



AI SheetsはHugging Faceのオープンソースツールです。ユーザーはコードを書くことなく、AIモデルでデータセットを構築、強化、変換することができる。ローカルへの展開やHugging Face Hub上での実行をサポートします。このツールはHugging Face Hubにある何千ものオープンソースモデルに接続し、推論プロバイダーを通してそれらにアクセスします。ユーザーは、OpenAIのgpt-ossを含むローカルモデルを使用することもできます。ユーザーはプロンプトを書くことで新しい列を作成し、大規模なパイプラインにスケールアップする前に、小規模なデータセットで素早く実験することができる。このツールは反復を重視しており、ユーザーはセルを編集したり、結果を検証したりしてモデルを学習する。その中核は、分類から合成データの生成まで、データを処理するためにAIを使用することである。モデルのテスト、キューの改善、データセットの分析に最適です。結果をハブにエクスポートし、データ生成をスケールするためのコンフィギュレーションも生成します。
機能一覧
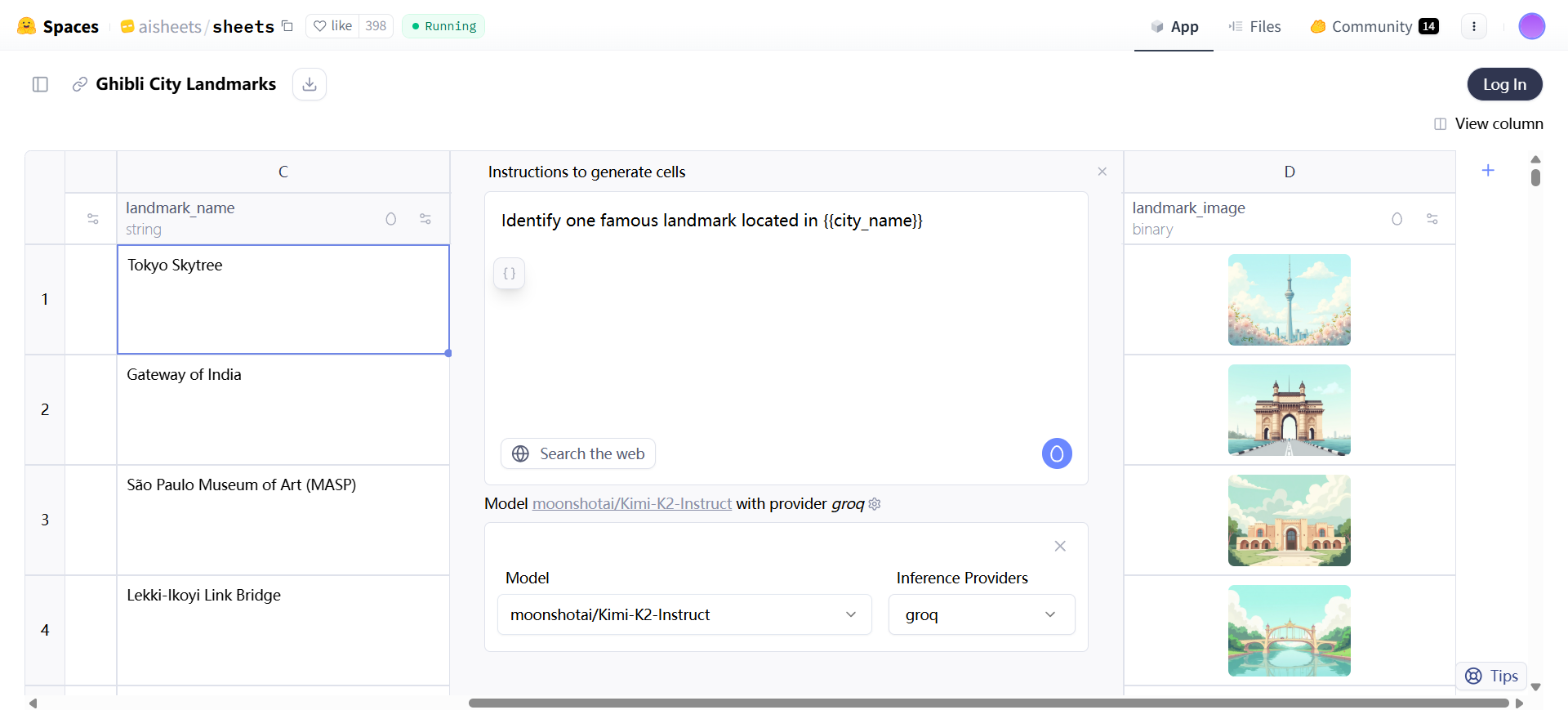
- データセットはゼロから生成される。自然言語による記述を入力すると、AIが自動的に構造やサンプル行を作成し、例えば、国やランドマーク画像を含む都市リストを生成する。
- データのインポートと処理:XLS、TSV、CSV、またはParquetファイルをアップロードし、最大1000行、無制限の列をサポートし、データを編集して拡張することができます。
- AIカラムの追加: {{column}}などの既存のカラムを参照しながら、情報の抽出、テキストの要約、コンテンツの翻訳、カスタムアクションなどのプロンプトを持つ新しいカラムを作成します。
- モデルの選択と切り替え:ハギング・フェイス・ハブからモデルとプロバイダーを選択(例:meta-llama/Llama-3.3-70B-Instructまたはopenai/gpt-oss-120b)。
- フィードバック・メカニズム:手動でセルを編集したり、良い結果を気に入ったりすると、再生時に出力を向上させるための数ショットの例として使用される。
- ウェブ検索スイッチ:有効な場合、モデルはウェブから最新の情報を取得する。
- データ拡張:列をドラッグ・アンド・ドロップすることで、再生成せずに行を増やすことができます。
- ハブへのエクスポート: プロンプトを再利用したり、スクリプトでより大きなデータセットを生成したりするために、データセットと設定 YAML ファイルを保存します。
- モデルの比較と評価:異なるモデルをテストするために複数の列を作成し、判定列としてLLMを使用して出力の品質を比較する。
- 合成データ生成:経歴に基づいた職業メールなどの仮想データセットを作成。
- データ変換とクリーニング:句読点や標準化されたテキストをプロンプトで削除する。
- データの分類と分析:コンテンツの分類や重要なアイデアの抽出。
- データエンリッチメント:郵便番号の追加や説明文の生成など、不足している情報を補う。
- 画像生成:black-forest-labs/FLUX.1-devのようなモデルで画像カラムを作成し、特定のスタイルをサポートします。
ヘルプの使用
AI Sheetsの使用は起動時に開始されます。ユーザーには、オンライントライアルとローカルインストールの2つのアクセス方法があります。オンライントライアルはインストール不要です。https://huggingface.co/spaces/aisheets/sheets。 Hugging Faceアカウントにログイン。https://huggingface.co/settings/tokens からHF_TOKENを取得する。 インターフェースが表示されたら、新しいデータセットを生成するか、既存のデータをインポートするかを選択する。
ゼロからデータセットを生成することは、初めてこのツールに慣れる場合、ブレーンストーミングを行う場合、あるいは素早く実験を行う場合に適している。生成オプションをクリックする.プロンプトエリアに「世界の都市のリスト、国名と各ランドマークのジブリ風画像を含む」など、説明を入力します。ai Sheetsはスキーマと5つのサンプル行を作成します。結果には、都市、国、画像などの列があります。列の下部をドラッグすると、最大1000行まで生成できます。プロンプトを修正して構造を再生成する。手動でセルを入力し、ドラッグ・アンド・ドロップで他の列を完成させる。
ほとんどの場合、データセットのインポートをお勧めします。アップロードできるファイル形式は、XLS、TSV、CSV、またはParquetです。ファイルには、少なくとも1つの列名と1行のデータが必要です。アップロード後、データは表に表示されます。空のセルに手動でエントリを追加します。インターフェイスはスプレッドシートのようで、インポートされたセルは編集できますが、AIによって変更することはできません。
新しいカラムを追加することが核となる操作です。ボタンをクリックする。情報の抽出]、[テキストの要約]、[翻訳]、または[{{text}}から余分な句読点を削除する]などのカスタムプロンプトなどの推奨アクションを選択します。{text}}は既存の列を参照します。モデルを設定します。例えば、meta-llama/Llama-3.3-70B-Instructを選択し、groqのようなプロバイダを指定します。 Searchを切り替える: "Find postcode for {{address}}"のように、ウェブデータの取得を有効にします。カラムを生成した後、結果を表示します。
フィードバックとコンフィギュレーションによるデータセットの改良AIセルを手動で編集し、好みの出力例を提供する。親指を立ててGood Resultsをタップする。再生成をクリックすると、すべての列に適用されます。プロンプトを調整する。例えば、"Category {{text}}"をより具体的なバージョンに変更する。パフォーマンスをテストするためにモデルを切り替える。 groq 大脳を変える。創造的なアウトプットや構造化されたアウトプットなど、異なるタスクには異なるモデルが適している。プロバイダーはスピードとコンテキストの長さに影響する。
ドラッグ&ドロップでデータを拡張。列の最後のセルからプルダウンすると、即座に新しい行が生成されます。再生成は不要。この方法は、間違ったセルを修正するためにも使用されます。
Hubにエクスポートして作業を保存します。Export をクリックします。データセットと config.yml ファイルが生成されます。ファイルには、列の構成、プロンプト、モデルの詳細が含まれます。サンプルの config には、各カラムの modelName、userPrompt などをリストするカラムキーがあります。アップロードされると、Hub の https://huggingface.co/datasets/dvilasuero/nemotron-personas-kimi-questions などで表示できます。
HF ジョブでより大きなデータセットを生成するには、設定とスクリプトが必要です。以下のようなコマンド: hf jobs uv run -s HF_TOKEN=$HF_TOKEN https://huggingface.co/datasets/aisheets/uv-scripts/raw/main/extend_dataset/script.py-config https://huggingface.co/datasets/dvilasuero/nemotron-personas-kimi-questions/raw/main/config.yml -num-rows 100 nvidia/Nemotron-Personas dvilasuero/nemotron-kimi-qa-distilled. 行数を指定するか、空白のままにしておくと、すべての行が生成されます。
GitHubからローカルにインストールする。https://github.com/huggingface/aisheets。HF_TOKENをセットアップする。Dockerで:export HF_TOKEN=your_token_here; docker run -p 3000:3000 -e HF_TOKEN=$HF_TOKEN huggingface/sheets.TOKEN=$HF_TOKEN huggingface/sheets。http://localhost:3000。pnpmを使用:pnpmのインストール、リポジトリのクローン、HF_TOKENのエクスポート、pnpmのインストール、pnpmのdev。http://。localhost:5173。本番用ビルド: pnpm build, pnpm serve。
OllamaのようなカスタムLLMから始めましょう。 Ollama server: export OLLAMA_NOHISTORY=1; ollama serve; ollama run llama3. set MODEL_ENDPOINT_URL=http://localhost:11434, MODEL_ENDPOINT_NAME=llama3.カスタマイズはOpenAI APIに準拠する必要がある。画像生成はHugging Face APIを使って固定されている。
高度なコンフィギュレーションでは、環境変数.OAUTH_CLIENT_IDを使用して認証します.DEFAULT_MODELを使用してデフォルトのモデルを変更します.NUM_CONCURRENT_REQUESTSを使用して同時実行を制御します、デフォルトは5です.SERPER_API_KEYを使用して検索を有効にします.DATA_DIRを使用してデータ・ディレクトリを設定します。
操作手順の例:モデルをテストする。プロンプトを含むデータセットをインポートする。応答: {{prompt}}" のようなカラムを追加し、異なるモデルを選択します。応答1: {{model1}}, 応答2: {{model2}} に対して {{prompt}} を評価する" のような判定カラムを追加します。手動でチェックするか、LLM を使用して最適化します。
カテゴリー化されたデータセット:テキストデータセットをアップロード。カラム「{{text}}の主なトピックを分類する」を追加。悪い結果を編集し、良い結果を指摘し、再生成する。
データを合成する:person bioカラム「製薬会社のプロフェッショナルの簡単な説明を書く」を生成する。Eメールカラム「{{person_bio}}の実際のプロフェッショナルEメールを書く」を追加。
分析:「{{テキスト}}から重要なアイデアを抽出する」列を追加。
充実:検索を可能にするために、"{{住所}}の郵便番号を検索 "カラムを追加。
これらのステップにより、ユーザーは簡単に使い始めることができる。このツールは、データの質を保証するために、実験と反復を重視している。
アプリケーションシナリオ
- モデルのテストと比較
ユーザが自分のデータで最新モデルを試したい。質問を含むデータセットをインポートする。複数の列を作成し、それぞれ異なるモデルで回答する。LLMと品質を比較するために判定列を追加します。開発者が最適なモデルを選択するのに最適。 - キューの最適化
顧客リクエスト自動応答アプリケーションを構築する。サンプルリクエストデータセットをロードする。さまざまなプロンプトとモデルを繰り返し、応答を生成する。セルを編集してフィードバックを提供し、数ショットの例を自動的に追加します。効率的なプロンプトの構築に最適 - データのクレンジングと変換
データセット列のテキストが乱れている。句読点の除去や正規化を促すプロンプトとともに新しい列を追加。大量のデータを高速処理。データサイエンティストの前処理に最適。 - データ分類
質問トピックのようにコンテンツを分類する。プロンプトで分類された列を追加します。手動検証および再生成により精度が向上。ハブデータセットの分析に最適。 - データ分析と抽出
本文の主要なアイデアを抽出する。カラムを追加して要約したり、プロンプトで抽出する。リアルタイムの情報を引き出す検索が可能。研究プロジェクトに最適。 - データの豊富さ
住所や郵便番号など不足している項目を追加。ヒント付きの列を追加し、ウェブ検索を有効にする。正確な追加を保証します。完全なデータセットに適しています。 - 合成データ生成
電子メールなどの仮想データをプライバシー保護。バイオカラムを生成し、それに基づいてコンテンツを生成します。テストやプロトタイピングに最適。
QA
- AI Sheetsはどのようなモデルをサポートしていますか?
ハギング・フェイス・ハブをサポートするオープンソースのモデルは、推論プロバイダーを通じて入手可能である。 gpt-oss またはOpenAI APIに準拠したカスタムLLM。 - 画像列の生成方法
オブジェクト名}}のアイソメトリックアイコンを生成 "のようなプロンプトを使用し、black-forest-labs/FLUX.1-devのようなイメージモデルを選択。 Hugging Face APIで修正。 - フィードバックはどのように機能するのか?
AIセルや「いいね!」を編集する。これらは数ショット例となる。再生時の列に適用する。 - エクスポート後の展開方法は?
config.ymlとスクリプトを使用してHFジョブを実行する。より大きなデータセットを生成するために行数を指定する。 - 定期購読は必要ですか?
オンライン無料トライアル。ローカルまたはそれ以上の推論にPROサブスクリプションで20倍の使用率を得る。 - データ容量の上限は?
1000行までのアップロードまたは生成。列数は無制限。ジョブズでさらに拡張。 - ウェブ検索を有効にするには?
列構成スイッチで検索を切り替えます。モデルは最新の情報を引き出します。


























