



ARC-Hunyuan-Video-7Bは、テンセントのARC Labによって開発されたオープンソースのマルチモーダルモデルで、ユーザーが作成した短い動画コンテンツの理解に焦点を当てている。動画から視覚、音声、テキスト情報を統合することで、綿密な構造分析を提供する。このモデルは、複雑な視覚要素、高密度の音声情報、テンポの速い短い動画を扱うことができ、動画検索、コンテンツ推薦、動画要約などのシナリオに適している。モデルは7Bのパラメータでスケーリングされ、効率的な推論と高品質の出力を保証するために、事前学習、命令の微調整、強化学習を含む複数の段階で学習されます。ユーザーはGitHubを通じてコードとモデルの重みにアクセスすることができ、本番環境に簡単に導入することができる。
機能一覧
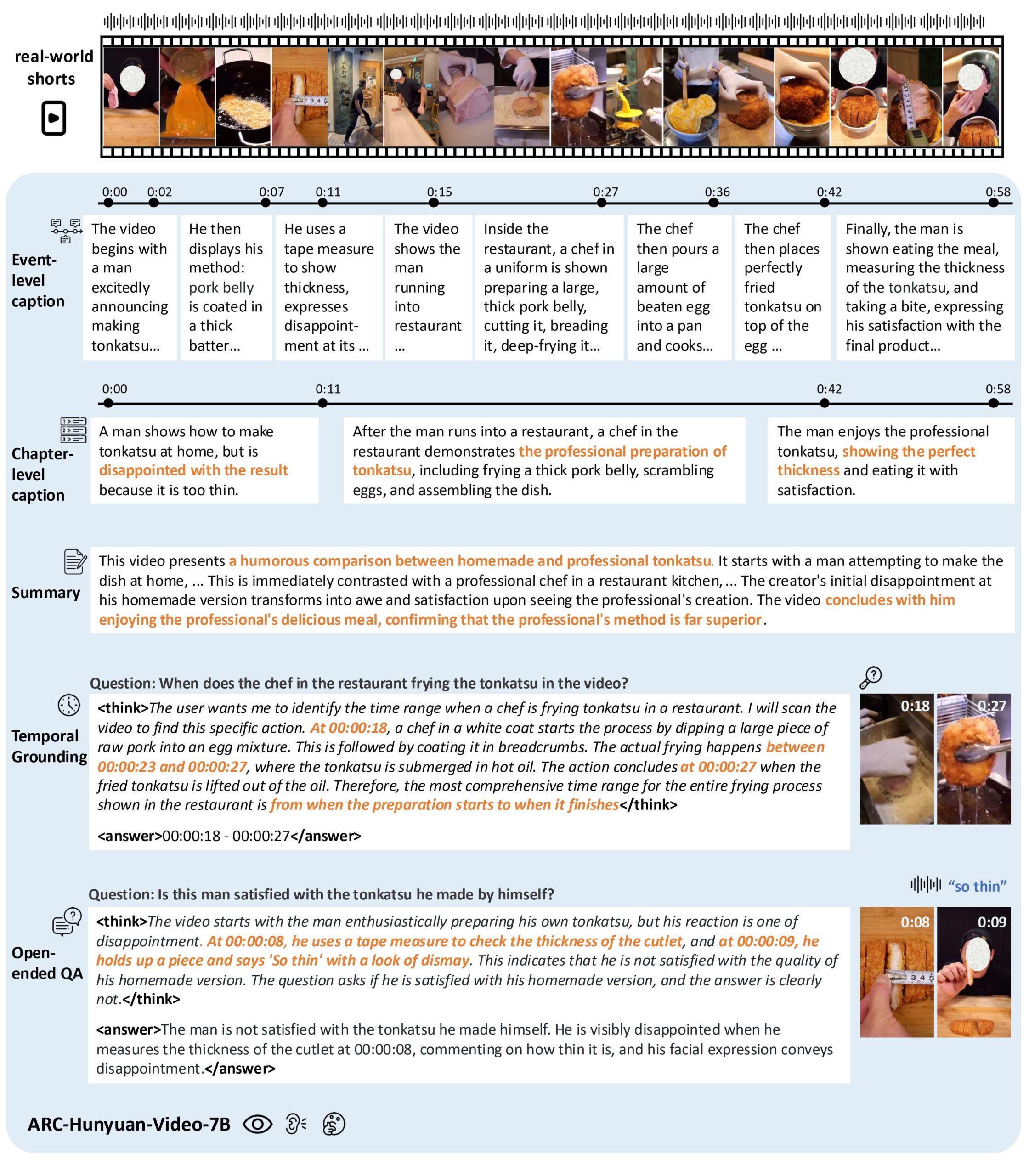
- ビデオの内容理解:短いビデオの映像、音声、テキストを分析し、核心的な情報や感情表現を抽出する。
- タイムスタンプ注釈:サポート多粒度タイムスタンプビデオ説明、イベントの時間の正確な注釈。
- ビデオクイズ:ビデオの内容に関する自由形式の質問に答え、ビデオの中の複雑なシナリオを理解する。
- タイムロケーション:ビデオ内の特定のイベントやクリップを検索し、ビデオの検索と編集をサポートします。
- ビデオの要約:ビデオの内容を簡潔に要約し、重要な情報を強調します。
- 多言語サポート:中国語と英語のビデオコンテンツ分析をサポートし、中国語のビデオ処理に特別に最適化されています。
- 効率的な推論:サポート vLLM 加速、10秒で1分のビデオ推論。
ヘルプの使用
設置プロセス
ARC-Hunyuan-Video-7Bを使用するには、GitHubリポジトリをクローンし、環境を設定する必要があります。以下はその詳細な手順である:
- クローン倉庫:
git lfs install git clone https://github.com/TencentARC/ARC-Hunyuan-Video-7B cd ARC-Hunyuan-Video-7B - 依存関係のインストール:
Python 3.8+とPyTorch 2.1.0+(CUDA12.1サポート)がシステムにインストールされていることを確認します。以下のコマンドを実行して、必要なライブラリをインストールします:pip install -r requirements.txt - モデルウェイトのダウンロード:
モデルウェイトはHugging Faceでホストされている。ユーザーは以下のコマンドでダウンロードできる:from huggingface_hub import hf_hub_download hf_hub_download(repo_id="TencentARC/ARC-Hunyuan-Video-7B", filename="model_weights.bin", repo_type="model")または、Hugging Faceから直接手動でダウンロードし、それを
experiments/pretrained_models/カタログ - vLLMのインストール(オプション):
推論を加速するために、vLLMをインストールすることをお勧めします:pip install vllm - 検証環境:
リポジトリが提供するテストスクリプトを実行して、環境が正しく設定されていることを確認します:python test_setup.py
使用方法
ARC-Hunyuan-Video-7Bはローカル操作とオンラインAPIコールをサポートする。以下は主な機能操作の流れである:
1.映像コンテンツの理解
ユーザーは短い動画ファイル(MP4形式など)を入力することができ、モデルは動画のビジュアル、オーディオ、テキストコンテンツを分析し、構造化された説明を出力します。例えば、TikTokの面白いビデオを入力すると、モデルはビデオ内のアクション、ダイアログ、BGMを抽出し、イベントの詳細な説明を生成することができます。
手続き:
- ビデオファイルを準備する
data/input/カタログ - 推論スクリプトを実行する:
python inference.py --video_path data/input/sample.mp4 --task content_understanding - 出力は
output/JSON 形式のカタログで、動画コンテンツの詳細な説明を含む。
2.タイムスタンプのラベリング
このモデルは、動画のタイムスタンプ付き説明文の生成をサポートしており、ビデオクリップや検索など、イベントの正確な位置特定を必要とするアプリケーションに適しています。
手続き:
- タイムスタンプ注釈を実行するには、以下のコマンドを使用します:
python inference.py --video_path data/input/sample.mp4 --task timestamp_captioning - 出力例:
[ {"start_time": "00:01", "end_time": "00:03", "description": "人物A进入画面,微笑挥手"}, {"start_time": "00:04", "end_time": "00:06", "description": "背景音乐响起,人物A开始跳舞"} ]
3.ビデオクイズ
ユーザーはビデオについて自由形式の質問をすることができ、モデルは映像情報と音声情報を組み合わせてそれに答える。例えば、"登場人物はビデオの中で何をしているのか?"あるいは、"映像はどのような感情を表現していますか?"
手続き:
- 課題ファイルの作成
questions.jsonフォーマットは以下の通り:[ {"video": "sample.mp4", "question": "视频中的主要活动是什么?"} ] - クイズスクリプトを実行する:
python inference.py --question_file questions.json --task video_qa - 出力はJSON形式で、質問に対する答えが含まれています。
4.時間志向
タイムロケーター機能を使えば、ビデオ内の特定のイベントのクリップを探すことができます。例えば、「人々が踊っている」クリップを検索します。
手続き:
- ポジショニングスクリプトを実行する:
python inference.py --video_path data/input/sample.mp4 --task temporal_grounding --query "人物跳舞" - などの時間帯で出力される。
00:04-00:06。
5.ビデオ・サマリー
このモデルは、ビデオの内容を簡潔に要約し、核となるメッセージを強調する。
手続き:
- 要約スクリプトを実行する:
python inference.py --video_path data/input/sample.mp4 --task summarization - 出力例:
视频展示了一位人物在公园跳舞,背景音乐欢快,传递了轻松愉快的情绪。
6.オンラインAPIの使用
テンセント・アークは、ハギング・フェイスや公式デモからアクセスできるオンラインAPIを提供している。デモページにアクセスし、ビデオをアップロードしたり、質問を入力すると、モデルがリアルタイムで結果を返します。
手続き:
- Hugging FaceのARC-Hunyuan-Video-7Bデモページをご覧ください。
- ビデオファイルのアップロードやタイピングに問題がある。
- 出力結果を表示し、JSON形式での分析データのダウンロードをサポート。
ほら
- ビデオ解像度オンラインデモは圧縮解像度を使用しているため、パフォーマンスに影響を与える可能性があります。最良の結果を得るためには、ローカルで実行することをお勧めします。
- ハードウェア要件推論速度を確保するため、NVIDIA H20以上のGPUを推奨します。
- 言語サポートこのモデルは中国語の動画に対してより最適化されており、英語の動画に対しては若干パフォーマンスが低下している。
アプリケーションシナリオ
- ビデオ検索
ユーザーは、動画プラットフォーム上で「料理のチュートリアル」や「面白いクリップ」といったキーワードで、動画内の特定のイベントやコンテンツを検索することができる。 - コンテンツ推薦
このモデルは、動画の核となるメッセージとセンチメントを分析し、プラットフォームがユーザーの興味に合ったコンテンツを推薦するのを助ける。 - ビデオクリップ
クリエイターは、タイムスタンプラベリングとタイムポジショニング機能を使って、動画から主要なクリップをすばやく抽出し、ハイライトクリップを作成できます。 - 教育とトレーニング
教育用ビデオでは、モデルが要約を生成したり、生徒の質問に答えたりして、コースの内容をすばやく理解できるようにします。 - ソーシャルメディア分析
ブランドは、TikTokやWeChatのユーザー生成コンテンツを分析して、オーディエンスの感情的な反応や好みを理解することができる。
QA
- どのようなビデオフォーマットに対応していますか?
MP4、AVI、MOVのような一般的なフォーマットがサポートされており、最適なパフォーマンスを得るためにビデオの再生時間を1~5分に制限することをお勧めします。 - 推理のスピードを最適化するには?
推論を高速化するためにvLLMを使用し、GPUがCUDA 12.1をサポートしていることを確認します。ビデオの解像度を下げることでも計算量を減らすことができます。 - 長時間のビデオをサポートしていますか?
このモデルは、主に短い動画(5分未満)に最適化されています。長い動画は分割して処理する必要があり、前処理スクリプトを使用して動画を分割することを推奨します。 - モデルはリアルタイム処理をサポートしているか?
そう、vLLMを導入すれば、1分間のビデオ推論にかかる時間はわずか10秒であり、リアルタイム・アプリケーションに適している。






























