



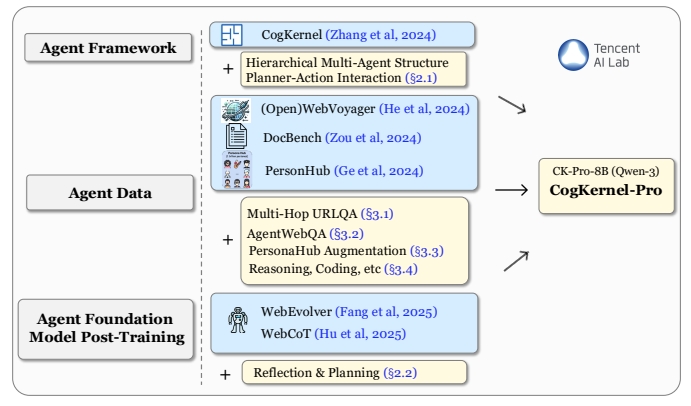
Cognitive Kernel-Proは、TencentのAIラボによって開発されたオープンソースのフレームワークで、ユーザーが深い研究インテリジェンスを構築し、インテリジェントなベースモデルを訓練するのを支援するように設計されている。ウェブブラウジング、ファイル操作、コード実行を統合し、複雑な研究タスクにおいてユーザーをサポートする。このフレームワークは、オープンソースとアクセシビリティを確保するため、フリーツールの使用を重視している。ユーザーは、リアルタイム情報、ファイル管理、コード生成などのタスクを処理するための簡単なセットアップで、インテリジェンスをローカルに配備し実行することができる。このプロジェクトはGAIAベンチマークで好成績を収め、いくつかのクローズド・ソース・システムの性能に匹敵するか、それを上回ることさえある。コードとモデルは完全にオープンソース化され、コミュニティへの貢献とさらなる研究を奨励するためにGitHubでホストされている。
機能一覧
- ウェブブラウジング:知的身体は、ブラウザを制御してクリックや入力などの操作を行うことで、リアルタイムのウェブ情報を得ることができる。
- ファイル処理: ローカルファイルの読み取りと処理をサポートし、キーデータの抽出やレポートの作成を行います。
- コード実行:データ分析やタスク自動化のためのPythonコードを自動生成して実行します。
- モジュラー設計:インテリジェンスの機能の組み合わせをカスタマイズできるマルチモジュール・アーキテクチャを提供。
- オープンソースモデルのサポート:Qwen3-8B-CK-Proと他のオープンソースモデルを統合し、使用コストを削減します。
- タスクプランニング: インテリジェントボディは、ユーザーの指示に従ってタスクプランを生成し、複雑なタスクを分解することができる。
- 安全なサンドボックス操作:サンドボックス環境でのコード実行をサポートし、操作の安全性を確保する。
ヘルプの使用
設置プロセス
Cognitive Kernel-Proを使用するには、ユーザーはローカル環境で以下のインストールおよび設定手順を完了する必要があります。以下は、ユーザーが迅速に開始できるようにするための詳細なインストール手順です。
1.環境準備
まず、システムにPython 3.8以上がインストールされていることと、Gitツールがあることを確認してください。これはLinuxかmacOSのシステムで推奨されます。Windowsユーザーは、いくつかの依存関係を追加でインストールする必要があります。基本的な手順は以下の通りです:
- 依存関係のインストール以下のコマンドを実行して、必要なPythonパッケージをインストールしてください:
pip install boto3 botocore openai duckduckgo_search rich numpy openpyxl biopython mammoth markdownify pandas pdfminer-six python-pptx pdf2image puremagic pydub SpeechRecognition bs4 youtube-transcript-api requests transformers protobuf openai langchain_openai langchain selenium helium smolagents - システム依存のインストール(Linuxシステム):
apt-get install -y poppler-utils default-jre libreoffice-common libreoffice-java-common libreoffice ffmpegこれらのツールは、ファイル変換やマルチメディア処理をサポートしています。
- Pythonパスの設定プロジェクトのパスを環境変数に追加する:
export PYTHONPATH=/your/path/to/CogKernel-Pro - クローンプロジェクトGitHubからCognitive Kernel-Proのリポジトリをクローンする:
git clone https://github.com/Tencent/CognitiveKernel-Pro.git cd CognitiveKernel-Pro
2.コンフィギュレーション・モデリング・サービス
コグニティブ・カーネル・プロ・サポート vLLM またはTGI Model Serverを使用してオープンソースモデルを実行します。以下はvLLMの例です:
- vLLMのインストール:
pip install vllm - モデルサービスの開始Qwen3-8B-CK-Proモデルの重量をダウンロードしたと仮定して、以下のコマンドを実行してサービスを開始します:
python -m vllm.entrypoints.openai.api_server --model /path/to/downloaded/model --worker-use-ray --tensor-parallel-size 8 --port 8080 --host 0.0.0.0 --trust-remote-code --max-model-len 8192 --served-model-name ck
3.ウェブブラウザサービスの設定
このプロジェクトでは、Playwrightを使用してウェブ・ブラウジング機能を提供しています。以下のスクリプトを実行して、ブラウザ・サービスを開始する:
sh ck_pro/ck_web/_web/run_local.sh
サービスがデフォルトのポートで実行されていることを確認する。 localhost:3001。
4.メインプログラムの実行
モデルとブラウザ・サービスを準備したら、メイン・アプリケーションを実行してタスクを実行する:
NO_NULL_STDIN=1 python3 -u -m ck_pro.ck_main.main --updates "{'web_agent': {'model': {'call_target': 'http://localhost:8080/v1/chat/completions'}, 'web_env_kwargs': {'web_ip': 'localhost:3001'}}, 'file_agent': {'model': {'call_target': 'http://localhost:8080/v1/chat/completions'}}}" --input /path/to/simple_test.jsonl --output /path/to/simple_test.output.jsonl |& tee _log_simple_test
--inputタスク入力ファイルをJSON Linesフォーマットで指定する。--outputスマートボディの実行結果を保存する出力ファイルへのパスを指定します。
5.注意事項
- 安全性潜在的なリスクを避けるため、sudo権限を無効にしてサンドボックス環境で実行することをお勧めします:
echo "${USER}" 'ALL=(ALL) NOPASSWD: !ALL' | tee /etc/sudoers.d/${USER}-rule chmod 440 /etc/sudoers.d/${USER}-rule deluser ${USER} sudo - デバッグモードを加えることができる。
-mpdbパラメータを使用して、トラブルシューティング用のデバッグモードに入る。
主な機能
ウェブブラウザ
Cognitive Kernel-Proのウェブ閲覧機能により、インテリジェンスは人間のようにウェブページと対話することができます。ユーザーがタスクの説明(例えば「GitHub上のリポジトリの最新コミットを検索する」)を提供すると、インテリジェンスが自動的にブラウザを開き、目的の情報を取得するためにクリックやタイピングなどを実行する。これがその仕組みだ:
- 例えば、入力ファイルにタスクを定義する:
{"task": "find the latest commit details of a popular GitHub repository"} - スマートボディはタスクプランを生成し、Playwrightブラウザを起動し、ターゲットのウェブページにアクセスする。
- ウェブページの内容を抽出し、その結果を出力ファイルに保存して返します。
文書処理
ファイル処理機能は、多くのフォーマット(PDF、Excel、Wordなど)のファイルの読み込みと分析をサポートします。PDFから表形式のデータを抽出するなど、ファイルのパスやタスクを指定することができます:
- ファイルのパスとタスクを指定して、入力ファイルを準備する:
{"task": "extract table data from /path/to/document.pdf"} - スマート・ボディはファイル処理モジュールを呼び出し、ファイルを解析してデータを抽出する。
- 結果はJSONやCSVのような構造化フォーマットで出力ファイルに保存される。
コード実行
コード実行機能により、インテリジェンスはデータ分析または自動化タスクを完了するためにPythonコードを生成して実行することができます。例えば、CSVファイル内のデータを分析します:
- タスクの説明を入力する:
{"task": "analyze sales data in /path/to/sales.csv and generate a summary"} - インテリジェンシアは、pandasなどのライブラリを使用してデータを処理するPythonコードを生成する。
- コードはサンドボックス環境で実行され、結果は出力ファイルに保存される。
ミッション計画
インテリジェンスはタスクの複雑さに基づいて実行計画を生成する。例えば、「論文の内容を検索して要約する」の場合:
- インテリ層は、論文を検索し、PDFをダウンロードし、重要な情報を抽出し、要約を作成するというサブステップにタスクを分解する。
- 各サブステップは、適切なモジュール(ウェブ閲覧、ファイル処理など)を呼び出して実行する。
- 最終結果はユーザー指定のフォーマットで出力される。
注目の機能操作
オープンソースモデルのサポート
Cognitive Kernel-Proは、GAIAベンチマークで優れた性能を発揮するQwen3-8B-CK-Proモデルを統合しています。ユーザーはモデルの重みを直接ダウンロードできるため、クローズドソースのAPIに依存する必要がなく、所有コストを削減できます。このモデルはマルチモーダルなタスク(画像処理など)をサポートしており、ユーザーはVLM_URLを設定してマルチモーダルな機能を使用することができます。
セキュリティ・サンドボックスの運用
コード実行に関連するリスクを防ぐため、フレームワークはサンドボックス環境で実行することを推奨します。ユーザーはコードの分離を確実にするためにDocker経由でデプロイすることができる:
docker run --rm -v /path/to/CogKernel-Pro:/app -w /app python:3.8 bash -c "pip install -r requirements.txt && python -m ck_pro.ck_main.main"
アプリケーションシナリオ
- 学術研究
Cognitive Kernel-Proを使えば、学術論文を検索し、重要な情報を抽出して要約を作成することができる。例えば、「AIの最新論文を検索し、要約する」と入力すると、インテリジェンスが自動的にarXivを検索し、論文のPDFをダウンロードし、要約と結論を抽出し、簡潔なレポートを生成します。 - データ分析
ビジネス・ユーザーは、フレームワークを使用してローカル・データ・ファイルを分析できます。例えば、売上データのCSVファイルを処理し、統計グラフやトレンド分析レポートを作成することは、迅速なビジネス洞察の生成に適しています。 - 自動化されたタスク
開発者はインテリジェンスを使用して、ウェブデータの一括ダウンロード、ファイルコンテンツの整理、コードテストの実行などの反復タスクを自動化し、生産性を向上させることができる。 - オープンソースコミュニティ開発
コミュニティ開発者は、フレームワークに基づいてインテリジェンスをカスタマイズしたり、新しいファイルパーサーを追加するなどの機能モジュールを拡張したり、他のオープンソースモデルを統合したりすることで、フレームワークの継続的な改善に参加することができます。
QA
- Cognitive Kernel-Proは有料のAPIが必要ですか?
必要なし。フレームワークは、完全にオープンソースのツールとモデル(例:Qwen3-8B-CK-Pro)を使用しており、有料のAPIに依存していません。ユーザーは、モデルの重みをダウンロードしてローカルに配置するだけです。 - 安全なコード実行を保証するには?
サンドボックス環境(Dockerなど)で実行し、sudoパーミッションを無効にし、ネットワークアクセスを制限することを推奨します。プロジェクトのドキュメントに、詳細なセキュリティ設定のガイドラインが記載されています。 - どのようなファイル形式に対応していますか?
PDF、Excel、Word、Markdown、PPTXなどの一般的な形式をサポートしています。テキスト、表、または画像データは、ファイル処理モジュールを介して抽出することができます。 - 複雑な仕事をどのように処理していますか?
インテリジェントなボディは、複雑なタスクをサブタスクに分解し、実行プランを生成し、ウェブブラウジング、ファイル処理、コード実行モジュールを呼び出して、ステップ・バイ・ステップでタスクを完了させる。 - マルチモーダルなタスクはサポートされているか?
はい、画像処理やビデオ解析などのマルチモーダルなタスクがサポートされています。ユーザーはVLM_URLを設定し、マルチモーダルモデルをサポートする必要があります。


























