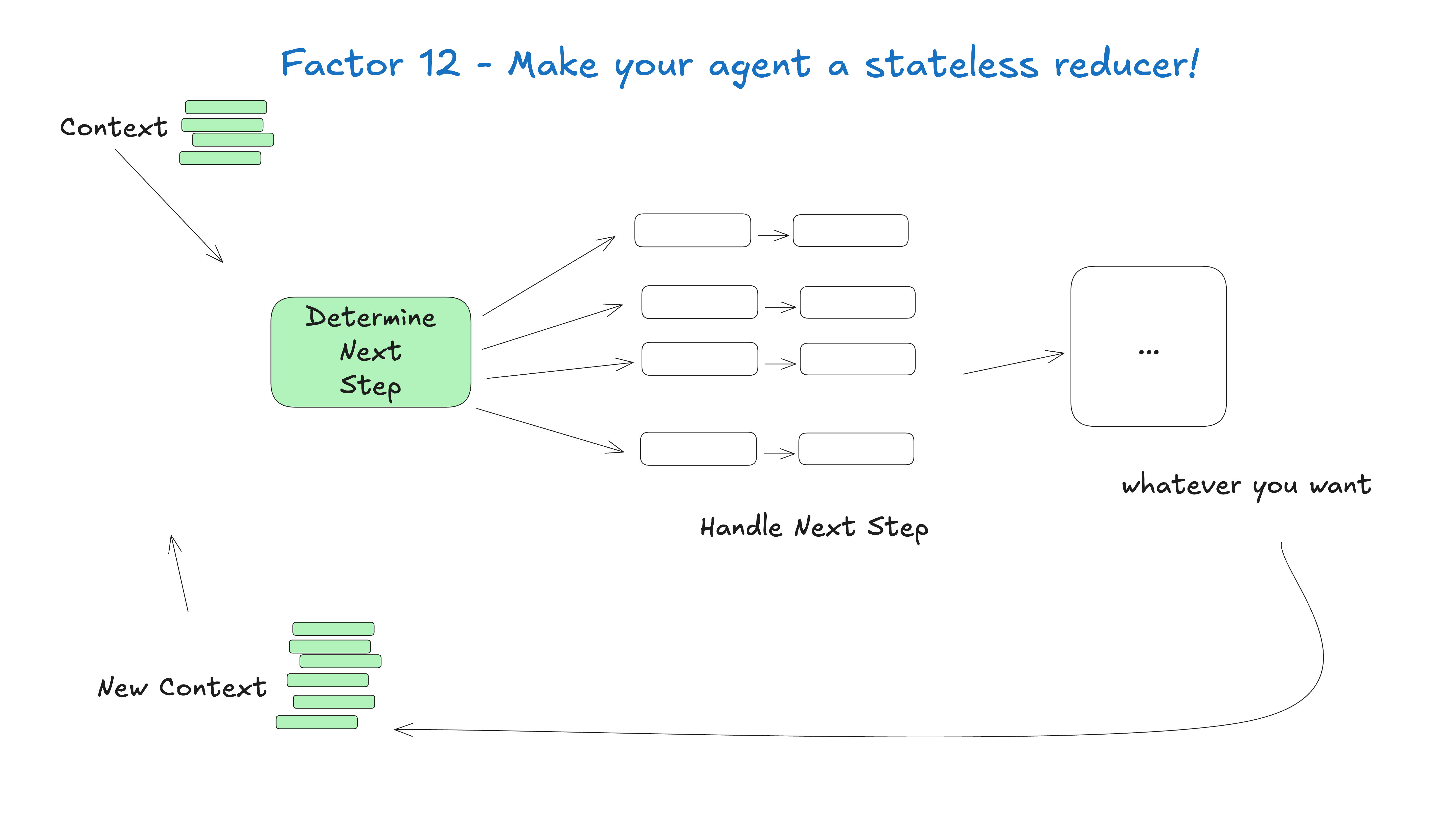
何でもこなそうとする一枚岩のインテリジェンスを構築するのではなく、一つのことをうまくこなせる、小さく集中したインテリジェンスを構築する方がいい。インテリジェンティアは、より大きな、大部分は決定論的なシステムにおけるひとつの構成要素にすぎない。

ここでの重要な洞察は、大きな言語モデルの限界にある。タスクが大きく複雑であればあるほど、より多くのステップが必要となり、それはより長いコンテキスト・ウィンドウを意味する。コンテキストが大きくなればなるほど、大きな言語モデルは迷子になったり、フォーカスを失ったりする可能性が高くなる。インテリジェンスが特定のドメインに集中し、最大3~10ステップ、おそらく20ステップを実行できるようにすることで、コンテキスト・ウィンドウを管理しやすくし、ビッグ・ランゲージ・モデルの高いパフォーマンスを維持することができる。
文脈が大きくなると、大規模な言語モデルは迷子になったり、フォーカスを失ったりしやすくなる
小さく集中したインテリジェンスの利点
- 制御されたコンテキストコンテキストウィンドウが小さいほど、大規模言語モデルの性能が向上する
- 明確な責任各インテリジェンスには、明確に定義された範囲と目的がある。
- より高い信頼性複雑なワークフローに迷いにくい
- テストが容易特定の機能のテストと検証が容易に
- デバッグの改善問題発生時の特定と修正が容易
大きな言語モデルが賢くなったらどうなるか?
もし、大きな言語モデルが100以上のステップを持つワークフローを扱えるほど賢くなったとしても、我々はまだこの作業をする必要があるのだろうか?
手短に言えば、そうだ。インテリゲンチアや大規模な言語モデルが進歩するにつれて、以下のようになる。 おそらく は、より長いコンテキスト・ウィンドウを扱うために、自然に拡張される。これは、より大きなDAGのより多くの部分を処理することを意味します。この小規模で集中的なアプローチにより、今日確実に結果を得ることができ、また、大規模な言語モデルのコンテキストウィンドウがより信頼できるものになるにつれて、インテリジェンスが徐々に拡張されていくことに備えることができます。 (以前に大規模な決定論的コードベースをリファクタリングしたことがある人なら、おそらく今、首をかしげていることだろう)。

ここで重要なのは、インテリジェンスのサイズ/範囲を意識的にコントロールし、質を維持する方法でのみ拡大することである。例えば NotebookLMを作ったチームのコメント:
AIを構築する上で、最も魔法のような瞬間はいつも、モデルの能力の限界に非常に、非常に、非常に近づいたときに訪れると思う
その境界線がどこにあろうと、それを見つけ、一貫して正しく保つことができれば、素晴らしい経験を築くことができる。ここに構築できる堀はたくさんあるが、いつものように、それにはある程度の工学的厳密さが必要だ。