



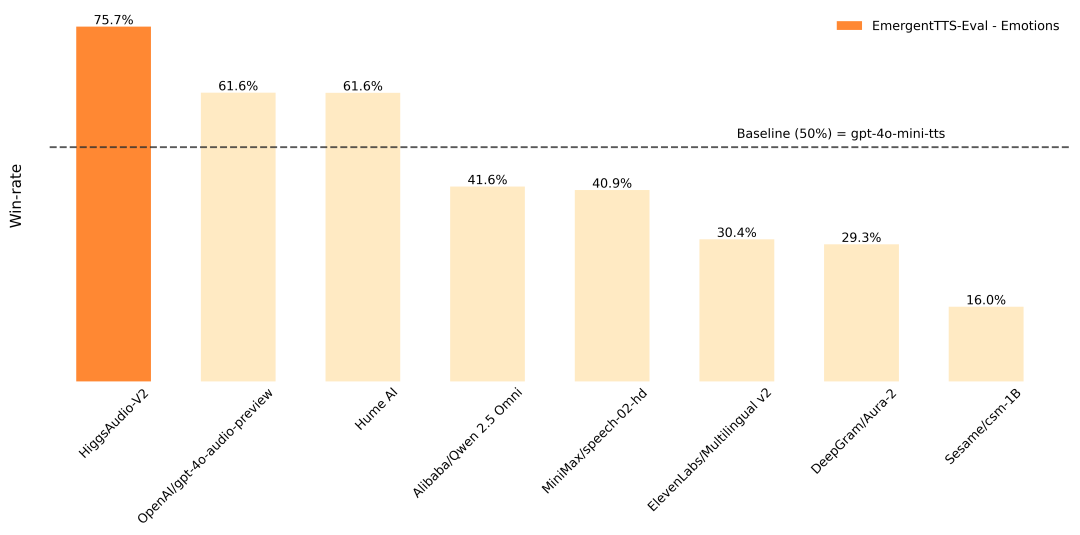
Higgs Audio is an open source text-to-speech (TTS) project developed by Boson AI, focused on generating high-quality, emotionally rich speech and multi-character dialog. The project is based on more than 10 million hours of audio data training, and supports zero-sample speech cloning, natural dialog generation, and multi-language speech output.Higgs Audio v2 adopts the innovative Dual-FFN architecture and Unified Audio Phrase Sorter, which can efficiently process both text and audio information to generate realistic speech effects. It performs well in the EmergentTTS-Eval benchmark with an emotional expression win rate of 75.7%, significantly better than other models. The project provides detailed code and installation guides for developers, researchers and creators, and is widely used in audio content creation, virtual assistants and education.
Function List
- Generate high-quality speech: Convert text into natural, emotionally rich speech that supports a wide range of intonations and emotional expressions.
- Multi-Role Dialog Generation: Supports multi-role speech generation to simulate pauses, interruptions and overlaps in natural dialog.
- Zero-sample voice cloning: quickly generate the target character's voice from reference audio without additional training.
- Multi-language support: Supports speech generation in English, Chinese, German, Korean and other languages.
- Combination of music and speech: can generate background music and speech at the same time, suitable for audio storytelling or immersive experiences.
- Efficient inference: Supports running on edge devices such as the Jetson Orin Nano with a low resource footprint.
- Open source code: provide a complete code base and API, support developers to customize the development.
Using Help
Installation process
Higgs Audio is an open source project, hosted on GitHub, the installation process is simple but requires some development environment support. Here are the detailed installation steps for different environments:
1. Cloning the code base
First, clone Higgs Audio's GitHub repository locally:
git clone https://github.com/boson-ai/higgs-audio.git
cd higgs-audio
2. Configuration environment
Higgs Audio offers several ways to configure the environment, including virtual environments, Conda, and uv. Python 3.10 and above is recommended. Here are the steps to configure a virtual environment:
python3 -m venv higgs_audio_env
source higgs_audio_env/bin/activate
pip install -r requirements.txt
pip install -e .
If you use Conda:
conda create -n higgs_audio_env python=3.10
conda activate higgs_audio_env
pip install -r requirements.txt
pip install -e .
For high throughput scenarios, it is recommended to use the vLLM Engine. Reference examples/vllm folder, run the following command to start the API server:
python -m vllm.entrypoints.openai.api_server --model bosonai/higgs-audio-v2-generation-3B-base --tensor-parallel-size 4 --gpu-memory-utilization 0.9
hardware requirement: For best performance, a GPU with at least 24GB of video memory (such as the NVIDIA RTX 4090) is recommended. Edge devices such as the Jetson Orin Nano can also run smaller models.
3. Verification of installation
Once the installation is complete, run the following Python code to verify that the environment is properly configured:
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine
engine = HiggsAudioServeEngine(
"bosonai/higgs-audio-v2-generation-3B-base",
"bosonai/higgs-audio-v2-tokenizer",
device="cuda"
)
output = engine.generate(content="Hello, welcome to Higgs Audio!", voice_profile="neutral")
If an audio file is output, the installation was successful.
Functional operation flow
Higgs Audio's core features include text-to-speech, multi-character dialog generation, and voice cloning. Below are the steps to do so:
1. Text-to-speech
Higgs Audio supports the conversion of text into natural speech, and emotional expressions can be made through the voice_profile Parameter control. For example, to generate a voice with an "urgent" tone:
curl http://localhost:8000/v1/audio/generation -H "Content-Type: application/json" -d '{"text": "Security alert: Unauthorized access detected", "voice_profile": "urgent"}'
Users can specify different emotion labels (e.g. happy、sad、neutral), the model automatically adjusts intonation and pacing based on the semantics of the text.
2. Multi-actor dialog generation
Higgs Audio specializes in generating multi-character conversations that simulate natural interactions in real-life scenarios. The user has to provide text containing character tags, for example:
dialogue = """
SPEAKER_0: Hey, have you tried Higgs Audio yet?
SPEAKER_1: Yeah, it’s amazing! The voices sound so real!
"""
output = engine.generate(content=dialogue, multi_speaker=True)
The model generates different voices based on character tags, automatically adding pauses and changes in tone, making it suitable for use in audiobooks or game dialog.
3. Zero-sample speech cloning
The user can provide a piece of reference audio and the model will clone its speech features. Example:
output = engine.generate(
content="This is a test sentence.",
reference_audio="path/to/reference.wav",
voice_profile="cloned"
)
The reference audio should be a clear single voice with a recommended length of 5-10 seconds. The cloned voice can be used for personalized audio generation.
4. Multilingual support
Higgs Audio supports multilingual speech generation. Users just need to specify the language content in the text, and the model will be automatically adapted. For example:
output = engine.generate(content="你好,欢迎体验Higgs Audio!", voice_profile="neutral")
Currently supports English, Chinese, German, and Korean, but the handling of Chinese numbers and symbols may have limitations and needs further optimization.
5. Music and speech integration
Higgs Audio generates speech with background music for immersive experiences. Users are required to add music tags to the text:
content = "[music_start] The stars shimmered above. [music_end] This is a magical night."
output = engine.generate(content=content, background_music=True)
The model generates background music based on tags and blends it with speech.
Precautions for use
- Hardware Optimization: Running on the GPU can significantly improve inference speed. Edge devices need to use smaller models to reduce resource usage.
- input format: Text input needs to be clear, avoiding complex symbols or formatting errors to ensure generation.
- Reference Audio: Voice cloning needs to provide high quality reference audio to avoid interference from background noise.
- multilingualism: Chinese numerals and percent signs may result in poor generation, and it is recommended that complex symbols be avoided.
application scenario
- Audiobook production
Higgs Audio transforms book text into emotionally rich audiobooks with support for multi-character dialog and soundtracks for publishers or individual creators to produce high-quality audiobooks. - Educational content creation
Teachers can use Higgs Audio to generate speech or multilingual instructional audio of historical figures to enhance the immersion and interactivity of their lessons. - game development
Developers can utilize the multi-character dialog feature to generate dynamic character voices for games that support natural interruptions and emotional expressions to enhance the gaming experience. - Virtual Assistant Development
Businesses can develop virtual assistants based on Higgs Audio with personalized voice for customer service or smart devices. - dubbing (filmmaking)
Higgs Audio's voice cloning and multi-language support is ideal for generating voiceovers for movie and TV productions, quickly adapting to different characters and languages.
QA
- What languages does Higgs Audio support?
Currently supports English, Chinese, German, Korean and other languages, with plans to expand support for more languages in the future. - How to optimize the stability of voice cloning?
Provide clear, single-person reference audio that is 5-10 seconds in length, avoiding direct use of generated audio as a reference to maintain emotional control. - Does it require a GPU to run?
GPUs boost performance, but smaller models can run on edge devices such as the Jetson Orin Nano for lightweight applications. - What are the limitations of Chinese speech generation?
Chinese numerals and symbols may cause poor generation, it is recommended to simplify the input text, which will be optimized in future versions. - How do you handle voice distinctions in multi-character conversations?
By adding character tags (e.g., SPEAKER_0) to the text, the model automatically generates different voices and simulates the natural rhythm of conversation.




























