



RAGLight is a lightweight, modular Python library designed to enable Retrieval Augmented Generation (RAG). It improves the contextual understanding of Large Language Models (LLMs) by combining document retrieval and natural language generation.With support for multiple language models, embedded models, and vector stores, RAGLight is ideal for developers to quickly build context-aware AI applications. Designed with simplicity and flexibility in mind, RAGLight can easily integrate data from local folders or GitHub repositories to generate accurate answers. Ollama or LMStudio, supports localized deployments and is suitable for privacy- and cost-sensitive projects.
Function List
- Multiple data sources are supported: knowledge bases can be imported from local folders (e.g. PDF, text files) or GitHub repositories.
- modularization RAG Pipeline: Combines document retrieval and language generation with support for standard RAG, Agentic RAG and RAT (Retrieval Augmented Thinking) modes.
- Flexible Model Integration: Supports Ollama and LMStudio models for large languages such as
llama3。 - Efficient Vector Storage: Generate document vectors using Chroma or HuggingFace embedding models to support fast similarity searches.
- Customized configuration: allows the user to adjust the embedding model, vector storage paths and retrieval parameters (e.g.
k(Value). - Automate document processing: Automatically extract and index document content from specified sources to simplify knowledge base construction.
Using Help
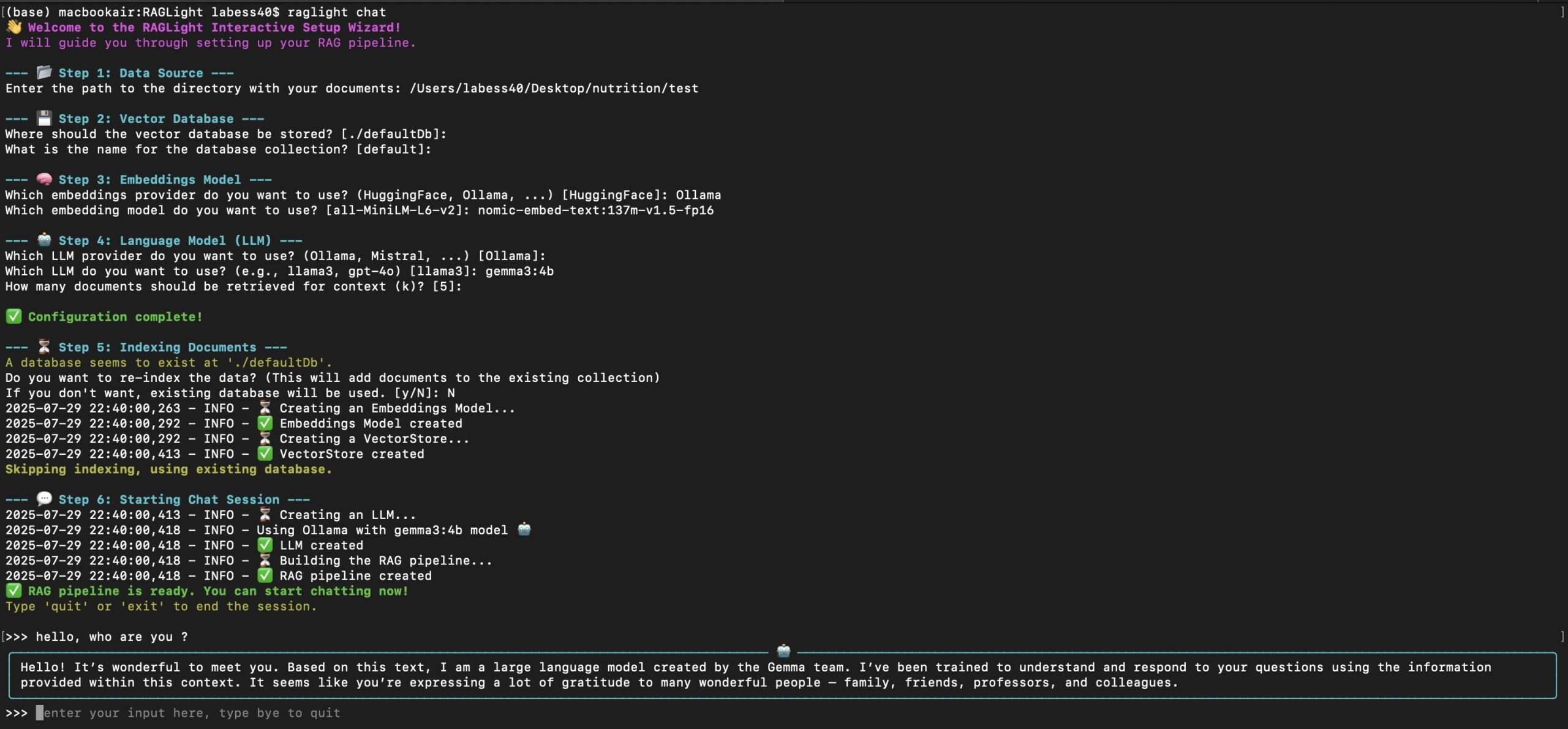
Installation process
The installation and use of RAGLight requires a Python environment and a running Ollama or LMStudio.The following are detailed steps:
- Installing Python and dependencies
Make sure that Python 3.8 or later is installed on your system. Use the following command to install RAGLight:pip install raglightIf you use HuggingFace embedded models, you need to install additional dependencies:
pip install sentence-transformers - Install and run Ollama or LMStudio
- Download and install Ollama (https://ollama.ai) or LMStudio.
- Pulling models in Ollama, for example:
ollama pull llama3 - Make sure the model is loaded and running in Ollama or LMStudio.
- Configuration environment
Create a project folder to prepare the knowledge base data (e.g. PDF folder or GitHub repository URL). Ensure that you have a good internet connection to access GitHub or HuggingFace.
Creating Simple RAG Pipelines with RAGLight
RAGLight provides a clean API to build RAG pipelines. Below is a basic example for building a knowledge base and generating answers from local folders and GitHub repositories:
from raglight.rag.simple_rag_api import RAGPipeline
from raglight.models.data_source_model import FolderSource, GitHubSource
from raglight.config.settings import Settings
Settings.setup_logging()
# 定义知识库来源
knowledge_base = [
FolderSource(path="/path/to/your/folder/knowledge_base"),
GitHubSource(url="https://github.com/Bessouat40/RAGLight")
]
# 初始化 RAG 管道
pipeline = RAGPipeline(
knowledge_base=knowledge_base,
model_name="llama3",
provider=Settings.OLLAMA,
k=5
)
# 构建管道(处理文档并创建向量存储)
pipeline.build()
# 生成回答
response = pipeline.generate("如何使用 RAGLight 创建一个简单的 RAG 管道?")
print(response)
Featured Function Operation
- Supports multiple data sources
RAGLight allows users to import data from local folders or GitHub repositories.- Local Folder: Place PDF or text files in a specified folder, e.g.
/path/to/knowledge_base。 - GitHub repositories: Provide the repository URL (e.g.
https://github.com/Bessouat40/RAGLight), RAGLight automatically extracts documents from the repository.
Example Configuration:
knowledge_base = [ FolderSource(path="/data/knowledge_base"), GitHubSource(url="https://github.com/Bessouat40/RAGLight") ] - Local Folder: Place PDF or text files in a specified folder, e.g.
- Standard RAG Pipes
The standard RAG pipeline combines document retrieval and generation. After a user enters a query, RAGLight converts the query into a vector, retrieves relevant document snippets through a similarity search, and inputs these snippets into the LLM as context to generate an answer.
Operational Steps:- initialization
RAGPipelineand specify the knowledge base, model andkvalue (number of retrieved documents). - invocations
pipeline.build()Processes documents and generates vector stores. - utilization
pipeline.generate("查询")Get Answers.
- initialization
- Agentic RAG and RAT modes
- Agentic RAG: By
AgenticRAGPipelineimplementation, adding intelligent body functions to support multi-step reasoning and dynamic adjustment of retrieval strategies.
Example:from raglight.rag.simple_agentic_rag_api import AgenticRAGPipeline from raglight.config.agentic_rag_config import SimpleAgenticRAGConfig config = SimpleAgenticRAGConfig(k=5, max_steps=4) pipeline = AgenticRAGPipeline(knowledge_base=knowledge_base, config=config) pipeline.build() response = pipeline.generate("如何优化 RAGLight 的检索效率?") print(response) - RAT (Retrieval Augmented Thinking): By
RATPipelineRealization, additional reflection steps (reflectionparameters) to improve the logic and accuracy of responses.
Example:from raglight.rat.simple_rat_api import RATPipeline pipeline = RATPipeline( knowledge_base=knowledge_base, model_name="llama3", reasoning_model_name="deepseek-r1:1.5b", reflection=2, provider=Settings.OLLAMA ) pipeline.build() response = pipeline.generate("如何简化 RAGLight 的配置?") print(response)
- Agentic RAG: By
- Custom Vector Storage
RAGLight uses Chroma as the default vector store and supports HuggingFace embedding models (e.g.all-MiniLM-L6-v2). User-definable storage paths and collection names:from raglight.config.vector_store_config import VectorStoreConfig vector_store_config = VectorStoreConfig( embedding_model="all-MiniLM-L6-v2", provider=Settings.HUGGINGFACE, database=Settings.CHROMA, persist_directory="./defaultDb", collection_name="my_collection" )
Handling Precautions
- Ensure that the Ollama or LMStudio runtime model is loaded, otherwise an error will be reported.
- The local folder path should contain valid documents (e.g. PDF, TXT) and the GitHub repository should be publicly accessible.
- align
kvalue to control the number of documents retrieved.k=5It is usually a choice that balances efficiency and accuracy. - If you are using the HuggingFace embedded model, make sure that the HuggingFace API is accessible to the network.
application scenario
- academic research
Researchers can import PDFs of papers into a local folder and use RAGLight to quickly search the literature and generate summaries or answer questions. For example, enter "recent advances in a field" to get contextualized answers to related papers. - Enterprise Knowledge Base
Organizations can import internal documents (e.g., technical manuals, FAQs) into RAGLight to build an intelligent Q&A system. After employees enter questions, the system retrieves and generates accurate answers from the documents. - Developer Tools
Developers can use the code documentation in GitHub repositories as a knowledge base to quickly look up API usage or code snippets. For example, type "how to call a function" to get the documentation. - Educational aids
Teachers or students can import textbooks or course notes into RAGLight to generate targeted answers or summaries of their learning. For example, enter "Explain a concept" to access relevant content from the textbook.
QA
- What language models does RAGLight support?
RAGLight supports models provided by Ollama and LMStudio, such asllama3、deepseek-r1:1.5betc. The user needs to preload the model in Ollama or LMStudio. - How do I add a custom data source?
utilizationFolderSourceSpecify the local folder path, orGitHubSourceSpecify a public GitHub repository URL. make sure the path is valid and the file format is supported (e.g. PDF, TXT). - How to optimize search accuracy?
risekvalues to retrieve more documents, or use RAT mode to enable reflection. Select a high-quality embedding model (e.g.all-MiniLM-L6-v2) also improves accuracy. - Does it support cloud deployment?
RAGLight is designed primarily for local deployment and needs to be run with Ollama or LMStudio. It does not directly support the cloud, but can be deployed via containerization (e.g. Docker).


























