小さくする:モデル蒸留で0.6億モデルを235億モデルに見せる方法
大規模言語モデル(LLM)は優れているが、計算コストが高く、推論速度が遅いため、実用化には大きな障壁となる。効果的な解決策はモデル蒸留である。まず、強力な教師モデル(大パラメータモデル)を使用して高品質のアノテーションデータを生成し、次にこのデータを使用して、より小さく経済的な生徒モデル(小パラメータモデル)を「教える」。次に、このデータを使用して、より小さく、より費用対効果の高い「生徒モデル」(小パラメータ・モデル)を「ティーチング」する。このようにして、小さなモデルは、与えられたタスクにおいて、大きなモデルに近いパフォーマンスを達成することができる。
本稿では、テキストから物流情報(受取人、住所、電話番号)を抽出することを例にとり、0.6Bのパラメータ化された Qwen3-0.6B モデルの場合、情報抽出タスクの精度は14%から98%に向上し、これは大規模モデルの結果に匹敵する。
最適化前後の結果の比較は非常に視覚的だ:

プログラム・コア・プロセス
プロセス全体は、3つの重要なステップに分かれている:
- データ準備235Bの大規模なモデルを教師モデルとして、仮想住所の記述を一括処理し、構造化JSONデータを高品質な学習セットとして生成する。実際の業務では、実際のシーンデータを利用することが望ましい。
- モデリングの微調整前のステップで生成されたデータを使って
Qwen3-0.6Bモデルは微調整される。このプロセスではms-swiftこのフレームワークは、複雑な微調整を1行のコマンドで済ませることができる。 - 効果検証パフォーマンス向上を定量化し、本番環境におけるモデルの安定性と精度を保証するために、独立したテストセットで微調整前後のモデルパフォーマンスを評価します。
I. コンピューティング環境の準備
大きなモデルの微調整には GPU コンピューティング環境を構築し GPU ドライブCUDA 和 cuDNN.これらの依存関係を手動で設定するのは、面倒なだけでなく、エラーが発生しやすい。デプロイを簡単にするために GPU プリインストールされたクラウドサーバーインスタンスを選択した場合 GPU ドライバーのイメージから、微調整作業を素早く開始することができます。
このプログラムは、無料のトライアル・リソースを通じて体験することができます。トライアル期間中に作成されたリソースやデータは、トライアル終了時に消去されます。長期間使用する必要がある場合は、公式ドキュメントのマニュアル作成ガイドラインを参照してください。
- ページガイドに従ってリソースを作成すると、右側に作成の進捗状況がリアルタイムで表示されます。
- 作成したら、リモート接続機能を使って
GPUクラウドサーバー。
リモート接続」ボタンをクリックし、提供された認証情報でログインする。
モデルのダウンロードと微調整
マジックマッチコミュニティ(ModelScope)で利用可能 ms-swift モデルの微調整という複雑なプロセスを劇的に単純化できるフレームワークである。
1.依存関係のインストール
このプログラムは、2つのコア・コンポーネントに依存している:
ms-swiftMagic Hitchコミュニティが提供する、モデルのダウンロード、微調整、ウェイトマージを統合した高性能トレーニングフレームワーク。vllmこのフレームワークは、高性能な推論をサポートし、モデル効果の検証を容易にし、サービスに関する推論を生成します。APIビジネス通話
ターミナルで以下のコマンドを実行し、依存関係をインストールする(約5分かかる):
pip3 install vllm==0.9.0.1 ms-swift==3.5.0
2.インプリメンテーション・モデルの微調整
以下のスクリプトを実行することで、モデルのダウンロード、データ準備、モデルの微調整、ウェイトの結合の全プロセスを自動化することができます。
# 进入 /root 目录
cd /root && \
# 下载微调脚本 sft.sh
curl -f -o sft.sh "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250623/cggwpz/sft.sh" && \
# 执行微调脚本
bash sft.sh
微調整には10分ほどかかる。sft.sh スクリプトの核となるコマンドは以下の通り:
swift sft \
--model Qwen/Qwen3-0.6B \
--train_type lora \
--dataset 'train.jsonl' \
--torch_dtype bfloat16 \
--num_train_epochs 10 \
--per_device_train_batch_size 20 \
--per_device_eval_batch_size 20 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--save_steps 1 \
--save_total_limit 2 \
--logging_steps 2 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
主要なパラメータのいくつかをここに記す:
--train_type lora微調整に LoRA (Low-Rank Adaptation) 法を使用する。これは、完全なファインチューニングに比べ、追加する重みの数が少なく、計算資源を大幅に削減できるパラメータ効率の良いファインチューニング手法です。--lora_rankLoRA 行列のランク。ランクが大きいほど、複雑なタスクへの適合度が高くなるが、大きすぎるとオーバーフィッティングになる可能性がある。--lora_alphaLoRAのスケーリングファクター。learning_rate同様に、ウエイトの更新の大きさを調整する。--num_train_epochsトレーニングラウンド。モデルがどの程度深くデータを学習するかを決定する。
訓練プロセス中、端末は訓練セットと検証セットにおけるモデルの損失(ロス)の変化をリアルタイムで表示する。

以下の出力が表示されたら、モデルの微調整とウェイトのマージが正常に完了したことを示している:
✓ swift export 命令执行成功
检查合并结果...
✓ 合并目录创建成功: output/v0-xxx-xxx/checkpoint-50-merged
✓ LoRA权重合并完成!
合并后的模型路径: output/v0-xxx-xxx/checkpoint-50-merged
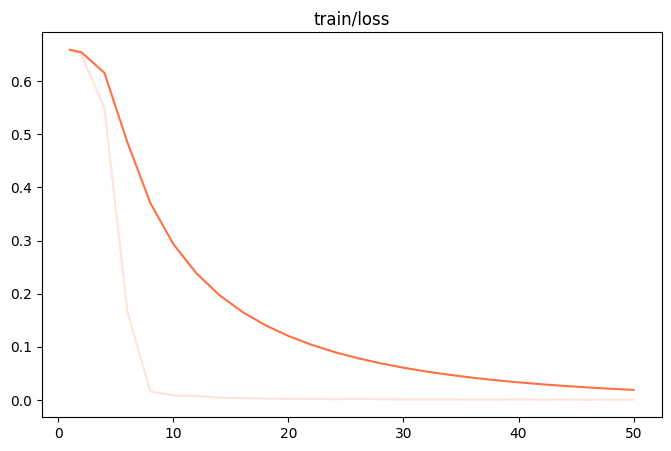
微調整が完了したら output/v0-xxx-xxx/images ディレクトリで train_loss.png 和 eval_loss.png モデルのトレーニング状態を視覚化する2つのチャート。
| train_loss (トレーニングセットの損失) | eval_loss (検証セットの損失) |
|---|---|
 |
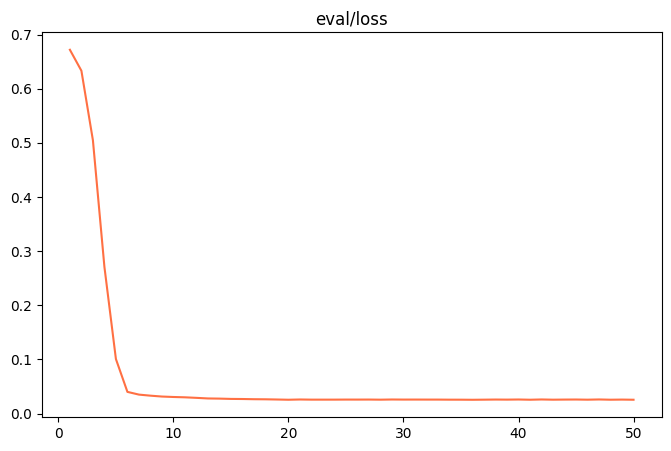 |
- フィット感が悪いもし
train_loss和eval_lossトレーニングの最後に、まだ大幅な減少傾向が見られる場合は、次の項目を追加してみてほしい。num_train_epochs或lora_rank。 - オーバーフィッティングもし
train_loss減少が続いているがeval_lossその代わりに、この値は上昇し始め、モデルが訓練データを過剰に学習したことを示す。num_train_epochs或lora_rank。 - フィット感両方の曲線が水平になれば、モデル学習が理想的な状態に達したことを示す。
III.モデル効果の検証
システマティック・レビューは、本番環境にデプロイする前のプロセスにおいて不可欠な部分である。
1.テストデータの準備
テストデータは訓練データと同じ形式であるべきで、モデルの汎化能力を評価するためには、モデルにとって全く新しく未知のものでなければならない。
cd /root && \
# 下载测试数据 test.jsonl
curl -o test.jsonl "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250610/mhxmdw/test_with_system.jsonl"
テストデータのサンプルを以下に示す:
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "电话:23204753945:大理市大理市人民路25号 大理古城国际酒店 3号楼:收件者:段丽娟"}, {"role": "assistant", "content": "{\"province\": \"云南省\", \"city\": \"大理市\", ...}"}]}
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "天津市河西区珠江道21号金泰大厦3层 , 接收人慕容修远 , MOBILE:22323185576"}, {"role": "assistant", "content": "{\"province\": \"天津市\", \"city\": \"天津市\", ...}"}]}
2.評価指標の設計
評価基準は、事業目的と密接に整合している必要がある。この例では、アウトプットが正当なものであるかどうかを判断することが重要であるばかりでなく JSONひとつひとつ比較しなければならない。 JSON の各キーと値のペアは
3.初期モデルの有効性の評価
第一に、微調整されていない Qwen3-0.6B モデルがテストされた。よく設計された詳細なプロンプトを使っても、テストされた400のサンプルに対するその精度はわずかである。 14%。
所有预测完成! 结果已保存到 predicted_labels_without_sft.jsonl
样本数: 400 条
响应正确: 56 条
响应错误: 344 条
评估脚本运行完成
4.微調整モデルの検証
次に、微調整したモデルを同じテストセットで評価した。タスクに特化した知識がモデルのパラメータに「ベイク」され、複雑な指示が不要になったため、非常に簡潔な手がかり単語で優れたパフォーマンスを達成できるようになったことが大きな変化である。
キュー・ワードのショート・バージョン:
你是一个专业的信息抽取助手,专门负责从中文文本中提取收件人的JSON信息,包含的Key有province(省份)、city(城市名称)、district(区县名称)、specific_location(街道、门牌号、小区、楼栋等详细信息)、name(收件人姓名)、phone(联系电话)
評価スクリプトを実行した結果、ファインチューニング・モデルの精度は、3.5%に達した。 98%質的な飛躍を遂げた。
所有预测完成! 结果已保存到 predicted_labels.jsonl
样本数: 400 条
响应正确: 392 条
响应错误: 8 条
评估脚本运行完成
この結果は、モデル蒸留と LoRA ファインチューニングは、小さなモデルを特定のドメインに適用することを可能にし、AI技術がスケールするためのコストと効率のハードルをクリアする、非常に費用対効果の高いソリューションである。