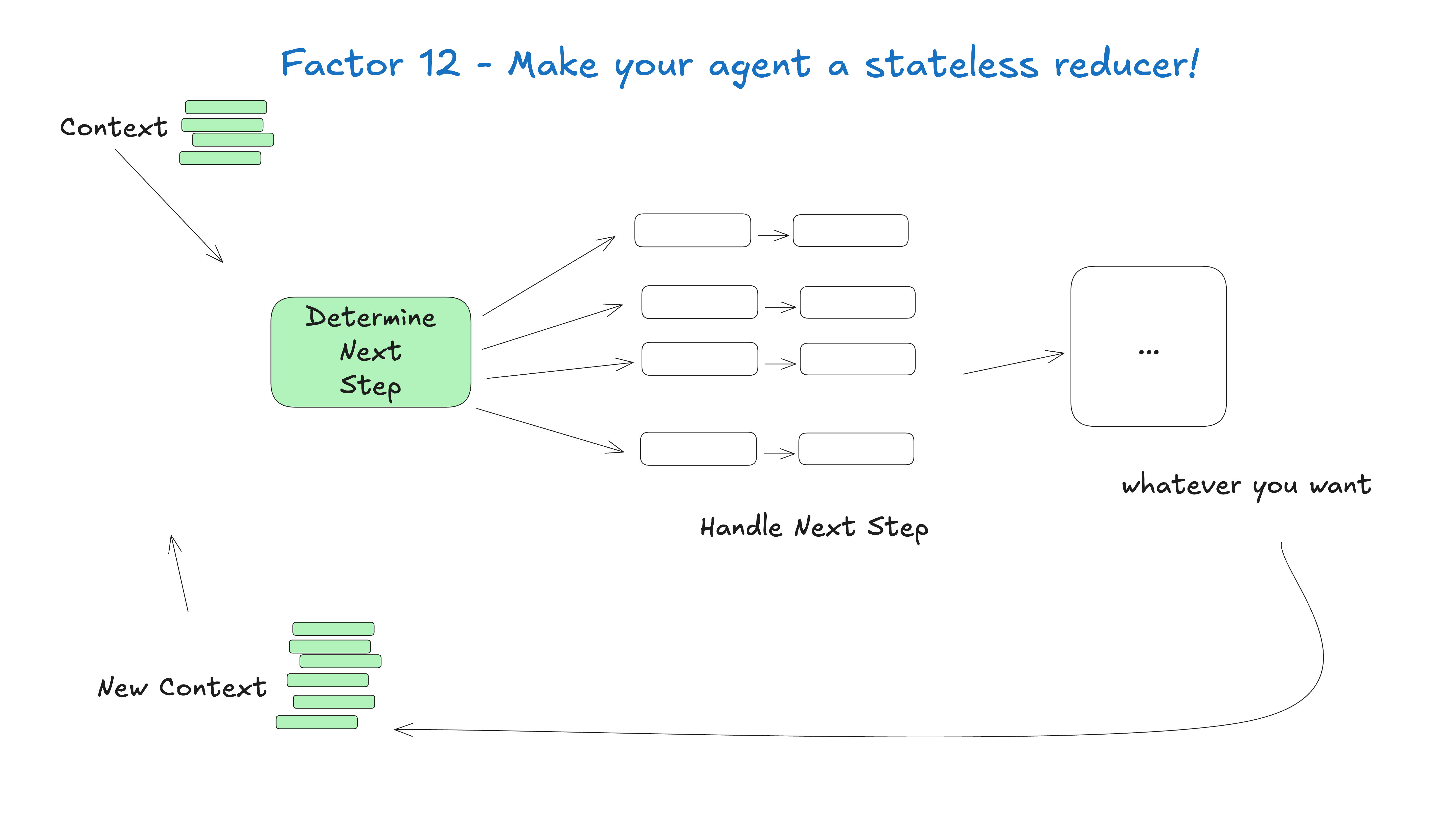
If you are in control of your own control flow, you can implement many interesting features.

Build custom control structures that fit your particular use case. Specifically, certain types of tool calls might be a reason to jump out of a loop, wait for a human to respond, or wait for another long-running task (e.g., a training pipeline). You may also want to integrate custom implementations of the following features:
- Summary or cache of tool call results
- LLM-as-judge (Large Language Model as Judge) for structured outputs
- Context window compression or other memory management
- Logging, tracking and metrics
- Client-side rate limiting
- Persistent Hibernation / Suspend / "Wait for Event"
The following example shows three possible control flow patterns:
- request_clarification: model requests more information, breaks the loop and waits for a human response
- fetch_git_tags: the model requests a list of git tags, fetches the tags, attaches them to the context window, and passes them directly back to the model
- deploy_backend: the model requests to deploy the backend, which is a high-risk thing to do, so breaks the loop and waits for human approval
def handle_next_step(thread: Thread):
while True:
next_step = await determine_next_step(thread_to_prompt(thread))
# 为清晰起见,此处为内联代码 - 实际上你可以把它
# 放在一个方法里,使用异常来控制流程,或任何你喜欢的方式
if next_step.intent == 'request_clarification':
thread.events.append({
type: 'request_clarification',
data: nextStep,
})
await send_message_to_human(next_step)
await db.save_thread(thread)
# 异步步骤 - 中断循环,我们稍后会收到一个 webhook
break
elif next_step.intent == 'fetch_open_issues':
thread.events.append({
type: 'fetch_open_issues',
data: next_step,
})
issues = await linear_client.issues()
thread.events.append({
type: 'fetch_open_issues_result',
data: issues,
})
# 同步步骤 - 将新的上下文传递给 LLM 以确定下一步的行动
continue
elif next_step.intent == 'create_issue':
thread.events.append({
type: 'create_issue',
data: next_step,
})
await request_human_approval(next_step)
await db.save_thread(thread)
# 异步步骤 - 中断循环,我们稍后会收到一个 webhook
break
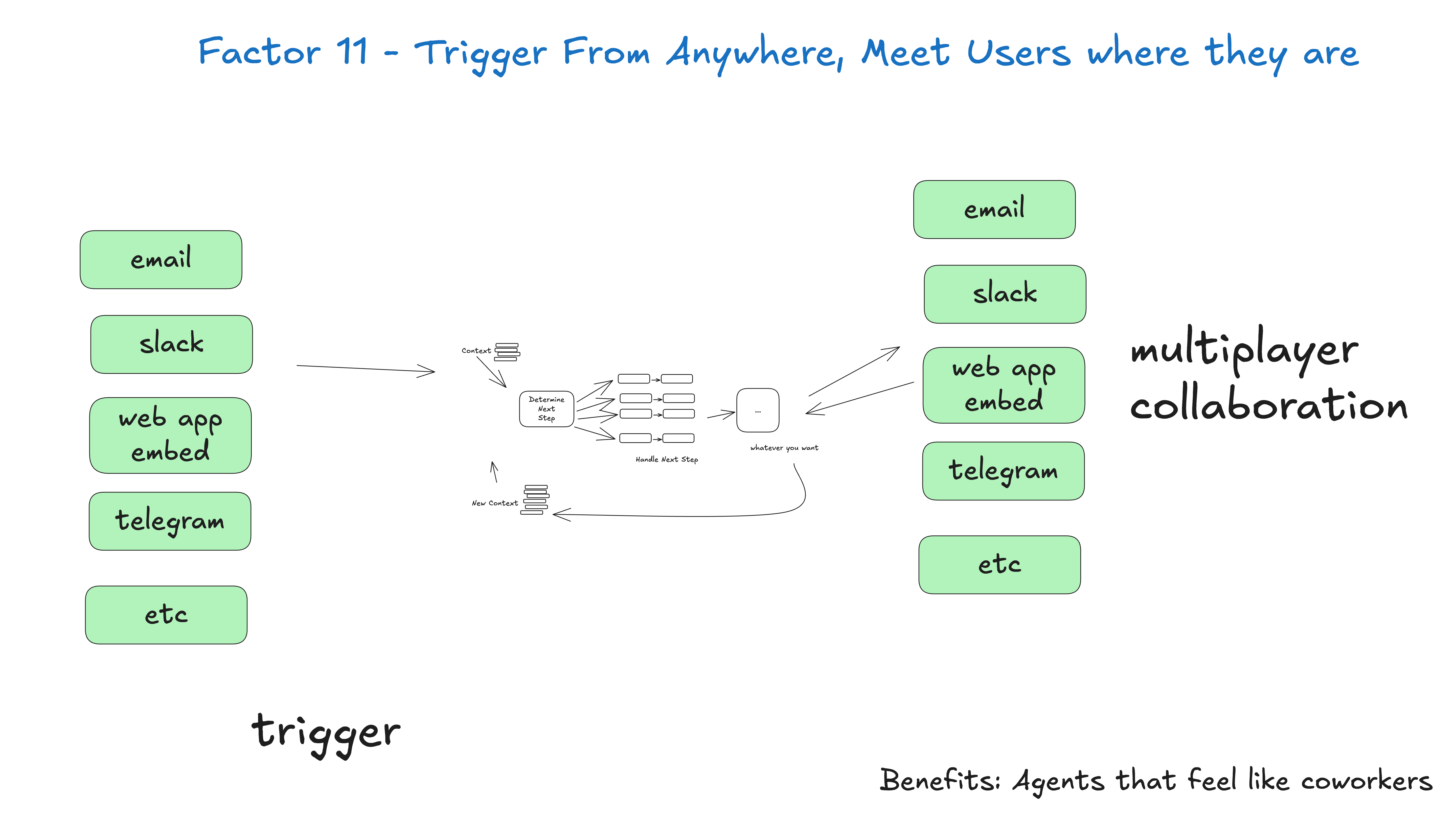
This mode allows you to interrupt and resume the flow of intelligences as needed to create more natural conversations and workflows.
typical example - For every AI framework on the market, the feature I would most like to see is the ability to interrupt a working intelligence and resume it later, especially in tools option and tools invocations Between these two moments.
Without this level of recoverability/granularity, there is no way to review/approve tool calls before they are run, which means you have to choose one of the following:
- Suspend tasks in memory while waiting for long-running tasks to finish (like the
while...sleep), if the process is interrupted, it must be restarted from scratch - Limit intelligences' permissions to only low-risk, low-importance calls such as research and abstracts
- Give the intelligence the authority to perform more important and useful tasks, and then count on luck (yolo) that it doesn't get it wrong.
You may notice that this is not the same as Element 5 - Harmonize Implementation Status with Business Status 和 Element 6 - Start/Suspend/Resume with a Simple API Closely related, but can be realized independently.