



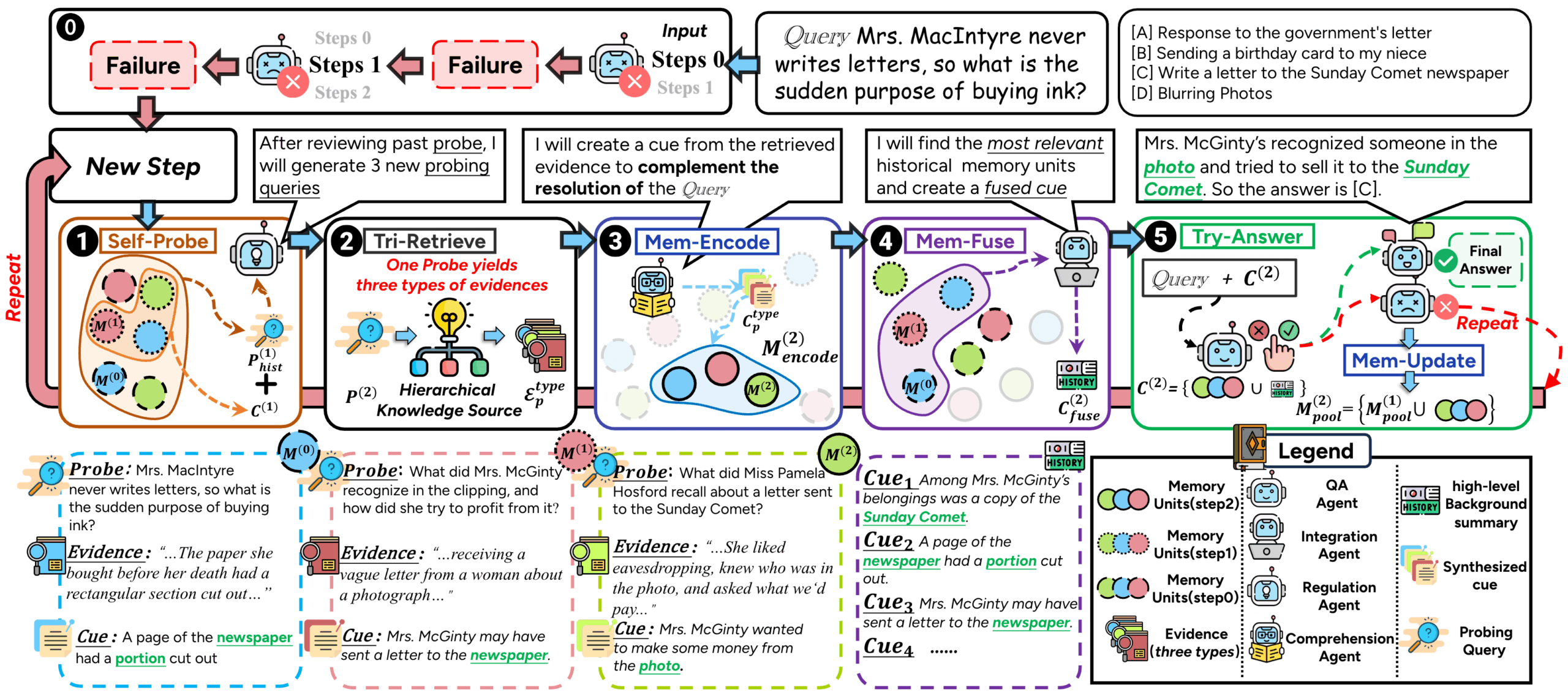
ComoRAGは、長い文書や複数の文書の物語理解に対応するように設計されたRAG(Retrieval Augmented Generation)システムである。従来のRAG手法は、複雑なプロットや展開する登場人物の関係から、長い物語や小説を扱う際にしばしば困難に遭遇する。 これは、ほとんどの手法がステートレスでワンショットの検索アプローチを用いているため、長距離の文脈的関連性を捉えることが困難であることに起因する。 ComoRAGは人間の認知プロセスに着想を得ており、物語推論は一発勝負のプロセスではなく、新しく獲得した証拠を既存の知識と統合する必要のある、ダイナミックで進化するプロセスであると信じている。 推論が困難になると、ComoRAGは反復的な推論ループを開始する。 新たな手がかりを探るための質問を生成し、新たに取得した情報をグローバルな記憶プールに統合し、最初の質問に対する首尾一貫した文脈を徐々に構築していく。 この "推論→探索→検索→統合→解決 "のサイクルは、グローバルな理解を必要とする複雑な問題を扱うのに特に適している。
機能一覧
- 認知記憶フレームワーク人間の脳が情報を処理する方法を模倣し、反復的な推論ループを通して複雑な問題を処理し、ダイナミックでステートフルな推論プロセスを実現する。
- 複数モデルのサポート様々な大規模言語モデル(Large Language Models:LLM)と組み込みモデルの統合とサポートにより、ユーザーはOpenAI APIに接続したり、ローカルのvLLMサーバーや組み込みモデルをデプロイすることができます。
- グラフ拡張検索検索と推論にグラフ構造を使用することで、エンティティ間の複雑な関係をよりよく捉え、理解することができます。
- 柔軟なデータ処理ドキュメントチャンキングツールの提供、トークン、ワード、センテンス、その他のスライス方法のサポート。
- モジュール設計二次開発や機能拡張を容易にするため、システムはモジュール式で拡張できるように設計されている。
- 自動評価F1、EM(完全一致)など、さまざまな指標に対応した評価スクリプトが付属しており、Q&Aの効果を定量的に評価しやすい。
ヘルプの使用
ComoRAGは、長い物語テキストを処理するための理解と推論に焦点を当てた、検索を強化する強力な生成フレームワークである。独自の認知反復ループにより、長文クイズや情報抽出などのタスクにおけるモデルのパフォーマンスを大幅に向上させる。
環境設定とインストール
使い始める前に、ランタイム環境を設定する必要がある。
- パイソン版推奨用途
Python 3.10またはそれ以上。 - 依存関係のインストールプロジェクト・コードをクローンした後、必要な依存パッケージを以下のコマンドでプロジェクトのルート・ディレクトリにインストールします。パフォーマンス向上のため、GPU環境を推奨します。
pip install -r requirements.txt - 環境変数OpenAI APIを使用する場合は、適切な環境変数を設定する必要があります。
OPENAI_API_KEY.ローカルモデルを使用する場合は、モデルへのパスを設定する必要があります。
データ準備
ComoRAG の実行には、特定の形式のデータファイルが必要です。コーパスファイルとQ&Aファイルをご用意ください。
- コーパスファイル(corpus.jsonl)このファイルには、検索が必要なすべての文書が含まれています。このファイルは
jsonlフォーマットでは、各行はドキュメントを表すJSONオブジェクトである。id文書の一意な識別子。doc_idドキュメントが属するグループやブックの識別子。title文書のタイトルcontents元の文書の内容。
例
{"id": 0, "doc_id": 1, "title": "第一章", "contents": "很久很久以前..."} - Q&Aファイル(qas.jsonl)このファイルにはモデルによって回答される必要のある質問が含まれています。繰り返しますが、それぞれの行はJSONオブジェクトです。
idissueの一意な識別子。question具体的な質問golden_answers:: 質問に対する標準的な回答のリスト。
例
{"id": "1", "question": "故事的主角是谁?", "golden_answers": ["灰姑娘"]}
ドキュメントのチャンキング
長い文書はモデルで直接処理することができないため、まず小さく切り刻む必要がある。プロジェクトは chunk_doc_corpus.py スクリプトで行う。
以下のコマンドでコーパスをチャンクすることができる:
python script/chunk_doc_corpus.py \
--input_path dataset/cinderella/corpus.jsonl \
--output_path dataset/cinderella/corpus_chunked.jsonl \
--chunk_by token \
--chunk_size 512 \
--tokenizer_name_or_path /path/to/your/tokenizer
--input_path元のコーパスファイルへのパス。--output_pathチャンキング後のファイルを保存するパス。--chunk_by:: チャンキングの基本。token、word或sentence。--chunk_size各チャンクのサイズ。--tokenizer_name_or_pathトークンの計算に使用される参加者へのパスを指定します。
2つの動作モード
ComoRAGは、OpenAI APIを使用するか、ローカルにデプロイされたvLLMサーバーを使用するかの2つの主流な実行方法を提供する。
モード1:OpenAI APIを使う
これが一番簡単で手っ取り早い方法だ。
- コンフィギュレーションの変更オープン
main_openai.pyファイルでBaseConfig一部修正。config = BaseConfig( llm_base_url='https://api.openai.com/v1', # 通常无需修改 llm_name='gpt-4o-mini', # 指定使用的OpenAI模型 dataset='cinderella', # 数据集名称 embedding_model_name='/path/to/your/embedding/model', # 指定嵌入模型的路径 embedding_batch_size=32, need_cluster=True, # 启用语义/情景增强 output_dir='result/cinderella', # 结果输出目录 ... ) - ランニングプログラム設定が完了したら、スクリプトを直接実行してください。
python main_openai.py
モード2:ローカルvLLMサーバーの使用
十分な計算リソース(GPUなど)があり、ローカルでモデルを実行してデータのプライバシーを確保し、コストを削減したい場合は、このモードを選択できます。
- vLLMサーバーの起動まず、OpenAI APIに対応したvLLMサーバーを立ち上げる必要があります。
python -m vllm.entrypoints.openai.api_server \ --model /path/to/your/model \ --served-model-name your-model-name \ --tensor-parallel-size 1 \ --max-model-len 32768--modelローカルの大きな言語モデルへのパス。--served-model-nameモデルサービスに名前を付けます。--tensor-parallel-size使用しているGPUの数。
- サーバー状態の確認を使うことができる。
curl http://localhost:8000/v1/modelsコマンドを使用して、サーバーが正常に起動したかどうかを確認する。 - コンフィギュレーションの変更オープン
main_vllm.pyファイル内の設定を変更する。# vLLM服务器配置 vllm_base_url = 'http://localhost:8000/v1' served_model_name = '/path/to/your/model' # 与vLLM启动时指定的模型路径一致 config = BaseConfig( llm_base_url=vllm_base_url, llm_name=served_model_name, llm_api_key="EMPTY", # 本地服务器不需要真实的API Key dataset='cinderella', embedding_model_name='/path/to/your/embedding/model', # 本地嵌入模型路径 ... ) - ランニングプログラム設定が完了したら、スクリプトを実行してください。
python main_vllm.py
評価結果
プログラムの実行が終了すると、生成された結果は result/ ディレクトリに保存されます。あなたは eval_qa.py スクリプトを使用して、モデルのパフォーマンスを自動的に評価します。
python script/eval_qa.py /path/to/result/<dataset>/<subset>
このスクリプトは、EM(完全一致率)やF1スコアなどの指標を計算し、次のように生成します。 results.json その他
アプリケーションシナリオ
- 長編小説/脚本分析
作家、脚本家、文学研究者にとって、ComoRAGは強力な分析ツールとなります。ユーザーは小説や脚本を丸ごとインポートし、プロットの展開、登場人物の関係の展開、特定のテーマについて複雑な質問をすることができます。 - 企業レベルのナレッジベースQ&A
組織内には、膨大な量の技術文書、プロジェクト報告書、規則や規定が存在することが多い。コモラグは、このような長く複雑で相互に結びついた文書を扱い、インテリジェントなQ&Aシステムを構築する。社員は、「Q3プロジェクトにおけるオプションAとオプションBの技術的実装の主な違いとリスクは何か」など、自然言語で直接質問することができます。このシステムは、複数のレポートを統合して正確な回答を提供することができる。 - 法律文書および事件ファイルの研究
弁護士や法務担当者は、膨大な長さの法律文書や歴史的ファイルを読む必要がありますが、コモラグは、事件の時系列を素早く整理し、異なる証拠間の相関関係を分析し、結論に達するために複数の文書の統合を必要とする複雑な質問に答えることができ、事件分析の効率を大幅に向上させます。 - 科学的研究と文献レビュー
ComoRAGは、ある分野の複数の論文について質問し、重要な情報を抽出し、ナレッジグラフを構築することで、研究者が研究分野の世界的なダイナミクスや中核となる課題を迅速に把握できるよう支援します。
QA
- コモラグと従来のRAGメソッドとの主な違いは何ですか?
コモRAGの核となる違いは、認知科学にインスパイアされたダイナミックな反復推論プロセスを導入している点である。 従来のRAGは通常1回限りのステートレス検索であるのに対し、ComoRAGは答えにくい質問に遭遇したときに積極的に新たな探索的質問を生成し、検索と情報の統合を何度も繰り返し、最終的な推論を支援するために拡大し続ける「メモリープール」を形成する。 - ローカルのvLLMサーバーを使用するための要件は何ですか?
vLLMローカルサーバーを使用するには、ロードするモデルのサイズにもよりますが、通常、性能の良いNVIDIA GPUと十分なビデオメモリが必要です。また、CUDAツールキットもインストールする必要があります。このアプローチは、初期設定は複雑ですが、より高いデータ・セキュリティと高速な推論を提供します。 - 自分の組み込みモデルを交換することはできますか?
コモラグ・アーキテクチャーはモジュール化されており、以下のことが可能です。embedding_model新しい組み込みモデルのサポートを追加するためのカタログです。ただ、あなたのモデルがテキストをベクトルに変換できることを確認し、システムのデータ読み込みと呼び出しのインターフェースに適応させてください。 - このフレームワークは、画像やオーディオ/ビデオなどのマルチモーダルなデータの取り扱いをサポートしていますか?
プロジェクトの基本的な説明からすると、ComoRAGは現在、長い文書や複数文書のQ&Aなど、長いテキストによるナラティブの処理に焦点を当てている。 そのモジュール設計は、将来的にマルチモーダル機能を拡張する可能性を提供するが、現バージョンのコア機能はテキストデータを中心に構築されている。
































