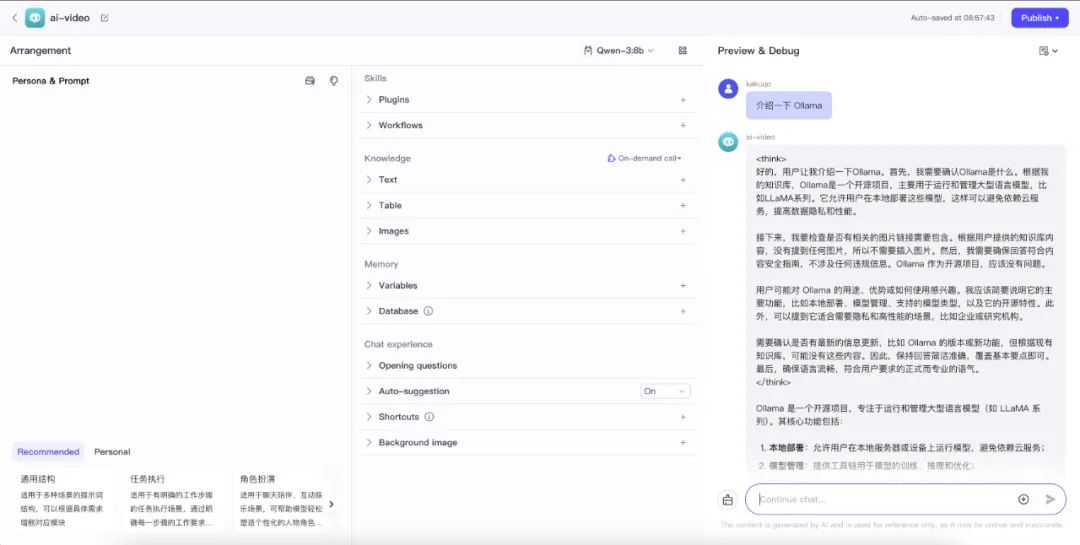
- ワイヤ上でOpenRouterをテストする
DeepSeek-V2サービス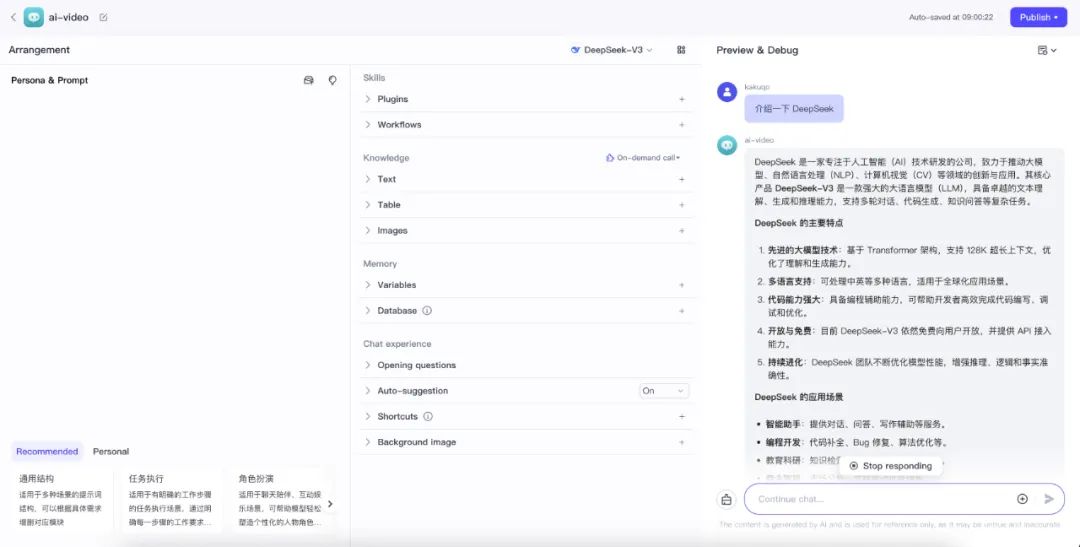
呼び出し例外が発生した場合 Docker Desktop 調べる coze-server コンテナのログからトラブルシューティングを行う。