

The most dystopian script in the tech industry is playing out. A tens of billions dollar security giant that got its start by blocking automated bots has taken it upon itself to build the simplest, and perhaps even the most powerful, automated crawler tool in the world today.
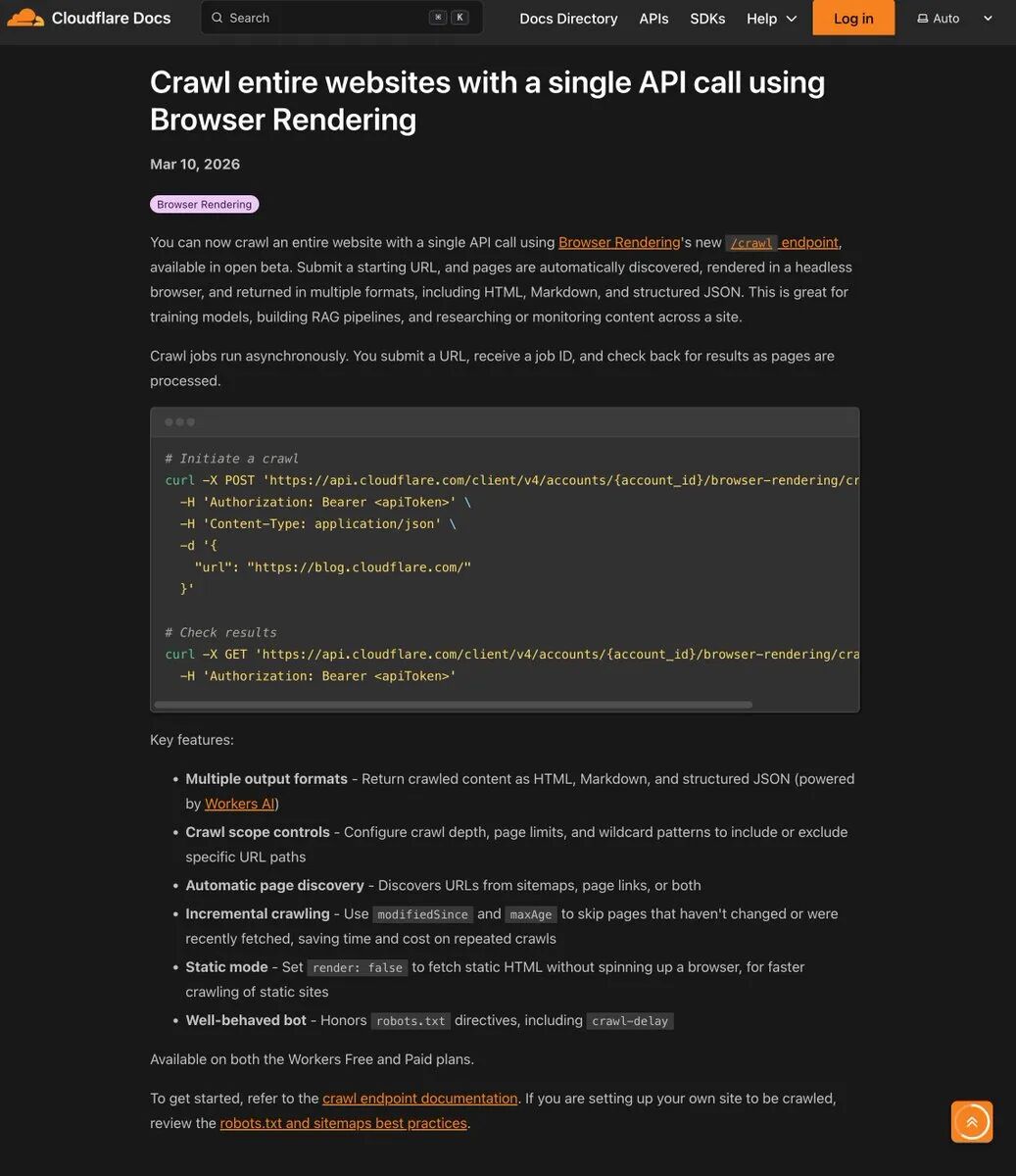
In March 2026, Cloudflare went live with a new Beta feature for Browser Rendering:/crawl API.
There's no complex framework to configure, no CAPTCHA to deal with, no Puppeteer or Playwright headless browser clusters with memory leaks to maintain on the server. All you need to do is send an HTTP POST request with a starting URL, and the rest of the page discovery, JavaScript rendering, and paging is done by the company's global edge network. At the end of the day, it will honestly spit out clean HTML, Markdown, or structured JSON to you.

Ironically, countless developers have been paying for Cloudflare's services to defend against crawlers for the past few years. Now, the same people are looking at documentation and learning how to use Cloudflare's API to crawl other people's websites.
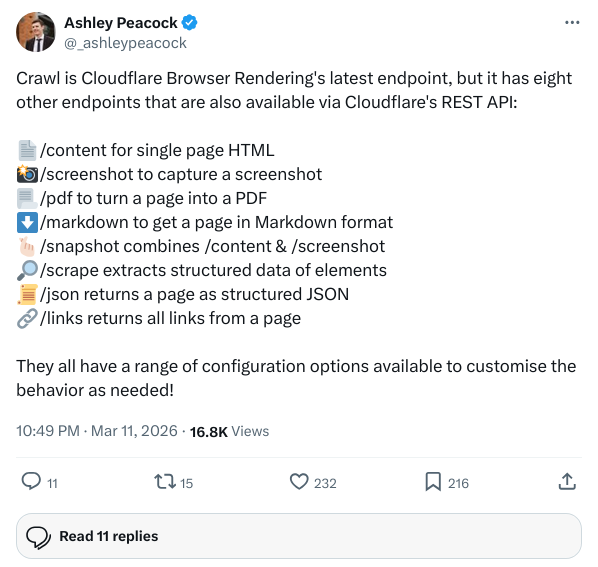
Hidden Ambitions: A Rendering Empire with 9 Endpoints
While all eyes were fixed on the /crawl When it comes to the shock, many people overlook the infrastructure behind it./crawl Not an isolated hack toy, it's the final piece of the puzzle in Cloudflare Browser Rendering's entire REST API matrix.
Look closely at the full list of current endpoints and you'll see that they've actually completely dismantled what the browser can do:
| starting point or ending point (in stories etc) | Functional Description |
|---|---|
/content |
Get the fully rendered single page HTML |
/screenshot |
Visual screenshot of the page |
/pdf |
Page to PDF |
/markdown |
Markdown extraction for AI |
/snapshot |
Contains a hybrid snapshot of content and visuals |
/scrape |
Structured crawling based on DOM nodes |
/json |
Direct output of extracted structured data in combination with Workers AI |
/links |
Topo Crawl Essential Full Page Link Extraction |
/crawl |
Automated Whole Site Crawl (new addition) |
In the past, you'd either have to use old Scrapy to hard-core static pages, or build a heavy set of Node.js services to run real browsers. Now Cloudflare turns this process into two minimalist steps:
- initiate a task: Submit the starting URL to the
/crawlThe Job ID of an asynchronous execution is immediately available to the user. - polling for: Take the Job ID and check the progress. Jobs can run in their data center for up to 7 days, and results are retained for 14 days.
The parameters built into the system give an extremely high degree of control. You can customize the parameters with the limit To set a maximum crawl limit of 100,000 pages, use the depth Limit link depth, or utilize includePatterns etc. wildcards only grab content under a specific path. Even more deadly is the render Parameters. If you only need to crawl purely static document stations, put the render set up as false, it will skip the browser rendering direct high-speed concurrent capture; if it is a single page application (SPA), turn on the render You can extract the content after executing JavaScript.
Zero-threshold drop strikes
This infrastructure-level descending blow immediately exerts a gravitational pull on the existing business ecosystem.
Developers of RAG (Retrieval Augmented Generation) applications are the first wave of beneficiaries. Big models need clean text, HTML tags are noise to them. Where developers used to have to write all sorts of regular extractors and cleaning scripts, they now get Markdown right back in a single request. ai data engineers, indie developers, and even small startup teams no longer need to hire a dedicated person to maintain a crawler pipeline.
But for companies that specialize in crawler SaaS, this is like taking a paycheck. Take Firecrawl, for example, whose core business model is to encapsulate crawlers into usable APIs, and now we're putting it on the table with Cloudflare:
| dimension (math.) | Cloudflare /crawl | Firecrawl |
|---|---|---|
| underlying positioning | Infrastructure-level primitive language APIs | SaaS that specializes in vertical scenarios |
| billing model | Browser-based billing | Billing by number of pages crawled |
| network of nodes | Large global pool of edge nodes | Relatively constrained server exports |
| usability | Requires a Cloudflare account with Workers | Foolproof registration and use |
| Structured Extraction | Native Integration Workers AI /json starting point or ending point (in stories etc) |
Built-in large model extraction for a better out-of-the-box experience |
Firecrawl still leads in product packaging and friendliness to users with no technical background. But Cloudflare has an insurmountable moat: compute cost and node size.
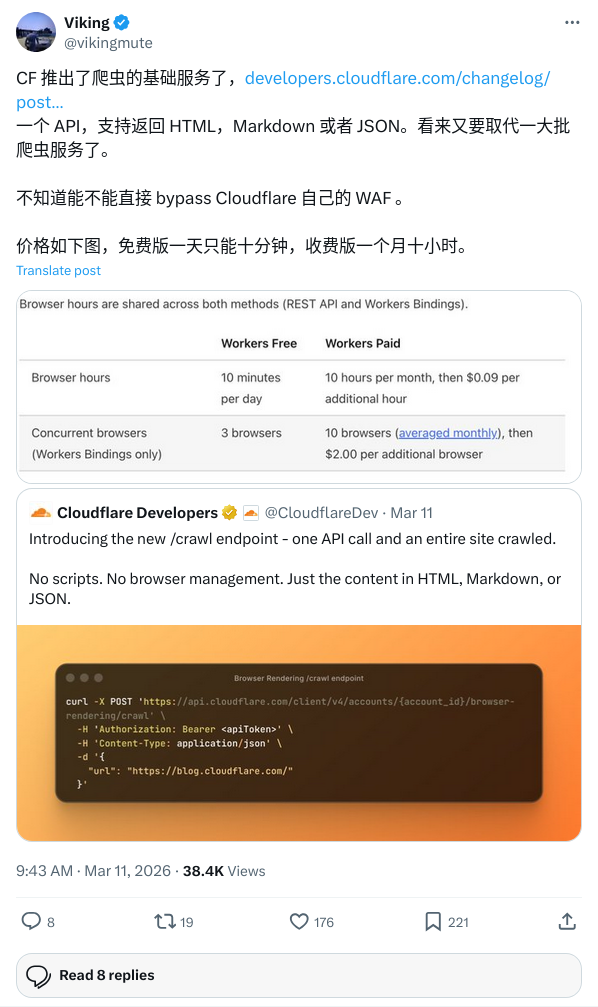
During Beta testing, as long as you don't turn on JavaScript rendering (render: false), the interface is completely free. Even with rendering turned on, the free version gives you 10 minutes of browser runtime per day; the paid version (starting at just $5 per month) offers a 10-hour monthly credit, with a $0.09 per hour charge for anything beyond that. Hourly billing completely reverses the traditional logic of per-request billing, and for heavy crawling needs, the cost is almost negligible.
both shield and spear
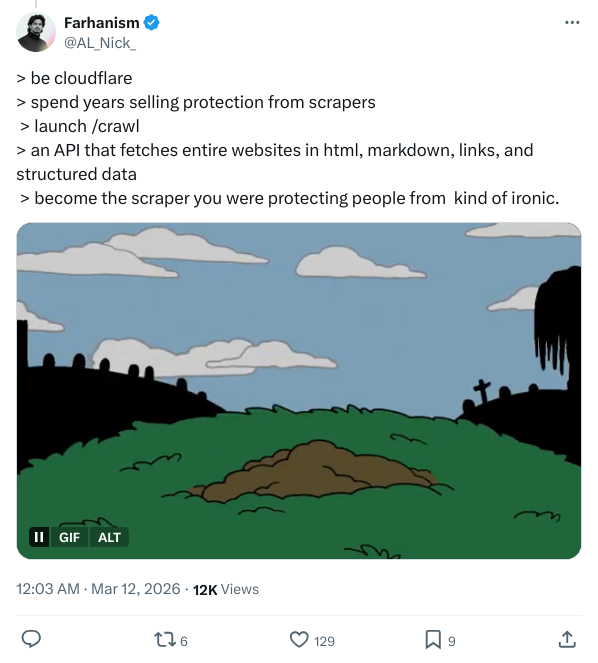
Back to the original irony. The frenzy on the social network was not without reason. x A tweet from user @AL_Nick_ hit the company's logic of doing things with precision:
be cloudflare
spend years selling protection from scrapers
launch /crawl
become the scraper you were protecting people from
The accompanying image is the classic line from Batman: “Either retire with honor as a hero, or live to see yourself become a villain.”
In the face of all the flak on the net, Cloudflare officials gave a very clever defense in the comments section: they believe that the root cause of the violent crawlers flooding the Internet today is that “the development cost of doing a polite crawler is too high”. So they provide an official API that adheres to robots.txt by default, controls the frequency of concurrency so as not to overwhelm the target server, and uses a standardized User-Agent.
That's a logical argument, but it doesn't hide its business savvy. The reality is on the table: organizations that have paid for Cloudflare's advanced WAF have defenses that can stop Cloudflare's own /crawl Request?
A developer in the Chinese community, @chuhaiqu, hit the nail on the head when he said, “Before: charge money to help you block crawlers. Now: charge money to help you crawl others.”
This is actually the ultimate privilege of a platform-based company. By commoditizing crawling capabilities, Cloudflare further deepens developers' reliance on its Workers computing ecosystem. They don't care if you're crawling others or preventing others from crawling you. As long as the data is flowing and traffic is passing through their edge nodes, the meter is walking the word.
Hands-on: deploy your data pump in five minutes
Business ethics aside, from a developer's point of view, this tool is really too good to be true. All you need is a Cloudflare account with the Workers service enabled and an API Token with Browser Rendering permissions.
With less than 30 lines of code, you can pull off a full site-level data crawling task:
async function crawlSite(url, apiToken, accountId) {
// 1. 发起 POST 请求,创建爬取任务
const startRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl`,
{
method: 'POST',
headers: {
'Authorization': `Bearer ${apiToken}`,
'Content-Type': 'application/json'
},
// 请求输出 Markdown,对于静态内容关闭渲染以加速
body: JSON.stringify({ url, formats:['markdown'], render: false })
}
);
const { result: jobId } = await startRes.json();
// 2. 轮询 GET 请求,等待庞大的任务集群完成作业
while (true) {
const checkRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}?limit=1`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
const data = await checkRes.json();
if (data.result.status !== 'running') break;
// 礼貌的等待时间
await new Promise(r => setTimeout(r, 3000));
}
// 3. 任务结束,提取洗净后的数据
const finalRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
return (await finalRes.json()).result.records;
}
They even went along with the release of the companion MCP Server, which means that you can use the Cursor or Claude AI IDEs like this call the system directly through natural language. What data you need, the AI will automatically call this minimalist API to grab it back.
The old barriers are crumbling and the marginal cost of data access is converging infinitely closer to zero. This is absolutely bad news for the defenders of open content on the Internet.





































