



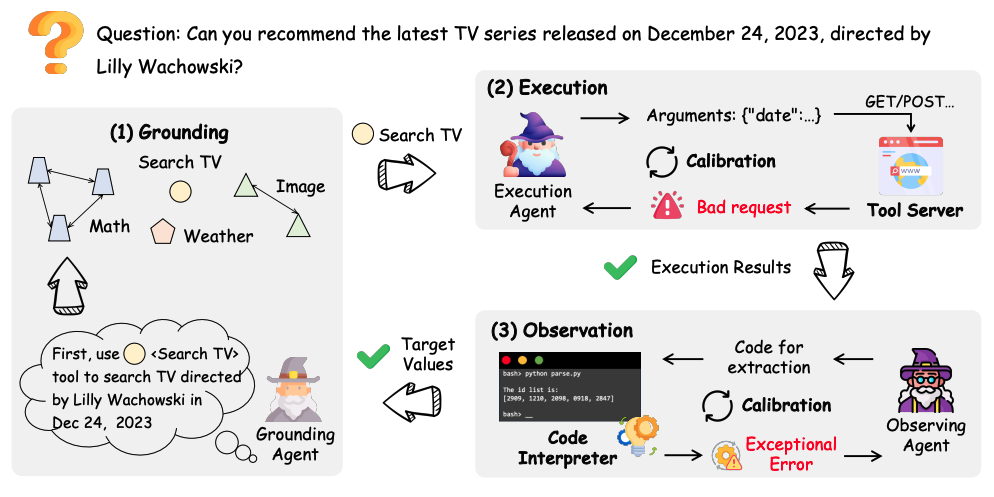
CoAgents is an innovative multi-intelligence collaboration framework designed to enhance the ability of Large Language Models (LLMs) to use external tools and APIs. The core idea of the framework is to decompose complex tool usage tasks into three specialized intelligences: Grounding Agent, which is responsible for generating tool usage instructions; Execution Agent, which is responsible for performing specific tool operations; and Execution Agent, which is responsible for retrieving results from tools. "They are: the Grounding Agent, which is responsible for generating instructions for the tool, the Execution Agent, which is responsible for performing specific tool operations, and the Observing Agent, which is responsible for extracting key information from the results returned by the tool. These three intelligences interact and collaborate to form a complete feedback loop. When the tool environment returns errors or feedback, the Executing Agent and Observing Agent are able to iteratively adjust and self-correct so that the model learns how to use the tool more accurately and efficiently to accomplish tasks. The implementation code for this project is open-sourced on GitHub, and a demo based on the TMDB (Movie Database) API is provided to help users understand and apply it.
Function List
- A framework for multi-intelligence collaboration: The innovative use of three separate intelligences (Foundation, Execution, and Observation) working in tandem breaks down the process of tool use into three steps: instruction generation, execution, and result analysis.
- Iterative learning and adaptation: When a tool executes incorrectly or with unsatisfactory results, the framework is able to receive feedback from the environment and drive the execution and observation agents to adjust and optimize themselves.
- Tool command generation: The Grounding Agent is responsible for understanding user intent and translating it into specific, executable instructions for using the tool.
- Tool implementation and results extraction: The Execution Agent calls the specified tool or API, while the Observing Agent accurately extracts valuable information from the raw data returned.
- Support for OpenAI models: The framework integrates with OpenAI's API and can be configured by the user to use the
gpt-3.5-turboA variety of models such as these serve as the driving core of the intelligences. - API key rotation: Supports adding multiple OpenAI API keys to a configuration and requesting them via a random selection policy to circumvent the rate limitation of a single key.
- Custom API endpoints: Users can flexibly configure the request address (Base URL) of the Open-AI API for easy access to third-party or self-built LLM services.
- TMDB Demo Case: A full demo script based on the TMDB movie database API is provided
run_tmdb.py, shows how intelligent bodies can collaborate to look up movie information.
Using Help
CoAgents is an experimental Python-based framework designed to explore how to make large language models better at learning to use tools. The following section details how to configure and run the project.
1. Environment preparation and installation
First, you need an environment with Python installed. Then, run Python through thepipcommand installs the core dependency libraries required by the project. These libraries provide the base capabilities for the framework, such as thelangchainfor building intelligent body applications.openaifor interacting with large language models.
Open your terminal (command line tool) and execute the following command:
pip install langchain==0.0.338 openai==1.7.1 tiktoken==0.5.1 colorama==0.4.6
Note: Although the official documentation suggestslangchainutilization0.0.338version, but is equally compatible with newer versions.
2. Obtain and configure the API key
CoAgents relies on two types of external APIs for its operation:OpenAI API 和 TMDB API。
Configuring OpenAI API Keys
- You need to have one or more OpenAI API keys.
- In the root directory of the project, locate and open the file
./utilize/apis.py。 - In that file, you will see a file named
api_keys_listThe Python list. Add your OpenAI key string to this list.# 文件路径:./utilize/apis.py api_keys_list = [ 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx', # 在这里替换成你的第一个API密钥 'sk-yyyyyyyyyyyyyyyyyyyyyyyyyyyyyy', # 如果有多个,可以继续添加 ]The framework is designed with a clever mechanism: on each request, it randomly selects a key from the list. This effectively spreads out the request pressure and avoids program interruptions due to a single key reaching the frequency limit.
- If you use a third-party proxy service or a self-built LLM service, you can modify the
BASE_URLvariable to specify the API request address. If the official API is used, no modification is required.# 文件路径:./utilize/apis.py BASE_URL = 'https://api.openai.com/v1' # 如果需要,可修改为你的代理地址
Configuring TMDB API access tokens
- Visit the official website of TMDB (The Movie Database) and register an account.
- Request an API Access Token (Access Token) according to the TMDB guidelines.
- In the root directory of the CoAgents project, theCreate a new file manuallyand name it
access_token.txt。 - Paste the TMDB access token you obtained into this newly created file and save it.
3. Running the demo program
Once you have completed all of the above configurations, you can run the demo program that comes with the projectrun_tmdb.pyup. This program will show how CoAgents uses TMDB's API to query movie data.
Open a terminal, go to the root directory of the project, and execute the following command:
python run_tmdb.py
--model_name 'gpt-3.5-turbo'
--log_file './log_file.json'
--data_file <your_dataset_file>
--access_token_file './access_token.txt'
The meaning of each command line parameter is explained in detail below:
model_name: Specifies the large language model that drives the intelligentsia. Defaults togpt-3.5-turbo, you can tweak it in the code as needed.log_file: Specify a file path for logging interactions between intelligences as the program runs. This is useful for debugging and analysis.data_file: Specify the dataset file that contains the task data. You need to provide a data file that meets the format requirements and contains the task instructions to be queried.access_token_file: Specify the path to the file where the TMDB access token is stored. Here we are pointing to the just createdaccess_token.txt。
After executing this command, the CoAgents framework will start working. The base agent will generate a tool usage plan based on the tasks in the dataset, the executing agent will call the TMDB API, and the observing agent will extract the required information from the returned JSON data to finalize the query task and output the results. Detailed logs of the whole process will be logged in your specifiedlog_file.jsonDocumentation.
application scenario
- Intelligent API Calls
In scenarios where you need to interact with complex external APIs (e.g., social media, weather, financial data, etc.), CoAgents can automatically learn how to build requests, send them, and extract key information from the returned data without requiring developers to write fixed parsing code for each API. - Automated data query and analysis
Users can make a query request in natural language (e.g., "Help me find the five highest rated sci-fi movies released in 2023"), and CoAgents can decompose the request, execute the query by calling a database query tool (e.g., the TMDB API), and consolidate the results to produce an accurate answer. . - Complex task disassembly and execution
For complex tasks that require multiple steps and tools to complete, such as "planning a trip from Beijing to Shanghai, taking into account the weather, transportation, and accommodations," CoAgents' collaboration framework can break the task into subtasks such as weather query, flight booking, hotel query, and so on, and call the corresponding tools in turn to accomplish. - Automation of software or system operations
CoAgents can learn to operate software or operating systems with API interfaces. For example, by learning the file system API, it can realize the creation, movement and deletion of files; by learning the calendar API, it can help users automatically schedule meetings.
QA
- Which core intelligences does the CoAgents framework contain? What are their respective responsibilities?
The CoAgents framework contains three core intelligences:- Grounding Agent: Its main responsibility is to understand the user's task requirements and generate detailed instructions or plans for using a particular tool.
- Execution Agent: Responsible for actually calling and executing the appropriate tool or API based on the instructions generated by the base agent.
- Observing Agent: After the tool is executed, it is responsible for analyzing the returned results (usually JSON or text) and extracting key information from them that is useful to the user.
- What does CoAgents do if the tool implementation fails?
This is a core strength of the CoAgents framework. When an execution agent receives error feedback (e.g., the API returns an error code) after invoking a tool, this feedback is captured by the system. The execution and observation agents iteratively adjust to this feedback. They will try to fix the request parameters or change the policy, and then try to execute again, thus realizing a self-correcting learning process. - What API keys do I need to prepare before running a CoAgents program?
You need to prepare two types of API credentials:- OpenAI API Key: Used to drive the thinking and decision-making capabilities of an intelligent body (Agent) to support the
gpt-3.5-turboand other models. - TMDB API Access Token: API for accessing The Movie Database (The Movie Database) used in the project demo case.
- OpenAI API Key: Used to drive the thinking and decision-making capabilities of an intelligent body (Agent) to support the
- Can I replace or add new tools?
Yes. CoAgents is a framework that is inherently designed for easy access and use of tools. While the demo case uses the TMDB API, developers can extend the code to define new tools and make them available to intelligences. All that is required is for the base agent to learn to generate instructions to use the new tool and for the observing agent to learn to parse the returned results of the new tool.


























